 srcmini
srcmini先决条件-正则表达式,正则语法和正则语言,抽取引理
根据鸽子洞原理,有一个确定语言是否规则的定理,称为泵送引理。但抽水引理是一个负性检验,即如果一种语言不满足抽水引理,那么我们可以肯定地说它不是规则的,但如果它满足,那么语言可能是规则的,也可能不是规则的。抽运引理更多的是一种数学证明,需要更多的时间,有时可能会令人困惑。在考试中,我们需要快速解决这个问题,所以基于常见的观察和分析,以下是一些快速的规则会有所帮助:
每个有限集代表一种常规语言。
示例1 –{a, b} *上所有长度= 2的字符串, 即L = {aa, ab, ba, bb}是规则的。
给定一种非常规语言的表达式, 但是参数的值受某个常数的限制, 则该语言是常规的(意味着它具有某种有限的比较)。
示例2 –L = {
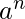
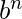
| n <= 10
10
10
}是常规的
因为它是上限语言, 因此是一种有限的语言。
字符串的形式形成A.P.(算术级数)是规则的(即, 幂是线性表达式的形式),
但是具有G.P.(Geometric Progression)的模式是不规则的(即其功效是以非线性表达的形式), 并且属于上下文敏感语言类。
示例3 –
L = {
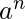
| n> = 2}是常规的。显然, 它形成了一个A.P., 因此我们可以绘制一个具有3个状态的有限自动机。
示例4 –
L = {a
2
ñ
| n> = 1}不正常。它形成一个G.P., 所以我们不能有一个固定的模式, 重复该模式会生成该语言的所有字符串。
在示例4中, 如果’n’的边界像n <10000, 则它变得有规则, 因为它是有限的。
不存在任何模式, 可以重复使用该模式来生成语言中的所有字符串是不规则的。使用FA无法找到素数本身。
示例5 –
L = {
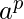
| p是素数。 }不是常规的。
模式(常规)和非模式(非常规)的串联也不是常规语言。
示例6 –
大号
1
= {
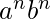
| n≥1}, L
2
= {
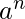
n≥1}然后L
1
.L
2
不正常。
每当需要无限制的存储来存储计数然后与其他无限制的计数进行比较时, 该语言都是不规则的。
示例7 –
L = {
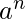
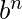
| n> = 1}是不规则的, 因为我们需要先存储a的数量, 然后将其与b的数量进行比较, 但是有限自动机的存储空间有限, 但是在L中, 可以有无数个a进入, 无法存储。
示例8 –L = {w | na(w)= nb(w)}不规则。
示例9 –L = {w | na(w)%3> nb(w)%3}是有规律的, 因为模运算需要有界存储, 即, 对于%3操作, 模数只能是0、1或2, 然后对于b同样, 模数可以是0、1和2.因此, DFA中表示的状态将是a和b其余部分的所有组合。
的模式
W, W
[R
和
X
,
ÿ
If
| x |
一定长度, 然后不规则。
示例10 –
L = {宽x宽
[R
| W, x属于{a, b} *, | x | = 5}不规则。如果W = abb, 则W
[R
= bba和x = aab, 因此组合字符串为abb aab bba。现在, 可以扩展x以吞噬W和W
[R
, 但| x | =5。因此, 即使在扩展字符串中, W = ab, Wr = ba和x = baabb。因此, 我们没有任何形式(a + b)*的模式, 因此不是常规模式。
如果| x |是无界的并且W属于(a + b)*, 然后将W表示为epsilon, 将W ^ r表示为epsilon, 如果得到的结果是(a + b)*, 则该语言是正规的。
示例11 –
L = {宽x宽
[R
| W, x属于{a, b} *}是规则的。
如果W = abb, 则W
[R
= bba且X = aab, 因此组合字符串为abb aab bba。现在, 可以扩展x以吞噬W和W
[R
。因此, 在扩展字符串中, W = epsilon, W
[R
=ε和X = abb aab bba。我们得到(a + b)*形式的简单模式, 可以为其绘制有限自动机。
如果| x |是无界的, W属于(a + b)
+
, 然后将W作为字母和对应W中的任何符号
[R
, 如果仍然可以得到(a + b)*的某种组合, 并保证所有字符串的格式相同, 则该语言是常规的, 否则不是常规的。这需要通过示例进行更多说明:
示例12 –
L = {宽x宽
[R
| W, x属于{a, b} +}是规则的。
如果W = abb, 则W
[R
= bba和x = aab, 因此组合字符串为abbaabbba。现在, 可以扩展X来吃掉W和W
[R
, 留下一个符号a或b。在扩展字符串中, 如果W = a, 则W
[R
= a, 如果W = b, 则W
[R
= b。在上面的示例中, W
[R
= a。 x = bbaabbb。它减少到以相同符号a(a + b)* a或b(a + b)* b开头和结尾的模式字符串, 可以为其绘制有限自动机。
示例13 –
L = {W W
[R
Y | W, y属于{0, 1} +}是不规则的。
如果W = 101, 则W
[R
= 101且Y = 0111, 则字符串为1011010111。如果扩展y, 则W = 1, W
[R
= 0且y = 11010111。根据这种扩展, 字符串不属于语言本身, 这是错误的, 因此不规则。
如果W = 110, 则W[R= 011和Y = 0111, 则字符串为1100110111。如果扩展y, 则W = 1, Wr = 1和Y = 00110111。该字符串满足语言要求, 但是我们不能以此为依据进行概括, 因为字符串也可能以01和10开头。
示例14 –
L = {x W
[R
y | x, y, W属于{a, b}
+
}是常规的。
如果X = aaaba, 则W = ab, Y = aab。字符串是aaaba abbaaab。现在, 可以将x和y展开为W和W
[R
被吃掉, 但为+留一个符号, 即新值是X = aaabaa W = b, W
[R
= b。因此, 该语言被简化为所有包含” bb”或” aa”作为子字符串的字符串的集合, 这是常规的。
评论前必须登录!
注册