 srcmini
srcmini数据预处理是一个笼统的术语, 涵盖了一系列操作, 数据科学家将使用这些操作将其数据转换为更适合他们要使用的数据的形式。例如, 在对Twitter数据进行情感分析之前, 你可能希望删除所有html标签, 空白, 扩展缩写并将推文拆分为包含它们的单词的列表。在分析空间数据时, 你可以对其进行缩放, 使其与单位无关, 也就是说, 你的算法无需关心原始测量值是英里还是厘米。但是, 预处理数据不会在真空中发生。这只是说预处理是达到目的的一种手段, 没有硬性规定和快速规则:正如我们将要看到的那样, 有一些标准实践, 你可以对可行的方法形成直觉, 但最终, 预处理是通常, 它是结果导向管道的一部分, 其性能需要根据上下文进行判断。
在本文中, 我将使用缩放数字数据的示例(数字数据:由数字组成的数据, 而不是类别/字符串;缩放:使用基本算术来更改数据的范围;更多详细信息)考虑将预处理作为更大的结构(机器学习(ML)管道)的一部分的重要性。为此, 我们将看到一个实际示例, 其中缩放可以改善模型性能。
我将首先介绍ML和k最近邻(在此类设置中使用的最简单算法之一)中的分类问题。要了解在这种情况下缩放数字数据的重要性, 我需要介绍模型性能的度量以及训练和测试集的概念。你将看到所有这些概念和实践, 以及一个试图对红酒质量进行分类的数据集。我还要确保将预处理放在最有用的位置, 靠近迭代数据科学管道的开始。本文中的所有示例都将使用Python。如果你不熟悉Python, 可以在这里查看我们的srcmini课程。我将使用熊猫库满足我们的数据框架需求, 并使用scikit-learn满足我们的机器学习需求。
机器学习中的分类问题简介
对现象世界中的事物进行分类和标记是一门古老的艺术。在公元前4世纪, 亚里斯多德建立了一个生物分类系统, 该系统使用了2000年。在现代世界中, 分类通常被定义为机器学习任务, 特别是监督学习任务。监督学习的基本原理很简单:我们拥有一堆由预测变量和目标变量组成的数据。监督学习的目的是建立一个能够在给定预测变量的情况下”善于”预测目标变量的模型。如果目标变量由类别组成(例如”点击”或”非”, “恶性”或”良性”肿瘤), 我们将其称为学习任务分类。或者, 如果目标是连续变化的变量(例如房屋价格), 则这是回归任务。
一个说明性的例子在这里可以走很长一段路:考虑心脏病数据集, 其中有75个预测变量, 例如”年龄”, “性别”和”是否吸烟”, 目标变量是指心脏病的存在范围从0(无心脏病)到4。此数据集上的许多工作都集中于尝试区分心脏病的存在与否。这是分类任务。如果要尝试预测目标变量的实际值(0到4), 这将是一个回归问题(因为目标变量已排序)。我将在下一篇文章中讨论回归。在这里, 我将介绍用于分类任务的最简单算法之一, 即k最近邻居算法。
机器学习中用于分类的k最近邻
假设我们有一些标记数据, 例如, 包含红酒特征(例如酒精含量, 密度, 柠檬酸含量, pH等)的数据;这些是预测变量, 其目标变量为”质量” “, 并标记”好”和”坏”。然后, 根据未贴标签的新酒的特性, 分类任务是预测其”品质”。当所有预测变量都是数值形式时(也有多种方法可以处理分类情况), 我们可以将每行/酒作为n维空间中的一个点, 在这种情况下, 可以认为是k个最近邻居(k-NN)这是一种概念上和计算上简单的分类方法:对于每种新的, 未标记的葡萄酒, 我们为某个整数k计算其在n维预测变量空间中的k个最近邻居。然后, 我们查看这k个邻居的标签(即”好”或”坏”)并为新酒分配命中率最高的标签(例如, 如果k = 5, 则3个邻居对”好”票和2票对”差”票) ‘, 然后我们的模型将新酒标记为”好”)。请注意, 这里训练模型完全在于存储数据点:没有适合的参数!
k最近邻居的视觉描述
在下图中, 有一个2D的k-NN示例:如何对中间的数据点进行分类?好吧, 如果k = 3, 则将其分类为红色, 如果k = 5, 则分类为绿色。

Python中的k-NN实现(scikit-learn)
现在让我们来看一个工作中的k-NN示例。为此, 我们将检查葡萄酒质量数据集:将其导入到pandas数据框中, 然后绘制预测变量的直方图以了解数据。
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('ggplot')
df = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv ' , sep = ';')
X = df.drop('quality' , 1).values # drop target variable
y1 = df['quality'].values
pd.DataFrame.hist(df, figsize = [15, 15]);
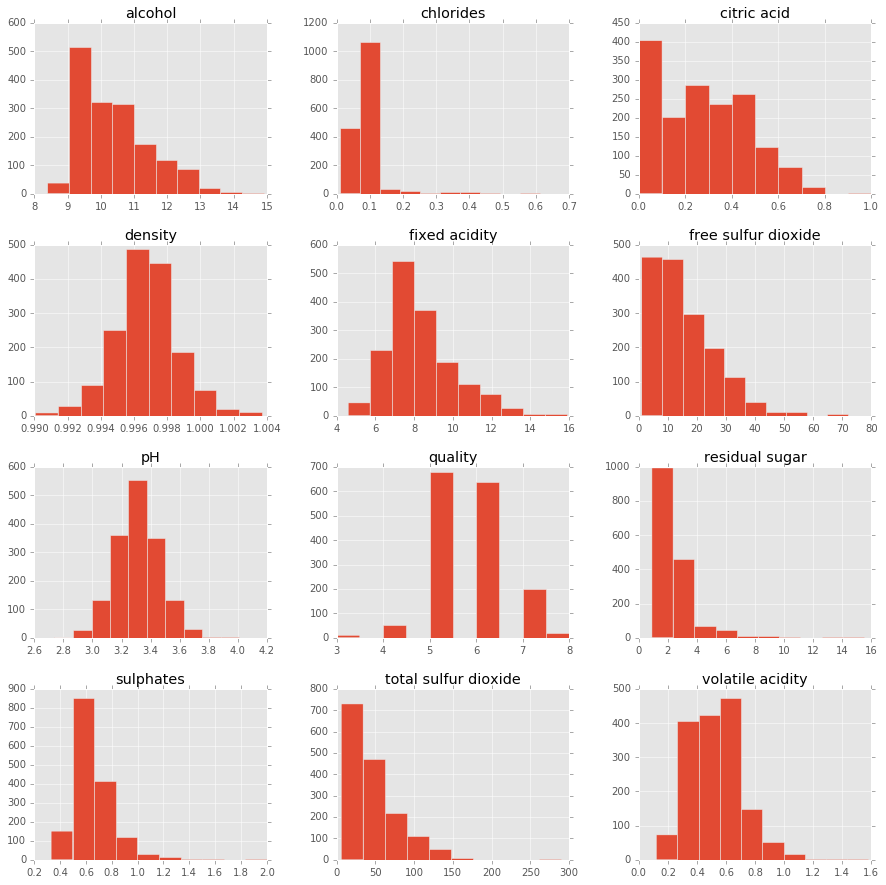
首先注意预测变量的范围:”游离二氧化硫”的范围是0到〜70, “挥发性酸度”的范围是〜0到〜1.2。更具体地说, 前者的范围比后者大2个数量级。因此, 任何关心数据点之间距离的算法(例如k-NN)都可能会公平地, 不公平地集中于较大范围的变量, 例如”游离二氧化硫”(可能仅包含噪声的变量)知道。这会激励扩展我们的数据, 我们将尽快进行扩展。
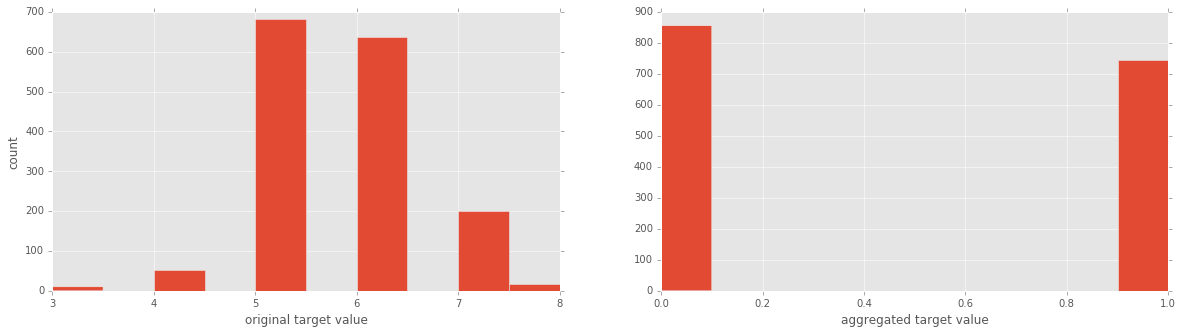
现在目标变量是葡萄酒的”质量”等级, 范围从3到8。为了便于说明, 让我们将其转换为两类变量, 包括”好”(等级> 5)和”差”(评分<= 5)。我们还将绘制目标变量的两种公式的直方图, 以了解发生了什么。
y = y1 <= 5 # is the rating <= 5?
# plot histograms of original target variable
# and aggregated target variable
plt.figure(figsize=(20, 5));
plt.subplot(1, 2, 1 );
plt.hist(y1);
plt.xlabel('original target value')
plt.ylabel('count')
plt.subplot(1, 2, 2);
plt.hist(y)
plt.xlabel('aggregated target value')
plt.show()
现在, 我们几乎可以执行k最近邻了。不过, 首先, 如果我们要比较模型在进行预处理和不进行预处理的情况下的性能, 则需要弄清楚如何衡量模型的”良好性”:
k最近邻居:效果如何?
有很多针对分类挑战的性能指标。最重要的是要意识到绩效指标的选择是针对特定领域和特定问题的。对于具有平衡类的数据集(所有目标值均〜表示), 数据科学家通常将准确性视为一种绩效指标。实际上, 正如我们将看到的那样, 准确性是k-最近邻居和scikit-learn中逻辑回归的默认评分方法。那么什么是准确性?它仅是正确预测数除以预测总数:
$$ \ text {准确度} = \ frac {\ text {正确的预测数}} {\ text {预测的总数}}。$$
注意:精度也可以根据混淆矩阵来定义, 并且通常针对二进制分类问题按照真肯定和假否定来定义;从混淆矩阵中得出的模型性能的其他常见度量是精度, 真实阳性数除以真实与假阳性数, 以及召回率, 真实阳性数除以真实阳性数再加上错误阴性数; F1分数是精度和查全率的谐波均值。有关这些措施的详细说明, 请参见机器学习精通。还可以检查混淆矩阵和F1分数上的Wikipedia条目。
k最近邻居:实践中的表现和火车测试拆分
衡量性能(如准确性)是一件好事, 但是, 如果我们将模型拟合到我们拥有的所有数据上, 我们将从哪个数据集中报告准确性?请记住, 我们需要一个能够很好地概括新数据的模型。因此, 如果我们在数据集D上训练模型, 则在相同数据D上报告模型的准确性可能会使模型看起来比实际效果更好。这称为过度拟合。为了解决这个问题, 数据科学家通常会在称为训练集的数据子集上训练模型, 并在其余数据(测试集)上评估其性能。这正是我们在这里要做的!一般的经验法则是将大约80%的数据用于训练, 将20%的数据用于测试。现在让我们分割我们的红酒质量数据:
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
现在, 我们建立k-NN模型, 在测试集上进行预测, 并将这些预测与基本事实进行比较, 以衡量模型的性能:
from sklearn import neighbors, linear_model
knn = neighbors.KNeighborsClassifier(n_neighbors = 5)
knn_model_1 = knn.fit(X_train, y_train)
print('k-NN accuracy for test set: %f' % knn_model_1.score(X_test, y_test))
k-NN accuracy for test set: 0.612500
值得重申的是, 在scikit-learn中, k-NN的默认评分方法是准确性。 61%的精度并不高, 但是对于没有任何预处理的即装即用模型来说, 也不是很恐怖。要查看各种其他指标, 我们还可以使用scikit-learn的分类报告:
from sklearn.metrics import classification_report
y_true, y_pred = y_test, knn_model_1.predict(X_test)
print(classification_report(y_true, y_pred))
precision recall f1-score support
False 0.66 0.64 0.65 179
True 0.56 0.57 0.57 141
avg / total 0.61 0.61 0.61 320
现在, 我们将介绍缩放和居中, 这是预处理数值数据的最基本方法, 并查看它们是否以及如何影响我们的模型性能。
预处理机制:缩放和居中
在对数据运行模型(例如回归(预测连续变量)或分类(预测离散变量))之前, 几乎总是需要进行一些预处理。对于数字变量, 通常对数据进行标准化或标准化。这些术语是什么意思?
所有归一化方法均按比例缩放数据集, 以使其最小值为0且最大值为1。为此, 我们将每个数据点$ x $转换为
$$ x_ {normalized} = \ frac {x-x_ {min}} {x_ {max} -x_ {min}}。$$
标配标准略有不同。它的工作是将数据围绕0居中并相对于标准偏差进行缩放:
$$ x_ {standardized} = \ frac {x- \ mu} {\ sigma}, $$
其中$ \ mu $和$ \ sigma $分别是数据集的平均值和标准偏差。首先请注意, 这些转换仅更改数据范围, 而不更改分布。稍后你可能希望使用任何其他数量的变换, 例如对数变换或Box-Cox变换, 以使数据看起来更像是高斯曲线(如钟形曲线)。但是在进一步研究之前, 重要的是要问以下问题:为什么我们要扩展数据?有没有比其他时代更合适的时代了?例如, 分类问题比回归问题重要吗?
首先, 让我们深入研究分类挑战, 看看缩放如何影响k最近邻居的性能:
预处理:实际扩展
在这里, 我(i)缩放数据, (ii)使用k最近邻居, (iii)检查模型性能。我将使用scikit-learn的scale函数, 该函数将传递给它的数组中的所有功能(列)标准化。
from sklearn.preprocessing import scale
Xs = scale(X)
from sklearn.cross_validation import train_test_split
Xs_train, Xs_test, y_train, y_test = train_test_split(Xs, y, test_size=0.2, random_state=42)
knn_model_2 = knn.fit(Xs_train, y_train)
print('k-NN score for test set: %f' % knn_model_2.score(Xs_test, y_test))
print('k-NN score for training set: %f' % knn_model_2.score(Xs_train, y_train))
y_true, y_pred = y_test, knn_model_2.predict(Xs_test)
print(classification_report(y_true, y_pred))
k-NN score for test set: 0.712500
k-NN score for training set: 0.814699
precision recall f1-score support
False 0.72 0.79 0.75 179
True 0.70 0.62 0.65 141
avg / total 0.71 0.71 0.71 320
所有这些措施均提高了0.1, 这是16%的显着提高!正如上面所暗示的, 在缩放之前, 存在许多具有不同数量级范围的预测变量, 这意味着其中一个或两个可以在诸如k-NN之类的算法中占主导地位。扩展数据的两个主要原因是
- 你的预测变量可能具有明显不同的范围, 并且在某些情况下(例如在实现k-NN时), 需要加以缓解, 以使某些特征不会主导算法;
- 你希望要素独立于单位, 也就是说, 不依赖于所涉及的测量范围:例如, 你可以以米为单位表示被测要素, 而我可以以厘米为单位表示相同要素。如果我们都按比例缩放各自的数据, 则每个人的此功能都将相同。
我们已经看到了预处理在数据科学流水线中以其缩放和居中的形式占据着必不可少的位置, 我们这样做是为了促进采用整体方法应对机器学习的挑战。我希望在以后的文章中将讨论扩展到其他类型的预处理, 例如数值数据的转换和分类数据的预处理, 这都是任何数据科学家工具包的基本方面。在继续之前, 在下一篇文章中, 我将探讨缩放在分类的回归方法中的作用。特别是, 我将研究逻辑回归, 你会发现结果与你在k最近邻居中看到的结果非常不同。
在下面的交互式窗口中, 你可以自己玩数据。首先更改变量n_neig, 该变量为k-NN算法中要使用的邻居数。如果需要, 还可以通过设置sc = True来缩放数据。然后, 运行整个脚本以报告模型的准确性以及分类报告。
有监督的学习:从预测变量中推断目标变量的任务。例如, 从预测变量(例如”年龄”, “性”和”吸烟状态”)推断目标变量”心脏病的存在”。
分类任务:如果目标变量由类别(例如”点击”或”非”, “恶性”或”良性”肿瘤)组成, 则监督学习任务就是分类任务。
回归任务:如果目标变量是连续变化的变量(例如房屋价格)或有序的分类变量(例如”葡萄酒质量等级”), 则监督学习任务就是回归任务。
k最近邻居:一种用于分类任务的算法, 其中为数据点分配由其k个最近邻居的多数票决定的标签。
预处理:科学家将使用任意数量的操作数据将其数据转换成更适合他们想要处理的形式。例如, 在对Twitter数据进行情感分析之前, 你可能希望删除所有html标签, 空白, 扩展缩写并将推文拆分为包含它们的单词的列表。
居中和缩放:这两种都是预处理数值数据的形式, 例如, 由数字组成的数据, 而不是类别或字符串。以变量居中表示从每个数据点减去变量的平均值, 以便新变量的平均值为0;缩放变量是将每个数据点乘以一个常数, 以更改数据范围。有关这些重要性的重要性, 请参见本文的正文以及示例。
本文来自Jupyter笔记本。你可以在此处下载笔记本。
评论前必须登录!
注册