 srcmini
srcmini本文概述
让我们开始构建可以在系统启动时运行的python脚本, 以阻止对特定网站的访问。打开PyCharm编辑代码, 或者你可以使用任何所需的IDE。
创建一个名为web-blocker.py的新Python脚本。为了使你可以理解该过程, 我们将逐步构建此脚本。因此, 让我们开始通过设置所有必需的变量进行编码。
设置变量
此步骤将初始化脚本中将使用的所有必需变量。在这里, host_path设置为hosts文件的路径。在我们的例子中, 它位于/ etc下。在python中, r用于表示原始字符串。
重定向已分配给本地主机地址, 即127.0.0.1。网站是一个列表, 其中包含要阻止的网站列表。
host_path = r"/etc/hosts"
redirect = "127.0.0.1"
websites = ["www.facebook.com", "https://www.facebook.com"]设置无限循环
我们需要在python脚本中有一个while循环, 以确保我们的脚本每5秒运行一次。
为了实现这一点, 我们将使用时间模块的sleep()方法。
import time
host_path = r"/etc/hosts"
redirect = "127.0.0.1"
websites = ["www.facebook.com", "https://www.facebook.com"]
while True:
time.sleep(5)确定时间
在构建所需的python脚本的过程中, 我们需要检查当前时间是工作时间还是娱乐时间, 因为该应用程序将在工作时间阻止网站访问。
要检查当前时间, 我们将使用datetime模块。我们将检查datetime.now()是否大于当前日期上午9点的datetime对象, 并且小于当前日期下午5点的datetime对象。
让我们进一步讨论datetime.now()的输出。
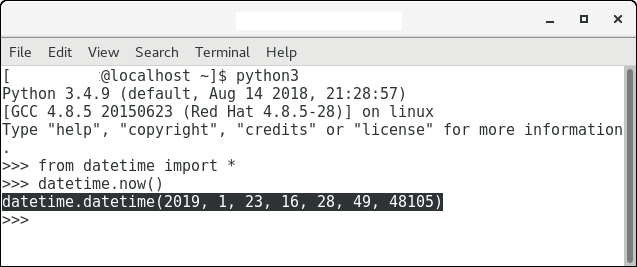
它返回一个日期时间对象, 其中包含当前时间, 包括年(2019), 月(1月1日), 日期(23rd), 时间(小时, 分钟, 秒)。我们可以比较该值, 并使用if语句检查当前日期的上午9点和当前日期的下午5点之间是否存在该值。
该脚本现在将包含以下代码。
from time import *
from datetime import *
host_path = r"/etc/hosts"
redirect = "127.0.0.1"
websites = ["www.facebook.com", "https://www.facebook.com"]
while True:
if datetime(datetime.now().year, datetime.now().month, datetime.now().day, 9)< datetime.now()< datetime(datetime.now().year, datetime.now().month, datetime.now().day, 17):
print("Working hours")
else:
print("Fun hours")
sleep(5)写入主机文件
脚本的主要目的是保持定期修改主机文件。为了让脚本配置主机文件, 我们需要在此处实现文件处理方法。
以下代码已添加到主机文件。
with open(host_path, "r+") as fileptr:
content = fileptr.read()
for website in websites:
if website in content:
pass
else:
fileptr.write(redirect+"
"+website+"\n")open()方法以r +模式打开存储为host_path的文件。首先, 我们使用read()方法读取文件的所有内容, 并将其存储到名为content的变量中。
for循环遍历网站列表, 我们将检查列表中的每个项目是否已经存在于内容中。
如果在hosts文件中存在内容, 则必须通过。否则, 我们必须将重定向网站映射写入hosts文件, 以便将网站主机名重定向到localhost。
主机文件现在将包含以下python代码。
from time import *
from datetime import *
host_path = r"/etc/hosts"
redirect = "127.0.0.1"
websites = ["www.facebook.com", "https://www.facebook.com"]
while True:
if datetime(datetime.now().year, datetime.now().month, datetime.now().day, 9)<datetime.now()<datetime(datetime.now().year, datetime.now().month, datetime.now().day, 17):
print("working hours")
with open(host_path, "r+") as fileptr:
content = fileptr.read()
for website in websites:
if website in content:
pass
else:
fileptr.write(redirect+" "+website+"\n")
else:
print("Fun hours")
sleep(5)现在, 让我们运行此python脚本, 并检查它是否已修改了hosts文件。
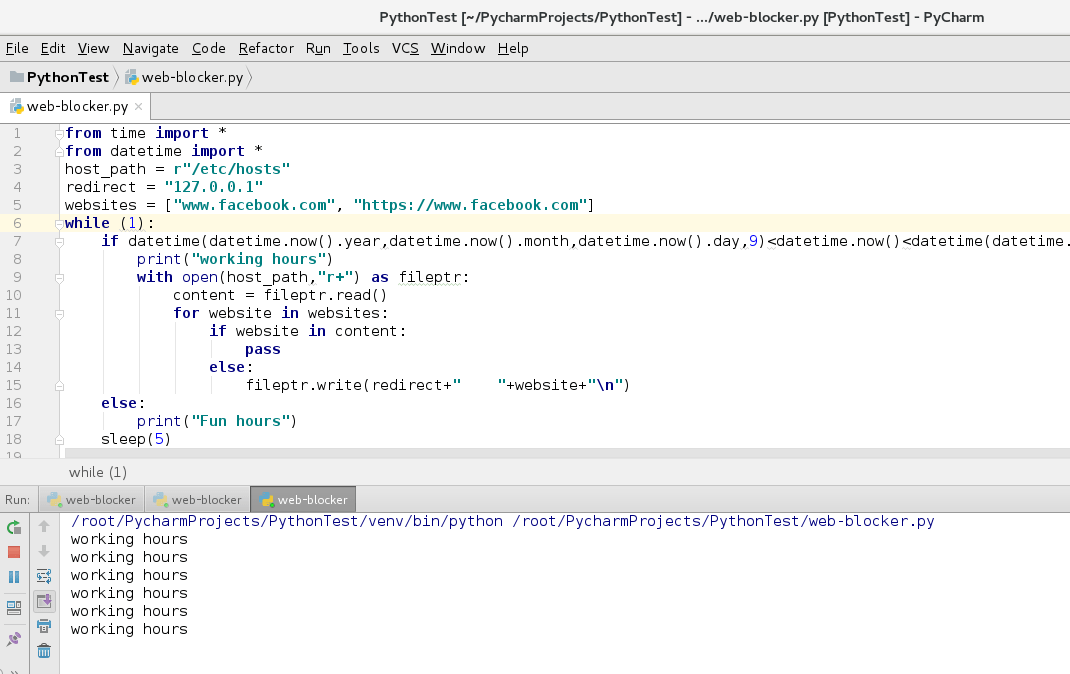
如我们所见, 它像在工作时间一样, 始终在控制台上打印工作时间。现在, 让我们检查hosts文件的内容。
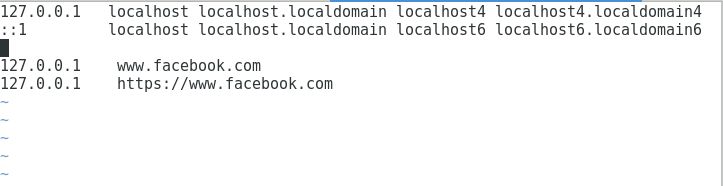
如我们所见, 这两行已添加到hosts文件中。它将把Facebook的访问重定向到本地主机。
从主机文件中删除
我们的脚本在工作时间内工作正常, 现在可以在娱乐时间添加一些功能。在娱乐时间(不是工作时间), 我们必须从主机文件中删除添加的行, 以便授予对被阻止网站的访问权限。
将以下代码添加到脚本的else部分(有趣的情况)。
with open(host_path, 'r+') as file:
content = file.readlines();
file.seek(0)
for line in content:
if not any(website in line for website in websites):
file.write(line)
file.truncate()
print("fun hours")else部分将在娱乐时间执行, 并删除所有阻止访问计算机上某些特定网站的映射。
让我们在娱乐时间检查python脚本执行时的hosts文件内容。
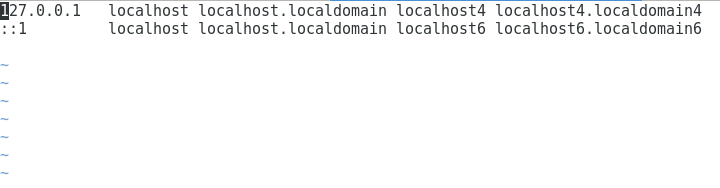
最后的剧本
现在, 我们有了一个运行良好的python脚本, 以阻止在工作时间(上午9点至下午5点)访问某些特定网站, 并在娱乐时间提供访问权限。
脚本web-blocker.py在下面给出。
web-blocker.py
from time import *
from datetime import *
host_path = r"/etc/hosts"
redirect = "127.0.0.1"
websites = ["www.facebook.com", "https://www.facebook.com"]
while True:
if datetime(datetime.now().year, datetime.now().month, datetime.now().day, 9)<datetime.now()<datetime(datetime.now().year, datetime.now().month, datetime.now().day, 17):
with open(host_path, "r+") as fileptr:
content = fileptr.read()
for website in websites:
if website in content:
pass
else:
fileptr.write(redirect+" "+website+"\n")
else:
with open(host_path, 'r+') as file:
content = file.readlines();
file.seek(0)
for line in content:
if not any(website in line for website in websites):
file.write(line)
file.truncate()
sleep(5)
评论前必须登录!
注册