 srcmini
srcminiSeries和Indexes配备了一组字符串处理方法,可以方便地对数组的每个元素进行操作。也许最重要的是,这些方法自动排除缺失/NA值。它们通过str属性访问,通常具有与等价的(标量)内置字符串方法匹配的名称。

大写和小写数据
为了使数据小写,我们使用str.lower()这个函数将所有大写字符转换为小写字符。如果不存在大写字符,则返回原始字符串。为了使数据变成大写,我们使用str.upper()这个函数将所有小写字符转换为大写字符。如果不存在小写字符,则返回原始字符串。
代码1:
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# converting and overwriting values in column
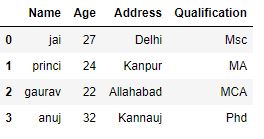
df["Name"]= df["Name"].str.lower()
print(df)输出:
如数据帧的输出图像所示, 名称列中的所有值均已转换为小写。
在这个例子中, 我们使用nba.csv文件。
代码2:
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# converting and overwriting values in column
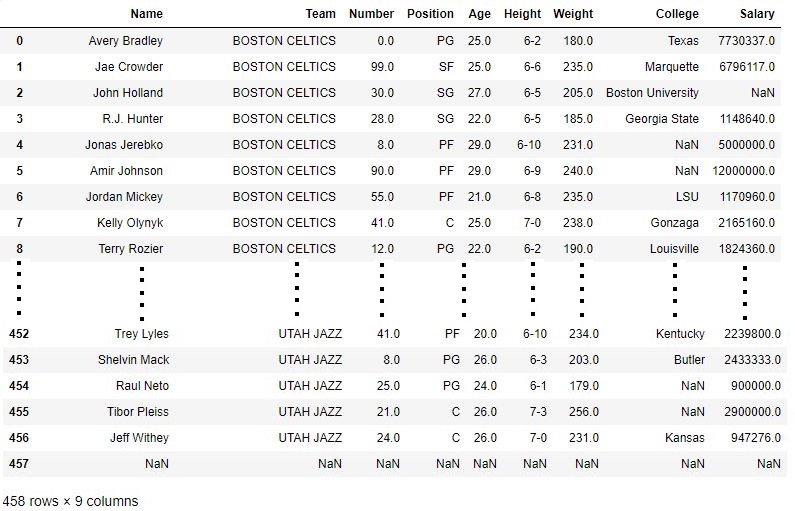
data["Team"]= data["Team"].str.upper()
# display
data输出:
如数据帧的输出图像所示, “团队”列中的所有值均已转换为大写。
拆分和替换数据
为了分割数据,我们使用str.split()这个函数在用指定的分隔符分割给定字符串后返回一个字符串列表,但它只能应用于单个字符串。Pandas str.split()方法可以应用于整个系列。每次调用此方法之前都必须添加.str前缀,以区别于Python的默认函数,否则将抛出错误。为了替换数据,我们使用str.replace()该函数的工作方式与Python .replace()方法类似,但它也适用于Series。在Pandas系列中调用.replace()之前,.str必须加上前缀,以便与Python默认的replace方法区分。
代码#1
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Knnuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# dropping null value columns to avoid errors
df.dropna(inplace = True)
# new data frame with split value columns
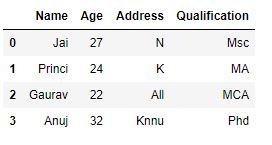
df["Address"]= df["Address"].str.split("a", n = 1, expand = True)
# df display
print(df)输出:
如输出图像中所示, 由于n参数设置为1(字符串中最大间隔为1), 所以地址列在第一次出现时” a”而不是在以后出现时被分隔。
代码2:
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("nba.csv")
# overwriting column with replaced value of age
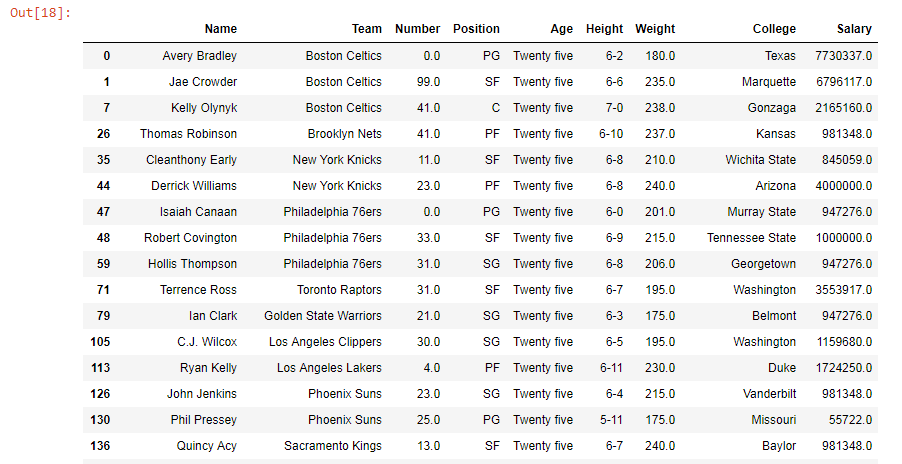
data["Age"]= data["Age"].replace(25.0, "Twenty five")
# creating a filter for age column
# where age = "Twenty five"
filter = data["Age"]=="Twenty five"
# printing only filtered columns
data.where(filter).dropna()输出:
如输出图像所示, “年龄”列中所有年龄为25.0的值已被替换为”二十五”。
数据串联
为了连接一个Series或Index,我们使用str.cat()这个函数用于将字符串连接到传递的字符串调用者序列。可以传入来自不同系列的不同值,但两个系列的长度必须相同。必须添加.str前缀,以区别于Python的默认方法。
代码1:
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# making copy of address column
new = df["Address"].copy()
# concatenating address with name column
# overwriting name column
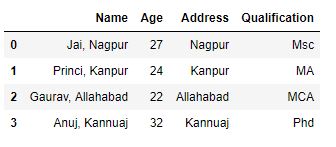
df["Name"]= df["Name"].str.cat(new, sep =", ")
# display
print(df)输出:
如输出图像所示,Address列中与Name列中的字符串具有相同索引的每个字符串都用分隔符“,”连接起来。
代码2:
# importing pandas module
import pandas as pd
# importing csv from link
data = pd.read_csv("nba.csv")
# making copy of team column
new = data["Team"].copy()
# concatenating team with name column
# overwriting name column
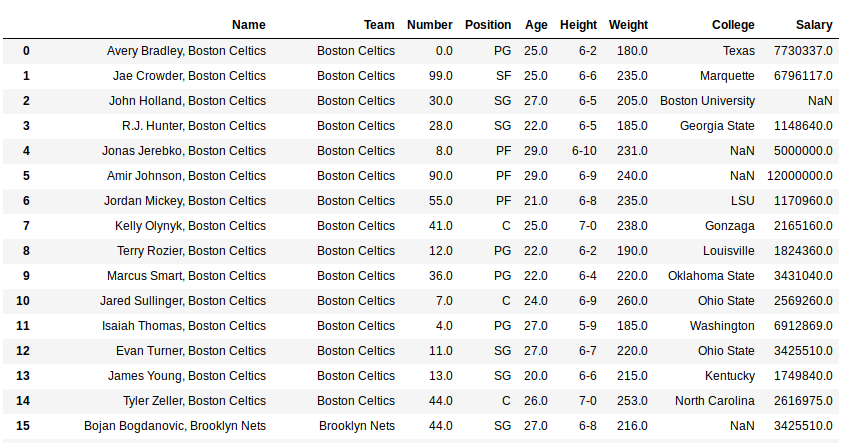
data["Name"]= data["Name"].str.cat(new, sep =", ")
# display
data输出如下:
如输出图像所示, “团队”列中与”名称”列中的索引相同的每个字符串都已用分隔符”, “连接起来。
删除数据空白
为了删除空白,我们使用str.strip(), str.rstrip(), str.lstrip()这些函数用于处理任何文本数据中的空白(包括New line)。从名称中可以看出,str.lstrip()用于删除字符串左边的空格,str.rstrip()用于删除字符串右边的空格,而str.strip()用于删除字符串两边的空格。因为这些是与Python默认函数同名的pandas函数,所以必须加上.str前缀,以告诉编译器正在调用pandas函数。
代码1:
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur junction', 'Kanpur junction', 'Nagpur junction', 'Kannuaj junction'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# replacing address name and adding spaces in start and end
new = df["Address"].replace("Nagpur junction", " Nagpur junction ").copy()
# checking with custom string
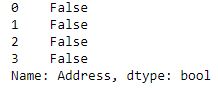
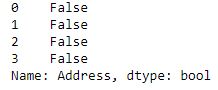
print(new.str.strip()==" Nagpur junction")
print(new.str.strip()=="Nagpur junction ")
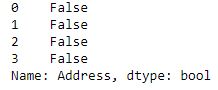
print(new.str.strip()==" Nagpur junction ")输出:
如输出图像所示, 对于所有3个条件, 比较均返回False, 这意味着空格已成功从两侧移除, 并且字符串不再具有空格。
代码2:
# importing pandas module
import pandas as pd
# making data frame
data = pd.read_csv("nba.csv")
# replacing team name and adding spaces in start and end
new = data["Team"].replace("Boston Celtics", " Boston Celtics ").copy()
# checking with custom removed space string
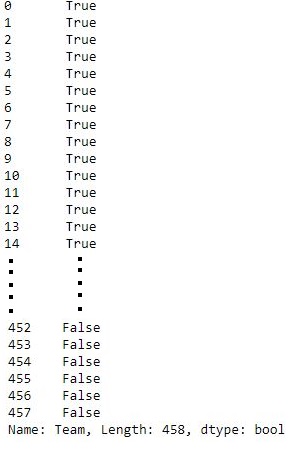
new.str.lstrip()=="Boston Celtics "输出:
如输出图像所示, 删除左侧空格后比较为真
提取数据
为了提取数据, 我们使用str.extract()这个函数接受带有至少一个捕获组的正则表达式。提取一组以上的正则表达式将返回一个DataFrame, 每组包含一列。不匹配的元素将返回用NaN填充的行。
代码1:
# importing pandas module
import pandas as pd
# creating a series
s = pd.Series(['a1', 'b2', 'c3'])
# Extracting a data
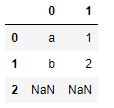
n= s.str.extract(r'([ab])(\d)')
print(n)输出:
如输出图像中所示, 这两个组将返回一个具有两列的DataFrame。不匹配项为NaN。
代码2:
# importing pandas module
import pandas as pd
# creating a series
s = pd.Series(['a1', 'b2', 'c3'])
# Extracting a data
n = s.str.extract(r'(?P<Geeks>[ab])(?P<For>\d)')
print(n)输出:
如输出图像所示, 该命名的组将成为结果中的列名。

大Pandasstr方法:
| 函数 | 描述 |
|---|---|
| str.lower() | 将字符串的字符转换为小写的方法 |
| str.upper() | 将字符串的字符转换为大写的方法 |
| str.find() | 方法用于搜索序列中存在的每个字符串中的子字符串 |
| str.rfind() | 方法用于从右侧搜索系列中存在的每个字符串中的子字符串 |
| str.findall() | 方法还用于在系列中的每个字符串中查找子字符串或分隔符 |
| str.isalpha() | 方法用于检查序列中每个字符串中的所有字符是否都是字母(a-z / A-Z) |
| str.isdecimal() | 方法用于检查字符串中的所有字符是否均为十进制 |
| str.title() | 字符串中每个单词的首字母大写的方法 |
| str.len() | 方法返回字符串中字符数的计数 |
| str.replace() | 方法用用户提供的另一个值替换字符串中的子字符串 |
| str.contains() | 方法测试模式或正则表达式是否包含在系列或索引的字符串中 |
| str.extract() | 从正则表达式模式的第一个匹配项中提取组。 |
| str.startswith() | 方法测试每个字符串元素的开头是否与模式匹配 |
| str.endswith() | 方法测试每个字符串元素的结尾是否与模式匹配 |
| str.isdigit() | 方法用于检查每个字符串序列中的所有字符是否都是数字 |
| str.lstrip() | 方法从字符串的左侧(开头)删除空格 |
| str.rstrip() | 方法从字符串的右侧(结尾)删除空格 |
| str.strip() | 从字符串中删除开头和结尾空格的方法 |
| str.split() | 方法根据用户指定的值的出现来拆分字符串值 |
| str.join() | 方法用于通过传递的定界符连接列表中存在的列表中的所有元素 |
| str.cat() | 方法用于将字符串连接到传递的调用方字符串系列。 |
| str.repeat() | 方法用于在传递的序列本身的相同位置重复字符串值 |
| str.get() | 方法用于在传递位置获取元素 |
| str.partition() | 与str.split()不同, 该方法仅在第一次出现时才拆分字符串 |
| str.rpartition() | 方法仅将字符串分割一次, 并且反向分割。它的工作方式类似于str.partition()和str.split() |
| str.pad() | 将填充(空格或其他字符)添加到系列中的每个字符串元素的方法 |
| str.swapcase() | 交换系列中每个字符串的大小写的方法 |
评论前必须登录!
注册