 srcmini
srcmini本文讨论了对聚类的介绍,建议首先理解聚类。
聚类算法有多种类型。以下概述仅列出了最重要的聚类算法示例, 因为可能有超过100种已发布的聚类算法。并非所有人都为其集群提供模型, 因此不容易对其进行分类。
基于分布的方法
它是一种聚类模型,我们将根据数据可能属于同一分布的概率来拟合数据。分组可以是正常的或高斯的。高斯分布比较突出,当我们有固定数量的分布,并且所有即将到来的数据都拟合到这个分布中,从而使数据的分布最大化。分组结果如图所示
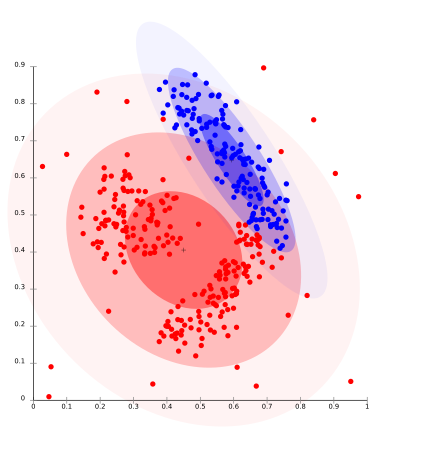
该模型适用于合成数据和不同大小的集群。但如果不使用约束来限制模型的复杂性,则该模型可能存在问题。此外,基于分布的聚类产生的聚类假设是基于数据的精确定义的数学模型,这对于某些数据分布来说是一个相当强的假设。
基于多元正态分布的期望最大化算法是该算法中比较流行的一个例子。
基于重心的方法
这基本上是一种迭代聚类算法,该算法通过数据点与聚类质心的紧密性形成聚类。这里形成了聚类中心,即质心,使数据点与中心的距离最小。这个问题基本上是一个NP困难的问题,因此解决方案通常是通过一些试验来近似的。
对于Ex- K-means算法是该算法中比较流行的一个例子
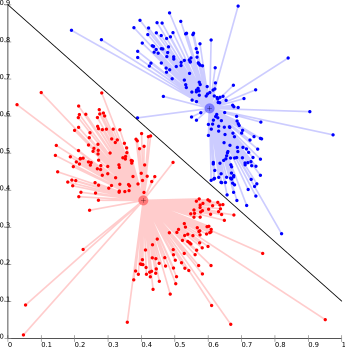
该算法的最大问题是我们需要预先指定K。在基于密度的分布聚类中也存在问题。
基于连接的方法
基于连通性的模型的核心思想类似于基于质心的模型, 该模型基本上是根据数据点的紧密度来定义聚类。在这里, 我们的工作理念是与数据点紧密相关的数据点具有相似的行为。更远。
它不是数据集的单个分区, 而是提供了以一定距离相互合并的广泛的群集层次结构。在此, 距离函数的选择是主观的。这些模型很容易解释, 但缺乏可伸缩性。
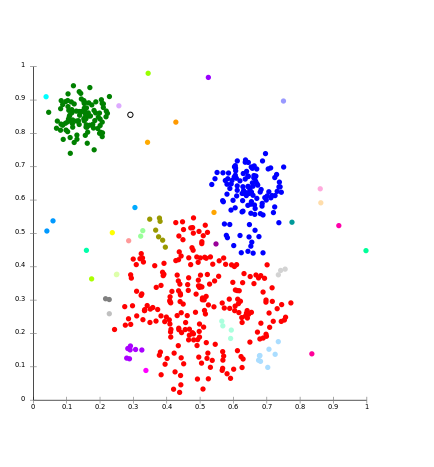
对于前层次算法及其变体。
密度模型
在此聚类模型中, 将在数据空间中搜索数据空间中数据点密度不同的区域。它根据数据空间中存在的不同密度来隔离各种密度区域。
对于前 – DBSCAN和光学.
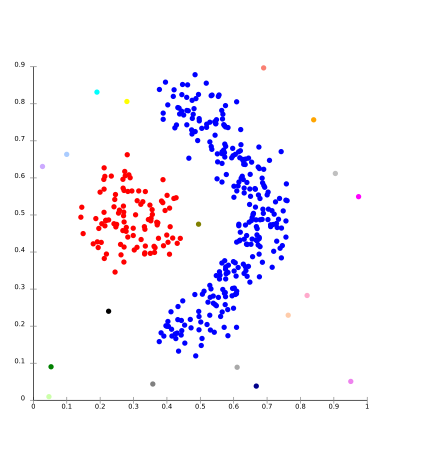
子空间聚类
子空间聚类是一个无监督的学习问题, 旨在将数据点分组为多个聚类, 以便单个聚类的数据点大致位于低维线性子空间上。子空间聚类是特征选择的扩展, 就像特征选择一样, 子空间聚类需要搜索方法和评估标准, 但此外, 子空间聚类限制了评估标准的范围。子空间聚类算法将对相关维的搜索本地化, 并允许他们找到存在于多个重叠子空间中的聚类。子空间聚类最初旨在解决非常具体的计算机视觉问题, 在数据中具有子空间结构的并集, 但是它在统计和机器学习社区中越来越受到关注。人们在社交网络, 电影推荐和生物数据集中使用此工具。子空间群集引起了对数据隐私的关注, 因为许多此类应用程序涉及处理敏感信息。假定数据点是不连续的, 它仅保护用户任何功能的差异隐私, 而不是保护数据库的整个配置文件用户。
根据子空间聚类的搜索策略, 有两个分支。
- 自上而下的算法会在整个维度集中找到一个初始聚类, 并评估每个聚类的子空间。
- 自下而上的方法在低维空间中找到密集区域, 然后合并形成簇。
参考文献:
analyticsvidhya:https://www.analyticsvidhya.com/blog/2016/11/an-introduction-to-clustering-and-different-methods-of-clustering/
knowm:https://knowm.org/introduction-to-clustering/
改善者: Pragya vidyarthi
评论前必须登录!
注册