 srcmini
srcminiJava如何实现HashMap?HashMap是java提供的一个字典数据结构。它是一个基于Map(散列表)的集合类,HashMap使用键值对存储数据。在本文中,我们将创建自己的HashMap实现,首先我们来解析Java HashMap工作原理,然后介绍使用Java实现HashMap。
使用这种数据结构的好处是更快进行的数据检索,在最佳情况下,它的数据访问复杂度为O(1)。HashMap的最基本形式就是散列表,一个键(key)对应一个值(value),如下图所示:

用外行人的话说,对于每个键,我们都会得到相应的值。
为了实现这个HashMap数据结构,
- 我们需要一个列表来存储HashMap的所有键(key)。
- 键-值关系(key-value),以获取基于键的值。
我们可以有一个包含所有键和值的列表,以方便我们搜索HashMap的所有键和值。
但是我们使用Java实现HashMap的主要目的是在O(1)时间内更快地使用键访问数据。
这里,哈希开始起作用了。我们可以对键进行散列,并将其与索引关联起来,以更快地检索数据。
散列也有一个问题:碰撞。我们总是建议使用更好的哈希函数,以减少冲突的机会。
多个散列可以有相同的散列键。因此,如果发生碰撞,每个键都有一个存储所有值的桶或容器。
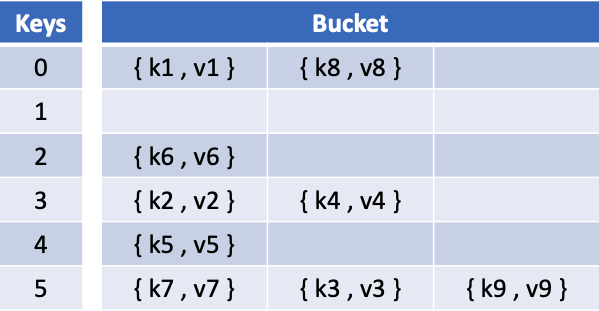
Java如何实现HashMap?让我们深入了解hashmap的基本实现。
首先,我们需要一个数组来存储所有的键,一个桶模型来存储所有的条目,还有一个包装器来存储我们的键值对。
下面是Java HashMap实现代码的起点:最基本的HashMap的样子如下:
public class MyKeyValueEntry<K, V> {
private K key;
private V value;
public MyKeyValueEntry(K key, V value) {
this.key = key;
this.value = value;
}
// getters & setters
// hashCode & equals
}存储所有键值的桶
public class MyMapBucket {
private List<MyKeyValueEntry> entries;
public MyMapBucket() {
if(entries == null) {
entries = new LinkedList<>();
}
}
public List<MyKeyValueEntry> getEntries() {
return entries;
}
public void addEntry(MyKeyValueEntry entry) {
this.entries.add(entry);
}
public void removeEntry(MyKeyValueEntry entry) {
this.entries.remove(entry);
}
}Java如何实现HashMap?如下代码,这就是Java实现HashMap的完整代码了:
public class MyHashMap<K, V> {
private int CAPACITY = 10;
private MyMapBucket[] bucket;
private int size = 0;
public MyHashMap() {
this.bucket = new MyMapBucket[CAPACITY];
}
private int getHash(K key) {
return (key.hashCode() & 0xfffffff) % CAPACITY;
}
private MyKeyValueEntry getEntry(K key) {
int hash = getHash(key);
for (int i = 0; i < bucket[hash].getEntries().size(); i++) {
MyKeyValueEntry myKeyValueEntry = bucket[hash].getEntries().get(i);
if(myKeyValueEntry.getKey().equals(key)) {
return myKeyValueEntry;
}
}
return null;
}
public void put(K key, V value) {
if(containsKey(key)) {
MyKeyValueEntry entry = getEntry(key);
entry.setValue(value);
} else {
int hash = getHash(key);
if(bucket[hash] == null) {
bucket[hash] = new MyMapBucket();
}
bucket[hash].addEntry(new MyKeyValueEntry<>(key, value));
size++;
}
}
public V get(K key) {
return containsKey(key) ? (V) getEntry(key).getValue() : null;
}
public boolean containsKey(K key) {
int hash = getHash(key);
return !(Objects.isNull(bucket[hash]) || Objects.isNull(getEntry(key)));
}
public void delete(K key) {
if(containsKey(key)) {
int hash = getHash(key);
bucket[hash].removeEntry(getEntry(key));
size--;
}
}
public int size() {
return size;
}
}下面解析Java实现HashMap的完整过程:
添加条目进HashMap:
- 如果key已经存在,则更新该key的值。
- 否则,向桶中添加一个条目。
从HashMap获取条目:
- 检查键是否存在,并返回数据。
包含:
- 检查桶是否为空
- 如果不是,则表示桶中包含该键。
性能:
- 它的性能在最好情况下是O(1),在最坏情况下是O(n)。
JDK中的实现改进,下面是JDK中Java HashMap工作原理:
- 从Java version 8开始,所有基于哈希的Map实现: HashMap、Hashtable、LinkedHashMap、WeakHashMap和ConcurrentHashMap都被修改为当哈希表的容量超过512个条目时,对字符串键使用增强的哈希算法。增强的散列实现使用了murmur3散列算法以及随机散列种子和索引掩码。这些增强减轻了字符串哈希值碰撞可能导致性能瓶颈的情况。替代字符串散列实现
- 在Java version 8中,一旦散列桶中的项目数量增长超过某个阈值,该桶将从使用链表项切换到平衡树。在高哈希碰撞的情况下,这将提高最坏情况下的性能,从O(n)到O(log n)。使用平衡树处理频繁的HashMap冲突。
JDK的Java实现HashMap的特点:
- 初始容量默认为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;- 在构造函数中指定none时使用的加载因子。
static final float DEFAULT_LOAD_FACTOR = 0.75f;- 为容器使用树而不是列表的容器计数阈值。当向至少有这么多节点的容器中添加元素时,容器会转换为树。
static final int TREEIFY_THRESHOLD = 8;- 在调整大小操作期间取消树形化(拆分)容器的容器计数阈值。
static final int UNTREEIFY_THRESHOLD = 6;- HashMap实例有两个影响其性能的参数: 初始容量和负载系数。
- *容量是哈希表中的桶数
- *初始容量是哈希表创建时的容量。
- 负载系数是一种衡量在自动增加哈希表的容量之前哈希表允许的满度的度量。
- 当哈希表中的条目数超过负载系数和当前容量的乘积时,哈希表被重新哈希(也就是说,重新构建内部数据结构),以便哈希表的桶数大约是桶数的两倍。
- 作为一般规则,默认负载系数(0.75)在时间和空间成本之间提供了很好的权衡。
- *较高的值会减少空间开销,但会增加查找成本(反映在HashMap类的大多数操作中,包括get和put)。
- 在设置map的初始容量时,应该考虑map的预期条目数和它的负载系数,以减少重新哈希操作的数量。
- *如果初始容量大于最大条目数除以负载系数,则不会发生重新哈希操作。
Java如何实现HashMap?以上就是Java实现HashMap的全部内容了,包括简单介绍了Java HashMap工作原理,然后是Java实现HashMap的详细过程,包括Java HashMap实现代码及其解析,最后是介绍Java自带的HashMap的原理和实现标准介绍。希望本文可以帮助到你,如有问题,请在下方评论。
评论前必须登录!
注册