 srcmini
srcmini本文概述
要提取段落文本,我们使用XWPFDocument类的getParagraphs()方法。此方法返回文档所有段落的列表,这些列表可以存储在列表变量中并通过迭代循环获取。
让我们看一个使用Java程序提取段落的示例。
Apache POI提取段落示例
package poiexample;
import java.io.FileInputStream;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
public class ReadParagraphExample {
public static void main(String[] args) {
try(FileInputStream fis = new FileInputStream("srcmini.docx")) {
XWPFDocument doc = new XWPFDocument(OPCPackage.open(fis));
java.util.List<XWPFParagraph> paragraphs = doc.getParagraphs();
for (XWPFParagraph paragraph: paragraphs){
System.out.println(paragraph.getText());
}
}catch(Exception e) {
System.out.println(e);
}
}
}输入:
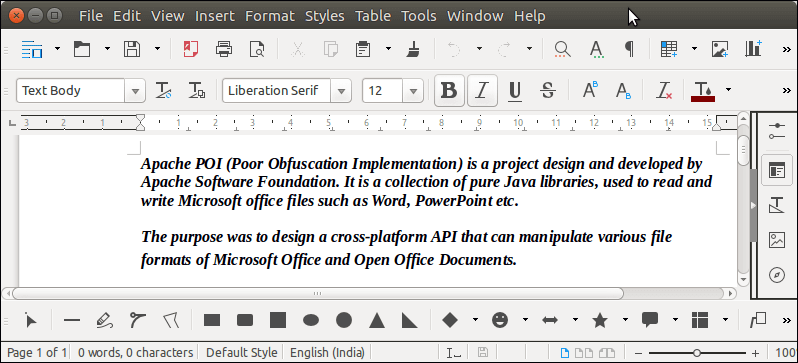
输出:
Apache POI (Poor Obfuscation Implementation) is a project design and developed by Apache Software
Foundation. It is a collection of pure Java libraries, used to read and write Microsoft office
files such as Word, PowerPoint etc. The purpose was to design a cross-platform API that can
manipulate various file formats of Microsoft Office and Open Office Documents.
评论前必须登录!
注册