 srcmini
srcmini编译器的运行流程主要分为前端处理,中间表示和后端处理,而在前端处理中又可分为词法分析、语法分析、语义分析和中间代码生成。现在我们首先开始了解词法分析的运行原理、分析任务,以及其分析结果的表示形式。
1、词法分析的目标和数据结构

词法分析主要是将源码字符流转换成token记号流,对源码字符进行分析,我们可以先将这些字符进行分类,如下一个简单的C程序:
#include <stdio.h>
int main(){
char *message = "hello ubuntu!";
printf("message: %s\n", message);
return 0;
}
对于以上的源码字符,我们可以简单地将这些字符分为关键字(int),限定符(大括号),标识符(message)等,每种类型的字符有它相应的值,使用一个结构体表示如下:
enum type{INT, LT, GT, ID};
struct token{
enum type type;
char *value;
};
Type表示字符的类型,value表示字符对应的值,token称为一个词法单元,每个字符都使用这样的token表示,这样我们就完整地表示了源码中的所有字符。
2、Token词法单元的表示形式
Token的主要表示形式如下:

可以简要表示为token{type,value},类别码就是字符单元的类型,属性值是对应字符的值,那么什么是类别码呢?类别码在一般的编程语言中主要分为5种:
- 关键字:例如if、break,而这些字符一般唯一而且没有值,所以它们的type是唯一的,如对应if我们可以表示为:token{IF,0}。
- 标识符:其实关键字也是标识符,不过这里说的标识符主要是自定义的标识符,如变量名,函数名等,自定义标识符不唯一,统一使用ID表示标识符的类型,而value是标识符的字面值,如number=90;number表示为:token{ID,number}。
- 常量:如number=90,90就是常量,表示为token{CONST,90}。
- 运算符:字符唯一和关键字的表示一样,如<可表示为token{LT,0}。
- 界限符:如大括号{}就是界限符,和运算符表示形式一样。
3、使用Flex进行词法分析的简要例子
Flex是一个词法分析器生成器,后面我们会介绍如何使用该工具,现在我们主要看一下使用词法分析器对C语言的分析效果。
新建Clex.l文件为Flex的源代码,具体写法暂不介绍,使用Flex编译:flex clex.l,Flex默认会生成文件lex.yy.c,使用gcc编译该文件:gcc –o analyzer lex.yy.c,得到的analyzer即为词法分析器。
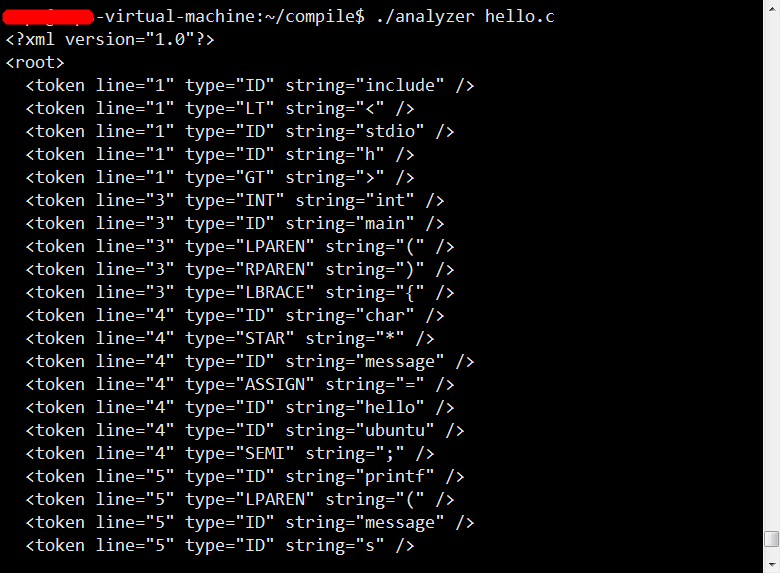
新建hello.c文件,简单写一几行C代码,使用analyzer分析该文件,得到如下结果:
评论前必须登录!
注册