 srcmini
srcmini本文概要
NLP教程提供了NLP教程的基础和先进理念。我们的NLP教程是专为初学者和专业人士。
NLP是什么?
NLP代表自然语言处理,这是计算机科学,人类的语言,和人工智能的一部分。这是所使用的机器理解,分析,处理和解释人类语言的技术。它可以帮助开发人员组织的知识来执行任务,如翻译,自动文摘,命名实体识别(NER),语音识别,关系抽出,和主题划分。
NLP的历史
(1940-1960) – 专注于机器翻译(MT)
自然语言处理在1940年开始。
1948年 – 在1948年的年度起,第一辨认NLP应用在伯克贝克学院,伦敦推出。
20世纪50年代 – 在20世纪50年代年,有语言学和计算机科学之间的相互矛盾的观点。现在,乔姆斯基发展了他的第一本书句法结构,并声称该语言在本质上生成。
1957年,乔姆斯基还推出生成语法,这是规则的句法结构的基础描述的想法。
(1960-1980) – 香料与人工智能(AI)
在1960年到1980年,主要发展有:
扩充转移网络(ATN)
扩充转移网络是一个有限状态机,能够识别正规语言。
格语法
格语法是由语言学家查尔斯·J·菲尔莫尔在今年开发的1968年格语法使用的语言,如英语用介词来表达名词和动词之间的关系。
在格语法,情况角色可以被定义为特定类型的动词和对象的链接。
例如:“NEHA打破与锤镜”。在该示例情况下的语法识别NEHA作为代理,镜子为题材,和锤作为一种工具。
1960年全年到1980年,关键系统分别为:
SHRDLU
SHRDLU是特里在的Winograd书面1968-70程序。它可以帮助用户与计算机和移动对象进行通信。它可以处理如“拿起绿色铃”,并回答这样问题的说明“什么是黑盒子里面。” SHRDLU的主要重要性在于,它显示了这些语法,语义和大约可以组合,以产生理解自然语言的系统在世界推理。
LUNAR
LUNAR是一种自然语言的数据库接口系统,用于ATNS和伍兹的程序语义的典型例子。这是能够翻译复杂的自然语言表达到数据库查询和处理请求的78%,没有错误。
1980年 – 现在
直到1980年,自然语言处理系统是基于复台手写规则。 1980年以后,NLP介绍机器学习算法语言处理。
在这一年20世纪90年代初,开始NLP增长较快,取得了良好的加工精度,尤其是在英语语法。 1990年还,一电子文本的出台,这对培训和研究自然语言程序提供了很好的资源。其他因素可能包括与快速的CPU和更大的内存电脑的可用性。自然语言处理的发展背后的主要因素是互联网。
现在,现代NLP包括各种应用,如语音识别,机器翻译和机器文本阅读。当我们将所有这些应用程序则允许人工智能世界的增益知识。让我们考虑AMAZON ALEXA的例子,使用这种机器人,你可以问这样的问题Alexa的,它将给你答复。
NLP的优势
- NLP可以帮助用户询问有关任何主题的问题,并在几秒内获得的直接回应。
- NLP提供确切答案的问题意味着它不提供不必要的和不需要的信息。
- NLP可以帮助计算机在他们的语言人类交流。
- 这是非常有效的时间。
- 大多数公司都使用NLP,提高文档处理,文件的准确性的效率,并确定从大型数据库中的信息。
NLP的缺点
NLP的缺点的名单下面给出:
- NLP可能不显示背景。
- NLP是不可预测的
- NLP可能需要更多的击键。
- NLP是无法适应新的领域,它有一个有限的功能,这就是为什么NLP是专为只有单一和具体任务。
NLP的组件
有NLP的以下两个组件 –
1.自然语言理解(NLU)
自然语言理解(NLU)帮助机器理解并提取内容,如概念,实体,关键字,情感,关系和语义角色的元数据分析人类语言。
NLU主要用于业务应用来了解口语和书面语言的客户的问题。
NLU涉及下列任务 –
- 它被用于映射给定的输入成有用的表示。
- 它被用来分析语言的不同方面。
2.自然语言生成(NLG)
自然语言生成(NLG)充当该计算机化的数据转换成自然语言表示的转换器。它主要包括规划文本,规划句子和文本实现。
注:NLU比NLG困难。
NLU和NLG的区别
| NLU | NLG |
|---|---|
| NLU是阅读和解释语言的过程。 | NLG是书写或生成语言的过程。 |
| 它产生从自然语言输入非语言输出。 | 它从非语言输入生成自然语言输出。 |
NLP的应用
有NLP以下应用 –
1.问题回答
答疑的重点是建设系统,可自动回答的问题在自然语言问人类。

2.垃圾邮件检测
垃圾邮件检测是用来检测的垃圾邮件让用户的收件箱。
3.情感分析
情感分析也被称为意见挖掘。它被用来在网络上进行分析的态度,行为和发送者的情绪状态。此应用程序通过指定的值,以文本(正面,负面或自然)通过NLP(自然语言处理)和统计数据的组合来实现,识别环境的(快乐,悲伤,愤怒等)情绪

4.机器翻译
机器翻译用于文本或语音翻译从一种自然语言到另一种自然语言。
例如:谷歌翻译
5.拼写校正
Microsoft公司提供的文字处理软件,如MS-的Word,PowerPoint的拼写校正。
6.语音识别
语音识别是用于转换所说的话转换成文本。它在应用中,如移动,家庭自动化,视频恢复,口述到Microsoft Word,语音生物识别,语音用户界面,使用等特点。
7.聊天机器人
实施聊天机器人是NLP的重要应用之一。这是许多公司所采用,以提供客户的聊天服务。
8.信息提取
信息提取是NLP的最重要的应用之一。它用于提取从非结构化的或半结构化的机器可读的文件结构信息。
9.自然语言理解(NLU)
它一大套的文本转换成更正式的表示,诸如那些对计算机程序来处理自然语言处理的符号更容易一阶逻辑结构。
如何建立一个NLP管道
有下列步骤来建立一个NLP管道 –
第一步:句子切分
句段是建设NLP管道的第一步。它打破了该段为独立的句子。
例如:考虑下面的段落 –
独立日是每个印度公民的重要节日之一。这是在8月15日,每年庆祝自从印度得到了来自英国统治独立。这一天庆祝真正意义上的独立。
句段产生以下结果:
- “独立日是每个印度公民的重要节日之一。”
- “这是著名的每年自从印度得到了来自英国统治独立8月15日。”
- “这一天庆祝独立真正意义上的。”
第二步:字符号化
字标记生成器是用来打破的句子翻译成单独的词或标记。
例:
srcmini提供企业培训,暑期培训,在线培训和冬季训练。
字标记生成器产生以下结果:
“srcmini”, “报价”, “公司”, “培训”, “夏”, “培训”, “在线”, “培训”, “和”, “冬”, “培训”, “”
第三步:词干
词干是用于归一化的话成其碱形式或词根形式。例如,庆祝,庆祝庆祝和,所有这些话都是源于一个根词“普天同庆”。与所产生的一个大问题是,有时它产生可能没有任何意义的词根。
例如,智能,智能,聪明,所有的这些话是源于一个根词“intelligen。”在英语中,单词“intelligen”没有任何意义。
第4步:词形还原
词形还原颇为相似Stamming。它是用来字,叫引理组不同的屈折形式。词干和词形还原之间的主要区别是,它产生的根字,其具有的含义。
例如:在词形还原,词语情报,智能化,并且智能地有一个根字智能,其具有的含义。
第5步:确定停用词
在英语中,有很频繁出现,如“是”,“和”,“中”,和“a”很多的话。 NLP管道将标记这些词作为停用词。停止的话可能会做任何统计分析前被过滤掉。
例如:他是个好孩子。
注意:当你正在建设一个摇滚乐队的搜索引擎,那么你千万不要忽视这个词“了。”
步骤6:依存句法分析
依存分析是用来发现怎么都在句子中的词彼此相关。
步骤7:POS标签
POS代表语音,它包括名词,动词,副词,和形容词的部分。这表明,如何与句子中的语法意义以及一个字功能。一个字具有基于在其被使用的上下文语音的一个或多个部分。
例如:“谷歌”在互联网上的东西。
在上述例子中,谷歌被用作动词,尽管它是专有名词。
步骤8:命名实体识别(NER)
命名实体识别(NER)是检测命名实体,例如人名,电影名称,机构名称或位置的过程。
例如:史蒂夫·乔布斯推出了iPhone在Macworld大会在旧金山,加利福尼亚。
步骤9:分块
分块是用来收集信息的单件,并将它们组合到更大片的句子。
NLP的阶段
有NLP以下五个阶段:
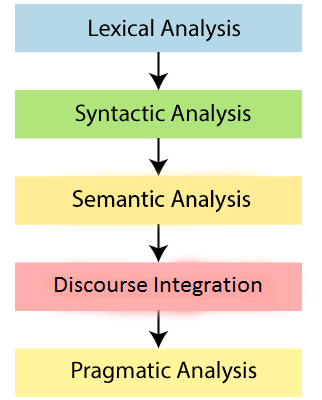
1.词法分析和形态
NLP的第一阶段是词法分析。这个阶段扫描源代码作为字符流,并将其转换为有意义的词位。它把整个文本段落,句子和单词。
2.句法分析(解析)
句法分析被用来检查语法,单词的安排,并显示该单词之间的关系。
例如:阿格拉转到Poonam
3.语义分析
语义分析涉及的意思表示。它主要集中在单词,短语和句子的字面意思。
4.话语整合
话语整合方式取决于它进行,并调用它后面句子的含义的句子。
5.语用分析
务实是第五和NLP的最后一个阶段。它可以帮助你通过应用组表征合作对话的规则来发现预期的效果。
例如:“开门”被解释为一个请求而不是一个命令。
为什么NLP难?
NLP是困难的,因为模糊性和不确定性的语言存在。
歧义
有以下三种模糊性 –
- 词汇歧义
词汇歧义存在于句子的两个或更多个可能的含义一个字内的存在。
例:
曼娅正在寻找一个匹配。
在上面的例子中,字匹配是指任一玛妮雅正在寻找一个伙伴或玛妮雅正在寻找匹配。 (蟋蟀或其他匹配)
- 歧义
句法歧义存在于两个或多个可能的含义的句子中的存在。
例:
我看到了双眼的女孩。
在上面的例子中,没有我的望远镜?还是因为女孩有双筒望远镜?
- 参照歧义
参照歧义时,你正在使用的代词指东西存在。
例如:基兰去苏尼塔。她说:“我饿了。”
在上面的句子,你不知道谁是饿了,要么基兰或苏尼塔。
NLP的API
自然语言处理的API允许开发人员集成人类对机器通信和完整一些有用的任务,如语音识别,聊天机器人,拼写纠错,情感分析等。
NLP的API列表给出如下:
- IBM沃森API IBM沃森API结合不同的复杂的机器学习技术,使开发人员分类文本成各种自定义类别。它支持多国语言,如英语,法语,西班牙语,德语,中国等。随着IBM沃森API的帮助下,你可以从文本中提取的见解,在工作流中添加自动化,提高搜索和理解情绪。这个API的主要优点是,它是非常容易使用。定价:首先,它提供了一个30天的免费试用IBM云帐号。你也可以选择在其缴入计划。
- 聊天机器人API聊天机器人API允许你为任何服务创建智能聊天机器人。它支持Unicode字符,分类文本,多国语言等,这是非常容易使用。它可以帮助你为你的Web应用的聊天机器人。定价:聊天机器人API是免费的,每月150个请求。你也可以选择它的付费版本,开始从$ 100到$ 5000元。
- 语音到文本API语音到文本API用于将语音转换为文本定价:语音到文本API是免费的,每月转换60分钟。其付费版本开始形成$ 500至$ 1500/10一个月。
- 情感分析API情感分析API也被称为是用来识别用户(正面,负面或中性)的基调“意见挖掘”定价:情感分析API是免费的,每月不到500个请求。其付费版本开始形成$ 19至$ 99%不等。
- 翻译API通过SYSTRAN翻译API通过SYSTRAN用于从源语言到目标语言的文本翻译。你可以使用它的NLP的API语言检测,文本分割,命名实体识别,符号化,以及许多其他任务。定价:这个API是免费提供的。但是对于商业用户,你需要使用它的付费版本。
- 文本分析API通过AYLIEN文本分析API通过AYLIEN用于推导的意义和从文本内容的见解。它同时适用于免费和付费从$ 119元不等。这个用起来很简单。定价:这个API是免费提供每天1000次点击。你还可以使用其付费版本,开始从$ 199 S1,399元不等。
- 云NLP API云API NLP是用来提高使用自然语言处理技术的应用程序的能力。它可以让你随身携带喜欢情感分析和语言检测各种自然语言处理功能。这个用起来很简单。定价:云NLP API是免费提供的。
- 谷歌云自然语言API谷歌云自然语言的API允许你提取从非结构化文本有益的见解。这个API可以让你在超过700点预定义的类别进行实体识别,情感分析,内容分类,和语法分析。它还允许你在多国语言,如英语,法语,中国和德国进行文本分析。价格:5000万〜1000万台演出单位分析之后,你需要每月支付每1000个单位$ 1.00美元。
NLP库
Scikit学习:它提供了一个广泛的算法在Python建筑机器学习模型。
自然语言工具包(NLTK):NLTK是所有NLP技术一个完整的工具包。
图案:这是自然语言处理和机器学习的web挖掘模块。
TextBlob:它提供了一个简单的界面来学习像情感分析,名词短语提取,或POS标记基本NLP任务。
Quepy:Quepy用于自然语言问题转化为查询数据库中的查询语言。
SpaCy:SpaCy是用于数据提取,数据分析,情感分析和文本摘要一个开源NLP库。
Gensim:Gensim可与大型数据集和处理数据流。
自然语言与计算机语言之间的差异
| 自然语言 | 电脑语言 |
|---|---|
| 自然语言有很大的词汇量。 | 计算机语言的词汇量非常有限。 |
| 自然语言很容易被人理解。 | 计算机语言很容易被机器理解。 |
| 自然语言在本质上是模棱两可的。 | 计算机语言是毫不含糊的。 |
条件
学习NLP之前,你必须安装Python的基本知识。
听众
我们的NLP教程旨在帮助初学者。
问题
我们保证,你不会找到这个NLP教程任何问题。但是,如果有任何错误或错误,请在联系表的误差。
评论前必须登录!
注册