 srcmini
srcmini本文概要
- K-最近的邻居是基于监督学习技术最简单的机器学习算法之一。
- K-NN算法假定新的案例/数据和可用的情况下之间的相似性,并把新的情况下进入最相似的可用类别的类别。
- K-NN算法存储所有可用数据和分类新的数据点基础上的相似性。当出现新的数据,这意味着然后可以很容易地通过使用K- NN算法分类为良好套件类别。
- K-NN算法可用于回归以及为分类但大多用于分类问题。
- K-NN是一种非参数的算法,这意味着它不作任何假设上的底层数据。
- 它也被称为懒学习算法,因为它不从训练集学习,而不是立即它存储的数据集,并在分类时,它将对数据集的操作。
- 在训练阶段KNN算法只是存储的数据集,当它获得新的数据,那么这些数据分类到的类别,是非常相似的新数据。
- 例子:假设,我们有一个动物,类似于猫,狗,但我们想知道它要么是猫或狗的图像。因此,对于这个身份,我们可以使用KNN算法,因为它的工作原理上的相似性度量。我们的KNN模型会发现新的数据集猫狗图像,并基于最相似特征的相似特性就会把它无论是猫还是狗类。
为什么我们需要一个K-NN算法?
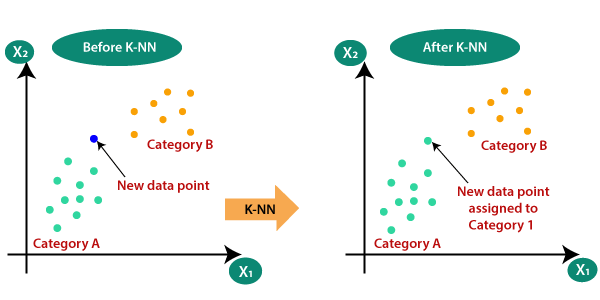
假设有两个类别,即,类别A和B类,我们有一个新的数据点X1,所以这个数据点将处于这些类别。为了解决这类问题,我们需要一个K-NN算法。随着K-NN的帮助下,我们可以很容易地识别特定的数据集的类别或类。请看下图:
如何K-NN的工作?
在K-NN的工作可以在下面算法的基础上进行解释:
- 第1步:选择邻居的数K
- 步骤2:计算的邻居的K个欧几里德距离
- 步骤3:取最近邻的K作为每计算出的欧几里德距离。
- 步骤4:在这k个邻居,计数每个类别中的数据点的数量。
- 第五步:指定新的数据指向类别进行了邻居的数量是最大的。
- 步6:我们的模式是准备好了。
假设我们有一个新的数据点,我们需要把它放到需要的类别。考虑下面的图片:
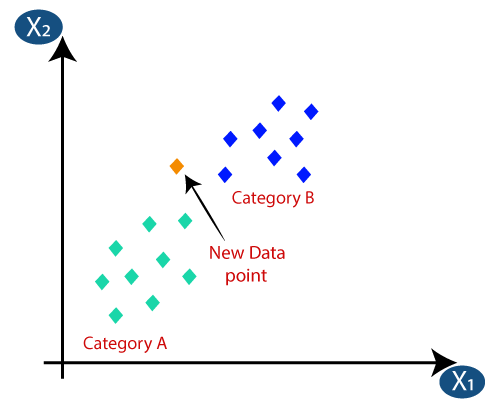
- 首先,我们将选择邻居的数目,所以我们会选择K = 5。
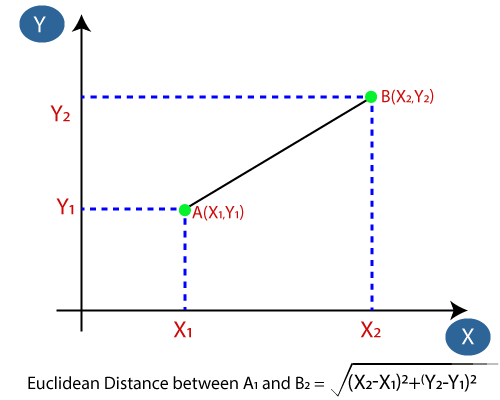
- 接下来,我们将计算数据点之间的欧氏距离。欧几里得距离是两个点,这是我们在几何已经学习之间的距离。它可以计算为:
- 通过计算我们得到了最近的邻居欧氏距离,如A类三个最近的邻居和在类别中的两个最近的邻居B.考虑下面的图片:
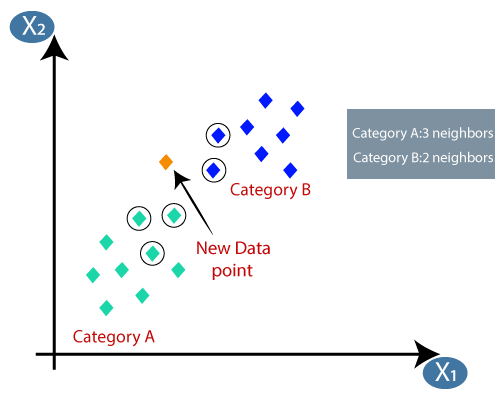
- 我们可以看到3个最近的邻居是从A类,所以这个新的数据点必须属于A类
如何选择的K在K-NN算法的价值?
下面是一些点要记住,而在K-NN算法选择K值:
- 还有就是要确定最佳值,“K”,所以我们需要尝试一些值来找到他们的最佳出没有特别的办法。对于K的最优选的值是5。
- 为K A非常低的值,例如K = 1或K = 2,可以是有噪声的,并导致在模型异常值的影响。
- 对于K值大是好的,但它可能会发现一些困难。
KNN算法的优点
- 这是很容易实现。
- 它是强大的喧闹的训练数据
- 它可以是如果训练数据量大更有效。
KNN算法的缺点
- 总是需要确定其可以是复杂的一段时间K的值。
- 计算成本很高,因为计算数据点之间的距离为所有的训练样本。
Python实现了KNN算法
做Python实现的K-NN算法,我们将使用同样的问题,数据集中,我们在Logistic回归已经使用。但在这里,我们将提高模型的性能。下面是问题描述:
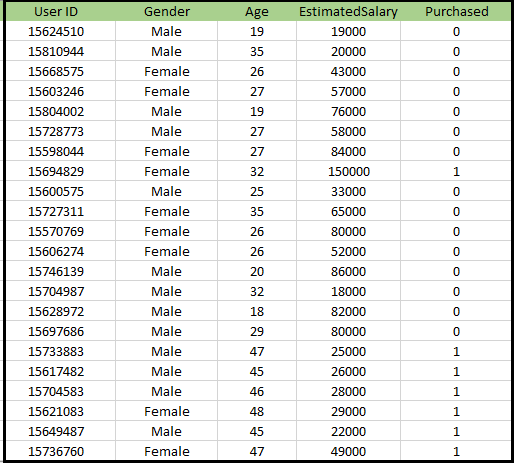
问题的K-NN算法:有一个汽车制造商的公司,已经制造了新的SUV车。该公司希望给广告谁有兴趣购买的是SUV的用户。因此,对于这个问题,我们有一个包含通过社交网络的多个用户的信息的数据集。该数据集包含了大量的信息,但估计工资和年龄,我们会考虑独立变量和购买的变量是因变量。下面是数据集:
步骤来实现K-NN算法:
- 数据前处理步骤
- 拟合K-NN算法训练集
- 预测测试结果
- 结果的测试精度(混淆矩阵的创建)
- 可视化测试集的结果。
数据预处理步骤:
该数据预处理步骤将保持完全一样Logistic回归。下面是它的代码:
# importing libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
#importing datasets
data_set= pd.read_csv('user_data.csv')
#Extracting Independent and dependent Variable
x= data_set.iloc[:,[2,3]].values
y= data_set.iloc[:,4].values
# Splitting the dataset into training and test set.
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test= train_test_split(x,y,test_size= 0.25,random_state=0)
#feature Scaling
from sklearn.preprocessing import StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)通过执行上面的代码,我们的数据集被导入到我们的程序以及预处理。经过缩放功能,我们的测试数据集将是这样的:
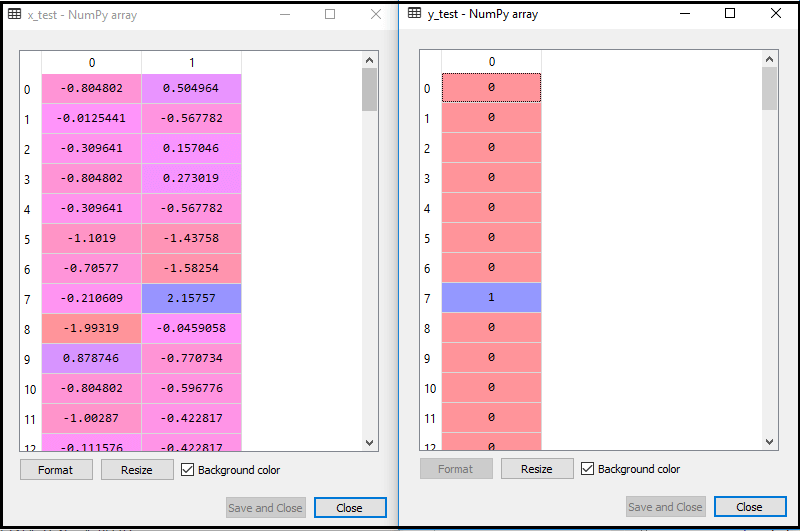
从上面的输出图像,我们可以看到,我们的数据被成功放大。
- 配件K-NN分类训练数据:现在,我们将适应K-NN分类训练数据。要做到这一点,我们将导入KNeighborsClassifier类Sklearn邻居库。导入类之后,我们将创建类的分类对象。这个类的参数将是N_NEIGHBORS:要定义的算法所需的邻居。通常情况下,它需要5.度量=“闵可夫斯基”:这是默认参数,并将其决定点之间的距离。 p = 2时:这是相当于标准欧几里德度量。然后,我们将适合的分类训练数据。下面是它的代码:
#Fitting K-NN classifier to the training set
from sklearn.neighbors import KNeighborsClassifier
classifier= KNeighborsClassifier(n_neighbors=5,metric='minkowski',p=2 )
classifier.fit(x_train,y_train)输出:通过执行上面的代码,我们将得到的输出:
Out[10]:
KNeighborsClassifier(algorithm='auto',leaf_size=30,metric='minkowski',metric_params=None,n_jobs=None,n_neighbors=5,p=2,weights='uniform')- 预测的测试结果:预测测试集的结果,我们将我们Logistic回归做创建y_pred载体。下面是它的代码:
#Predicting the test set result
y_pred= classifier.predict(x_test)输出:
对于上述代码的输出将是:
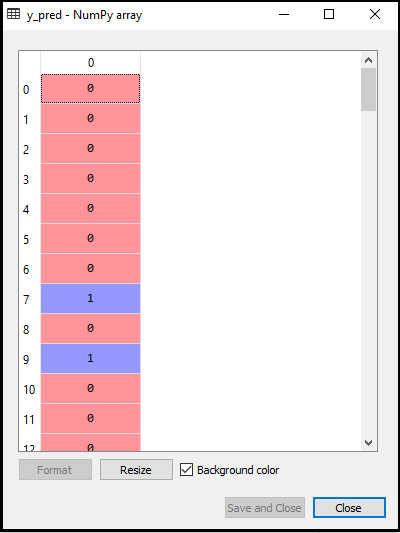
- 创建混淆矩阵:现在我们将创建混淆矩阵为我们的K-NN模型来查看分类的准确性。下面是它的代码:
#Creating the Confusion matrix
from sklearn.metrics import confusion_matrix
cm= confusion_matrix(y_test,y_pred)在上面的代码中,我们已导入confusion_matrix功能和使用可变厘米称之为。
输出:通过执行上面的代码,我们将得到矩阵如下:
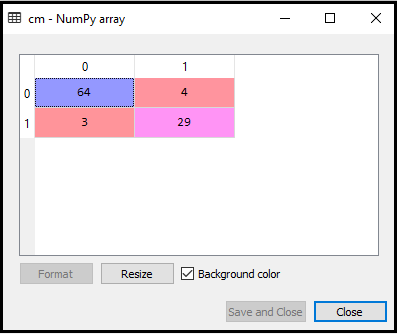
另外,在上述图像中,我们可以看到有64 + 29 = 93个正确的预测和3 + 4 = 7个不正确的预测,而在逻辑回归,有11个不正确的预测。所以我们可以说,该模型的性能是通过使用K-NN算法改进。
- 可视化训练集的结果:现在,我们将可视化的K-NN模型训练集的结果。正如我们在Logistic回归做的代码将保持不变,只是图形的名称。下面是它的代码:
#Visulaizing the trianing set result
from matplotlib.colors import ListedColormap
x_set,y_set = x_train,y_train
x1,x2 = nm.meshgrid(nm.arange(start = x_set[:,0].min() - 1,stop = x_set[:,0].max() + 1,step =0.01),nm.arange(start = x_set[:,1].min() - 1,stop = x_set[:,1].max() + 1,step = 0.01))
mtp.contourf(x1,x2,classifier.predict(nm.array([x1.ravel(),x2.ravel()]).T).reshape(x1.shape),alpha = 0.75,cmap = ListedColormap(('red','green' )))
mtp.xlim(x1.min(),x1.max())
mtp.ylim(x2.min(),x2.max())
for i,j in enumerate(nm.unique(y_set)):
mtp.scatter(x_set[y_set == j,0],x_set[y_set == j,1],c = ListedColormap(('red','green'))(i),label = j)
mtp.title('K-NN Algorithm (Training set)')
mtp.xlabel('Age')
mtp.ylabel('Estimated Salary')
mtp.legend()
mtp.show()输出:
通过执行上面的代码,我们会得到下面的图:
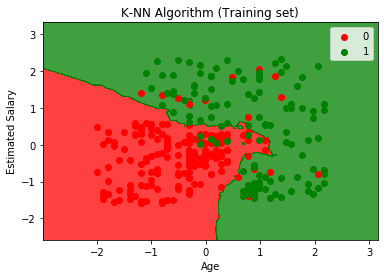
输出曲线是我们都发生在Logistic回归图表中的不同。它可以在下面的点来理解:
- 正如我们所看到的图表显示了红点和绿点。绿色点为购买的商品(1)和用于不红积分换购(0)的变量。
- 该图示出了不规则的边界,而不是表示任何直线或任何曲线,因为它是一个K-NN算法,即,查找最近的邻居。
- 该图在正确的类别分类的用户,因为大多数谁没有买SUV的用户是在红色区域,谁买SUV是在绿色区域的用户。
- 该图显示了很好的结果,但仍然有在绿色区域,红色区域和红点一些绿色点。但是,这是没有什么大问题,因为做这个模型过度拟合问题阻止。
- 因此,我们的模型是训练有素的。
- 可视化测试集的结果:该模型的训练后,现在我们将通过把新的数据集,即,测试数据集测试的结果。代码仍然只是一些细微的变化是一样的:如x_train和y_train将x_test和y_test所取代。下面是它的代码:
#Visualizing the test set result
from matplotlib.colors import ListedColormap
x_set,y_set = x_test,y_test
x1,x2 = nm.meshgrid(nm.arange(start = x_set[:,0].min() - 1,stop = x_set[:,0].max() + 1,step =0.01),nm.arange(start = x_set[:,1].min() - 1,stop = x_set[:,1].max() + 1,step = 0.01))
mtp.contourf(x1,x2,classifier.predict(nm.array([x1.ravel(),x2.ravel()]).T).reshape(x1.shape),alpha = 0.75,cmap = ListedColormap(('red','green' )))
mtp.xlim(x1.min(),x1.max())
mtp.ylim(x2.min(),x2.max())
for i,j in enumerate(nm.unique(y_set)):
mtp.scatter(x_set[y_set == j,0],x_set[y_set == j,1],c = ListedColormap(('red','green'))(i),label = j)
mtp.title('K-NN algorithm(Test set)')
mtp.xlabel('Age')
mtp.ylabel('Estimated Salary')
mtp.legend()
mtp.show()输出:
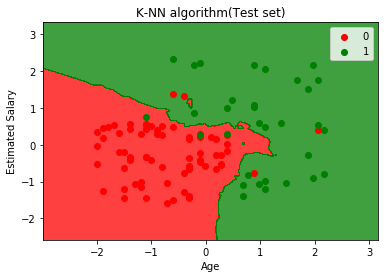
上述曲线图示出了用于测试的数据集的输出。正如我们在图中看到,所预测的输出是非常好,因为大部分的红点是在红色区域,最绿色的点是在绿色区域。
不过,也有在红色区域几个绿点,在绿色区域内的几个红点。因此,这些都是不正确的观察结果,我们在混淆矩阵(7不正确的输出)已经观察到。
评论前必须登录!
注册