 srcmini
srcmini在建立机器学习模型时,逆向消除是一种特征选择技术。它用于删除那些对因变量或输出预测没有显著影响的特性。在机器学习中有各种各样的方法来建立模型,它们是:
- All-in
- 逆向消除
- 正向选择
- 双向消除
- 得分比较
以上是在机器学习中建立模型的可能方法,但这里我们只使用逆向消除过程,因为它是最快的方法。
逆向消除步骤
下面是应用逆向消除过程的一些主要步骤:
步骤1:首先,我们需要在模型中选择一个显著性水平。(SL = 0.05)
步骤2:用所有可能的预测因子/独立变量来拟合完整的模型。
步骤3:选择p值最高的预测因子,比如。
- 如果P值> SL,转到第4步。
- 否则完成,我们的模型已准备就绪。
步骤4:删除预测器。
步骤5:重建,并与其余变量拟合模型。
需要向后消除:一个最优的多元线性回归模型:
在前一章中,我们讨论并成功创建了我们的多元线性回归模型,其中我们使用了4个自变量(R&D支出、管理支出、营销支出和状态(虚拟变量))和一个因变量(利润)。但该模型不是最优的,因为我们已经包含了所有的自变量,不知道哪个独立模型对预测的影响最大,哪个影响最小。
不必要的特征增加了模型的复杂性。因此,最好只具有最重要的特性,并保持我们的模型简单,以获得更好的结果。
因此,为了优化模型的性能,我们将采用反向消元法。这个过程用于优化MLR模型的性能,因为它只包含影响最大的特性,并删除影响最小的特性。让我们开始把它应用到我们的MLR模型。
对于逆向消除法步骤:
我们将使用我们建立MLR的前一章相同的模型。下面是它的完整代码:
# importing libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
#importing datasets
data_set= pd.read_csv('50_CompList.csv')
#Extracting Independent and dependent Variable
x= data_set.iloc[:,:-1].values
y= data_set.iloc[:,4].values
#Catgorical data
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
labelencoder_x= LabelEncoder()
x[:,3]= labelencoder_x.fit_transform(x[:,3])
onehotencoder= OneHotEncoder(categorical_features= [3])
x= onehotencoder.fit_transform(x).toarray()
#Avoiding the dummy variable trap:
x = x[:,1:]
# Splitting the dataset into training and test set.
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test= train_test_split(x,y,test_size= 0.2,random_state=0)
#Fitting the MLR model to the training set:
from sklearn.linear_model import LinearRegression
regressor= LinearRegression()
regressor.fit(x_train,y_train)
#Predicting the Test set result;
y_pred= regressor.predict(x_test)
#Checking the score
print('Train Score: ',regressor.score(x_train,y_train))
print('Test Score: ',regressor.score(x_test,y_test))从上面的代码中,我们得到了训练和测试集的结果:
Train Score: 0.9501847627493607
Test Score: 0.9347068473282446这两个分数之间的差异是0.0154。
注:在这个分数的基础上,我们将使用后向消除过程来估计特征对我们的模型的影响。
步骤:1-后向消元法的准备:
- 导入库:首先,我们需要导入statsmoders .formula.api库,用于估计各种统计模型,如OLS(普通最小二乘法)。下面是它的代码:
import statsmodels.api as smf- 在特征矩阵中添加一列:
- 正如我们可以检查我们的MLR方程(a),有一个常数项b0,但这一项不存在于我们的特征矩阵中,所以我们需要手动添加它。我们将添加一个列,该列的值x0 = 1与常数项b0相关联。
- 为了添加它,我们将使用Numpy库的append函数(已经导入到代码中的nm),并将赋值为1。下面是它的代码。
x = nm.append(arr = nm.ones((50,1)).astype(int),values=x,axis=1)这里我们使用axis =1,因为我们想添加一个列。要添加一行,可以使用axis =0。
输出:通过执行上述代码行,一个新列将被添加到我们的特性矩阵中,它的所有值都等于1。我们可以通过点击变量资源管理器选项下的x数据集来检查它。
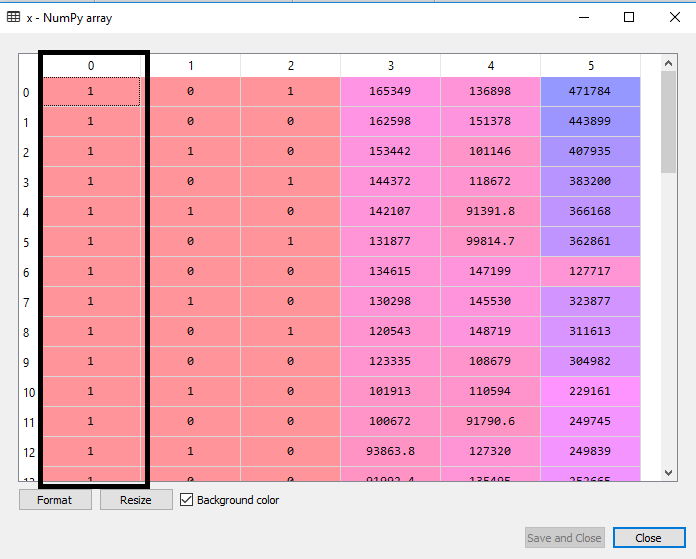
在上面的输出图像中可以看到,第一列被成功地添加,这对应于MLR方程的常数项。
第2步:
- 现在,我们要应用一个反向消去过程。首先,我们将创建一个新的特征向量x_opt,它将只包含一组对因变量有显著影响的独立特征。
- 接下来,根据向后消除过程,我们需要选择一个有效级别(0.5),然后需要用所有可能的预测因素来匹配模型。因此,为了拟合模型,我们将创建statsmodels库的新类OLS的regressor_OLS对象。然后使用fit()方法对其进行拟合。
- 接下来,我们需要p-value与SL值进行比较,因此我们将使用summary()方法来获得所有值的汇总表。下面是它的代码:
x_opt=x [:,[0,1,2,3,4,5]]
regressor_OLS=sm.OLS(endog = y,exog=x_opt).fit()
regressor_OLS.summary()输出:通过执行上面的代码行,我们将得到一个汇总表。考虑下面的图片:
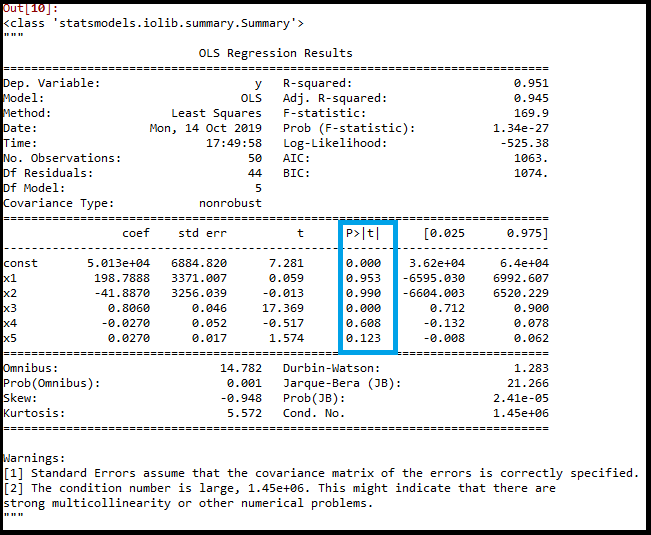
在上图中,我们可以清楚地看到所有变量的p值。这里x1, x2是虚拟变量,x3是研发支出,x4是管理支出,x5是营销支出。
从表中,我们将选择最高的p值,即x1=0.953,现在我们有最高的p值,它大于SL值,所以我们将从表中删除x1变量(虚拟变量),并重新建立模型。下面是它的代码:
x_opt=x[:,[0,2,3,4,5]]
regressor_OLS=sm.OLS(endog = y,exog=x_opt).fit()
regressor_OLS.summary()输出:
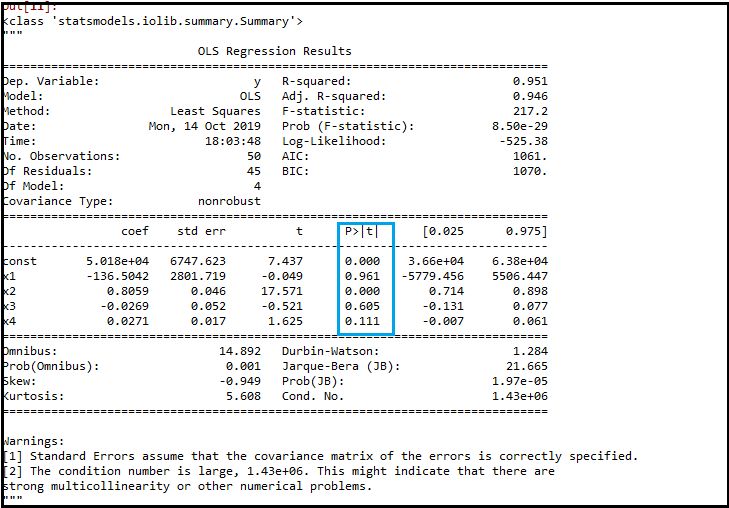
正如我们在输出图像中看到的,现在还剩下五个变量。在这些变量中,p值最高为0.961。所以我们将在下一次迭代中删除它。
- x1变量的下一个最大值是0.961,这是另一个哑变量。所以我们将删除它并重新安装模型。下面是它的代码:
x_opt= x[:,[0,3,4,5]]
regressor_OLS=sm.OLS(endog = y,exog=x_opt).fit()
regressor_OLS.summary()输出:
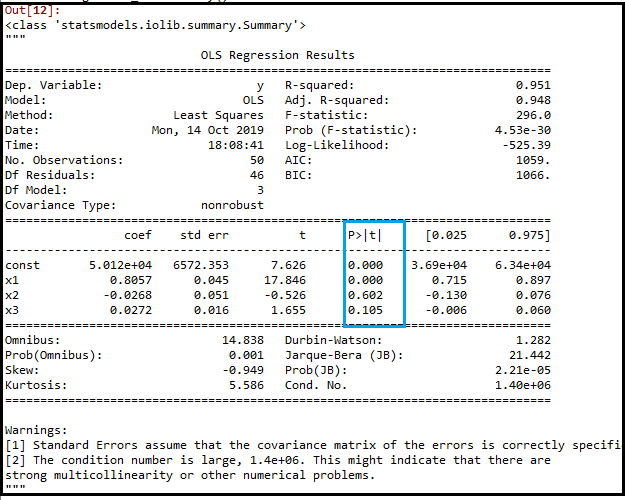
在上面的输出图像中,我们可以看到虚拟变量(x2)已经被删除。下一个最大值是0.602,它仍然大于0.5,所以我们需要移除它。
- 现在我们将删除的管理费用是有.602 p-值和再次改装模型。
x_opt=x[:,[0,3,5]]
regressor_OLS=sm.OLS(endog = y,exog=x_opt).fit()
regressor_OLS.summary()输出:
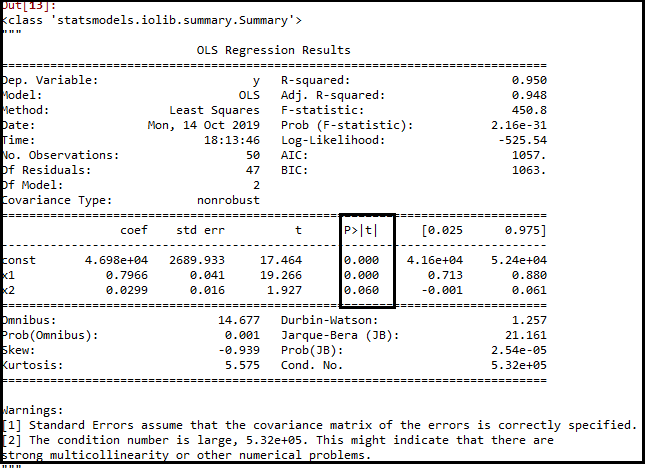
正如我们在上面的输出图像中看到的,变量(Admin spend)已被删除。但是,仍然有一个变量,那就是营销费用,因为它有一个高的p值(0.60)。所以我们需要移除它。
- 最后,我们将删除另一个变量,它的p值为0.60,这是一个非常重要的营销支出水平。下面是它的代码:
x_opt=x[:,[0,3]]
regressor_OLS=sm.OLS(endog = y,exog=x_opt).fit()
regressor_OLS.summary()输出:
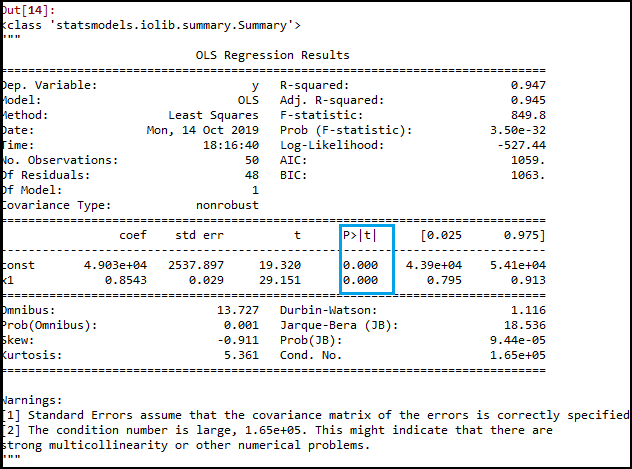
正如我们在上面的输出图像中看到的,只剩下两个变量。因此只有R&D自变量是预测的重要变量。现在我们可以用这个变量来有效地预测。
估计性能:
在前面的主题中,我们计算了模型在使用所有特征变量时的训练和测试分数。现在我们将只使用一个功能变量(研发支出)来检查得分。我们的数据集现在看起来是这样的:
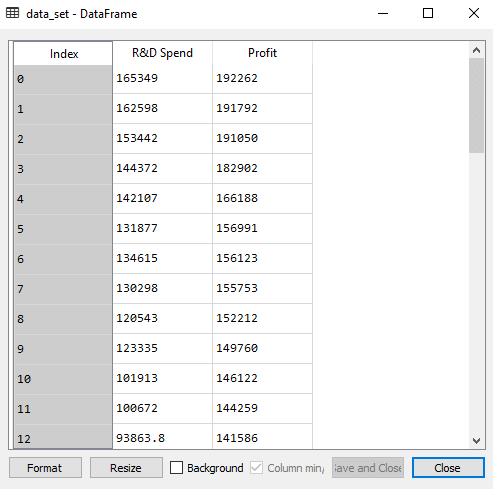
下面是仅使用R&D经费建立多元线性回归模型的代码:
# importing libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
#importing datasets
data_set= pd.read_csv('50_CompList1.csv')
#Extracting Independent and dependent Variable
x_BE= data_set.iloc[:,:-1].values
y_BE= data_set.iloc[:,1].values
# Splitting the dataset into training and test set.
from sklearn.model_selection import train_test_split
x_BE_train,x_BE_test,y_BE_train,y_BE_test= train_test_split(x_BE,y_BE,test_size= 0.2,random_state=0)
#Fitting the MLR model to the training set:
from sklearn.linear_model import LinearRegression
regressor= LinearRegression()
regressor.fit(nm.array(x_BE_train).reshape(-1,1),y_BE_train)
#Predicting the Test set result;
y_pred= regressor.predict(x_BE_test)
#Cheking the score
print('Train Score: ',regressor.score(x_BE_train,y_BE_train))
print('Test Score: ',regressor.score(x_BE_test,y_BE_test))输出:
执行上述代码后,我们将得到训练和测试分数为:
Train Score: 0.9449589778363044
Test Score: 0.9464587607787219可以看出,训练分数是94%的准确率,考试分数也是94%的准确率。两个分数的差是0.00149。这个分数非常接近于以前的分数,即。,其中包含了所有的变量。
我们只使用了一个自变量(研发支出)而不是四个变量就得到了这个结果。因此,我们的模型是简单而准确的。
评论前必须登录!
注册