 srcmini
srcmini在前面的主题中,我们学习了简单线性回归,即使用单个独立的/预测器(X)变量对响应变量(Y)进行建模,但是在不同的情况下响应变量可能受到多个预测器变量的影响;对于这种情况,我们使用了多元线性回归算法。
多元线性回归是简单线性回归的扩展,需要多个预测变量来预测响应变量。我们可以把它定义为:
多元线性回归是建立单因变量与多自变量线性关系模型的重要回归算法之一。
例:
根据汽车的发动机尺寸和气缸数预测二氧化碳排放量。
关于MLR一些要点:
- 对于MLR,因变量或目标变量(Y)必须是连续/实数,而预测变量或自变量可以是连续或分类形式。
- 每个特征变量必须与因变量建立线性关系的模型。
- MLR试图通过多维数据点空间拟合回归线。
MLR方程:
在多元线性回归中,目标变量(Y)是多个预测变量x1、x2、x3、…、xn的线性组合。由于它是对简单线性回归的一种增强,所以对多元线性回归方程同样适用,则方程为:
Y= b<sub>0</sub>+b<sub>1</sub>x<sub>1</sub>+ b<sub>2</sub>x<sub>2</sub>+ b<sub>3</sub>x<sub>3</sub>+...... bnxn ............... (a)其中,
- Y =输出/响应变量
- B0,B1,B2,B3,… BN =模型的系数。
- X1,X2,X3,X4,… =各种独立/特征变量
对于多元线性回归的假设:
- 目标变量和预测变量之间应该存在线性关系。
- 回归残差必须服从正态分布。
- MLR假设数据很少或没有多重共线性(自变量之间的相关性)。
使用Python实现多元线性回归模型
要使用Python MLR实现,我们有以下的问题:
问题描述:
我们有50家初创公司的数据集。该数据集包含五个主要信息:一个财政年度的研发支出、管理支出、营销支出、状态和利润。我们的目标是建立一个模型,可以很容易地确定哪家公司的利润最大,哪家公司的利润影响最大。
因为我们需要计算利润,所以它是因变量,其他四个变量是自变量。下面是部署MLR模型的主要步骤:
- 数据预处理步骤
- 将MLR模型拟合到训练集
- 预测测试集的结果
步骤-1:数据预处理步骤:
第一步是数据预处理,我们已经在本教程中讨论过了。此过程包含以下步骤:
- 导入库:首先,我们将导入有助于构建模型的库。以下是它的代码::
# importing libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd- 导入数据集:现在,我们将导入数据集(50_CompList),它包含了所有的变量。下面是它的代码:
#importing datasets
data_set= pd.read_csv('50_CompList.csv')输出:我们将得到的数据集为:

在上面的输出中,我们可以清楚地看到有五个变量,其中四个变量是连续的,一个是分类变量。
- 提取因变量和自变量:
#Extracting Independent and dependent Variable
x= data_set.iloc[:,:-1].values
y= data_set.iloc[:,4].values输出:
array([[165349.2,136897.8,471784.1,'New York'],[162597.7,151377.59,443898.53,'California'],[153441.51,101145.55,407934.54,'Florida'],[144372.41,118671.85,383199.62,'New York'],[142107.34,91391.77,366168.42,'Florida'],[131876.9,99814.71,362861.36,'New York'],[134615.46,147198.87,127716.82,'California'],[130298.13,145530.06,323876.68,'Florida'],[120542.52,148718.95,311613.29,'New York'],[123334.88,108679.17,304981.62,'California'],[101913.08,110594.11,229160.95,'Florida'],[100671.96,91790.61,249744.55,'California'],[93863.75,127320.38,249839.44,'Florida'],[91992.39,135495.07,252664.93,'California'],[119943.24,156547.42,256512.92,'Florida'],[114523.61,122616.84,261776.23,'New York'],[78013.11,121597.55,264346.06,'California'],[94657.16,145077.58,282574.31,'New York'],[91749.16,114175.79,294919.57,'Florida'],[86419.7,153514.11,0.0,'New York'],[76253.86,113867.3,298664.47,'California'],[78389.47,153773.43,299737.29,'New York'],[73994.56,122782.75,303319.26,'Florida'],[67532.53,105751.03,304768.73,'Florida'],[77044.01,99281.34,140574.81,'New York'],[64664.71,139553.16,137962.62,'California'],[75328.87,144135.98,134050.07,'Florida'],[72107.6,127864.55,353183.81,'New York'],[66051.52,182645.56,118148.2,'Florida'],[65605.48,153032.06,107138.38,'New York'],[61994.48,115641.28,91131.24,'Florida'],[61136.38,152701.92,88218.23,'New York'],[63408.86,129219.61,46085.25,'California'],[55493.95,103057.49,214634.81,'Florida'],[46426.07,157693.92,210797.67,'California'],[46014.02,85047.44,205517.64,'New York'],[28663.76,127056.21,201126.82,'Florida'],[44069.95,51283.14,197029.42,'California'],[20229.59,65947.93,185265.1,'New York'],[38558.51,82982.09,174999.3,'California'],[28754.33,118546.05,172795.67,'California'],[27892.92,84710.77,164470.71,'Florida'],[23640.93,96189.63,148001.11,'California'],[15505.73,127382.3,35534.17,'New York'],[22177.74,154806.14,28334.72,'California'],[1000.23,124153.04,1903.93,'New York'],[1315.46,115816.21,297114.46,'Florida'],[0.0,135426.92,0.0,'California'],[542.05,51743.15,0.0,'New York'],[0.0,116983.8,45173.06,'California']],dtype=object)正如我们在上面的输出中看到的,最后一列包含了不适合直接应用于模型拟合的分类变量。我们需要对这个变量进行编码。
编码虚拟变量:
因为我们有一个不能直接应用到模型中的分类变量(state),所以我们将对它进行编码。要将分类变量编码为数字,我们将使用LabelEncoder类。但这是不够的,因为它仍然有一些关系顺序,这可能会创建一个错误的模型。为了解决这个问题,我们将使用OneHotEncoder,它将创建虚拟变量。下面是它的代码:
#Catgorical data
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
labelencoder_x= LabelEncoder()
x[:,3]= labelencoder_x.fit_transform(x[:,3])
onehotencoder= OneHotEncoder(categorical_features= [3])
x= onehotencoder.fit_transform(x).toarray()在这里,我们仅编码一个独立变量,该变量是state其它变量是连续的。
输出:
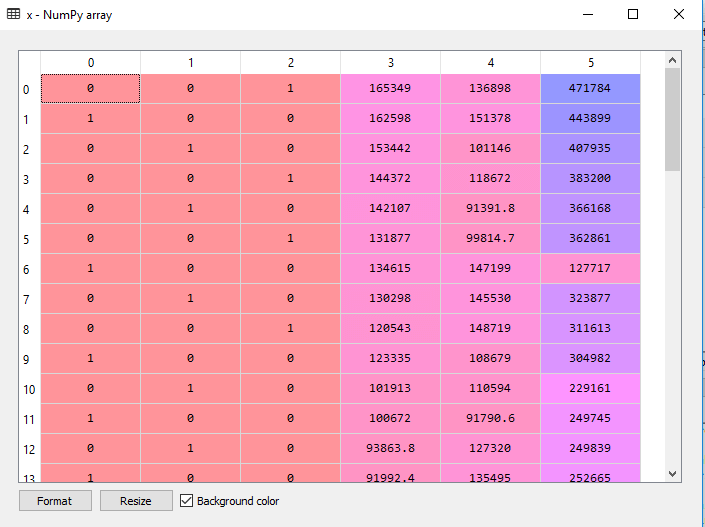
从上面的输出中可以看出,state列已经被转换为哑变量(0和1),这里每个哑变量列对应一个状态。我们可以通过与原始数据集进行比较来进行检查。第一列对应加利福尼亚州,第二列对应佛罗里达州,第三列对应纽约州。
注意:我们不应该同时使用所有的虚拟变量,所以必须比虚拟变量的总数少1,否则会产生一个虚拟变量陷阱。
- 现在,我们正在编写一行代码,只是为了避免虚拟变量陷阱:
#avoiding the dummy variable trap:
x = x[:,1:]如果我们不删除第一个虚拟变量,那么它可能在模型中引入多重共线性。
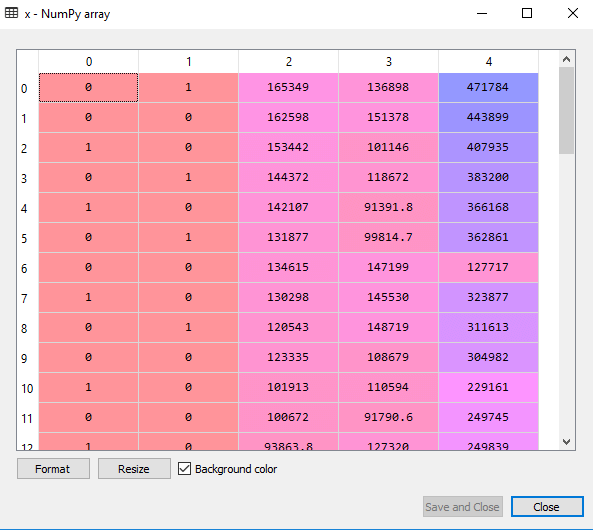
正如我们可以在上述输出图像中看到的,在第一列已经被移除。
- 现在,我们将数据集分成训练和测试集。这样做的代码下面给出:
# Splitting the dataset into training and test set.
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test= train_test_split(x,y,test_size= 0.2,random_state=0)上面的代码将我们的数据集分成训练集和测试集。
输出:上面的代码将数据集分割为训练集和测试集。你可以通过点击Spyder的IDE给出的可变资源管理器选项检查输出。测试集和训练集看起来像下面的图片:
测试集:
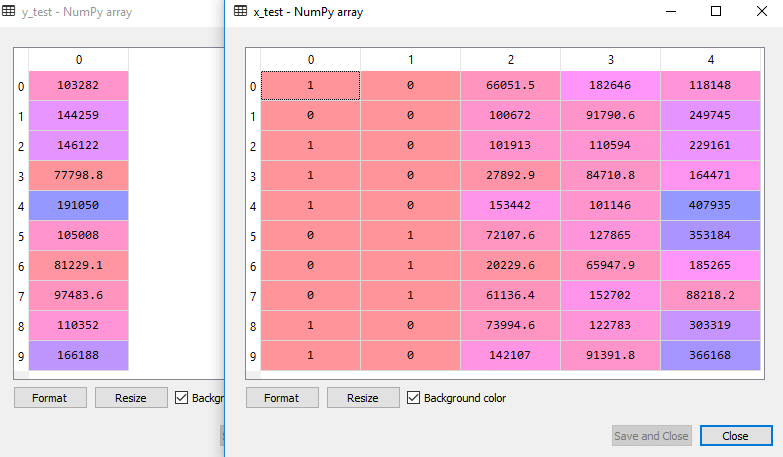
训练集:

注:在MLR中,我们不做特性扩展,因为它是由库来处理的,所以我们不需要手动操作。。
步骤2:拟合我们的MLR模型训练集:
现在,为了提供训练,我们已经准备好了我们的数据集,这意味着我们将把我们的回归模型放入训练集。它将与我们在简单线性回归模型中所做的类似。这个的代码是:
#Fitting the MLR model to the training set:
from sklearn.linear_model import LinearRegression
regressor= LinearRegression()
regressor.fit(x_train,y_train)输出:
Out[9]: LinearRegression(copy_X=True,fit_intercept=True,n_jobs=None,normalize=False)现在,我们已经成功地使用训练数据集训练了我们的模型。在下一步中,我们将使用测试数据集测试模型的性能。
步骤3:预测检验的结果集:
我们的模型的最后一步是检查模型的性能。我们将通过预测测试集的结果来做到这一点。对于预测,我们将创建一个y_pred向量。下面是它的代码:
#Predicting the Test set result;
y_pred= regressor.predict(x_test)通过执行上述代码行,将在可变资源管理器选项下生成一个新向量。我们可以通过比较预测值和测试集值来测试我们的模型。。
输出:

在上面的输出中,我们已经有了预测结果集和测试集。我们可以通过对这两个值的索引逐个进行比较来检查模型的性能。例如,第一个索引的预测值是103015$ profit,测试/实际值是103282$ profit。差异只有267美元,这是一个很好的预测,所以,最后,我们的模型在这里完成。
- 我们还可以检查训练数据集和测试数据集的成绩。下面是它的代码:
print('Train Score: ',regressor.score(x_train,y_train))
print('Test Score: ',regressor.score(x_test,y_test))输出:比分是:
Train Score: 0.9501847627493607
Test Score: 0.9347068473282446以上分数表明,我们的模型对训练数据集的准确率为95%,对测试数据集的准确率为93%。
注意:在下一个主题中,我们将看到如何使用逆向消除过程来改进模型的性能。
多元线性回归的应用:
多元线性回归主要有两种应用:
- 自变量对预测的有效性:
- 预测变化的影响:
评论前必须登录!
注册