 srcmini
srcmini本文概述
两年来, 作为srcmini的重度用户, 我学到了很多东西。我的主要业务是在线营销, 从中学到的数据科学技能中我受益匪浅。现在, 我可以管理规模更大, 更复杂的广告系列, 并有效地进行维护。由于我现在对R和Python中的内容以及不同的主题和程序包非常熟悉, 因此我思考如何像练习一样为srcmini创建搜索活动。
在本教程中, 你将解决以下主题:
- 你将首先了解有关搜索引擎营销(SEM)和搜索广告系列的更多信息;
- 然后, 你将仔细研究当前的业务案例。
- 接下来, 你将为srcmini的讲师, 技术, 课程和主题生成关键字。
- 有了关键字, 你就可以开始制作广告。首先, 你需要提出一个策略, 然后你可以开始创建广告模板。
搜索引擎营销(SEM)和广告系列
什么是SEM?
SEM是在竞争日益激烈的市场中发展业务的最有效方法之一。这是通过在搜索引擎上购买广告来获得网站流量的过程。 Google AdWords是最流行的在线广告形式之一:你在搜索引擎的赞助商链接中为与你的业务相关的关键字竞标广告展示位置, 然后你为每次点击支付搜索引擎费用。
每次点击付费可能会成为相当大的成本, 因此规划和组合关键字和广告非常重要, 这样你就可以控制成本, 并希望获得有利可图的广告系列。
尽管确定每次点击价格的确切过程是一个受严格保护的秘密, 并且取决于许多因素, 但主要思想是, 广告越相关, 每次点击费用就越低。
设置搜索广告系列
在设置广告系列之前, 通常会先提出预算, 选择关键字并查看竞争情况。另外, 你还要确保目标网页正确无误。然后, 你可以设置广告系列:你将编写第一个广告, 修复其详细信息, 然后设置转化跟踪。本教程将主要介绍根据我们拥有的不同目标网页生成大量关键字和广告的过程。
但是, 在开始之前, 让我们看一下这些搜索活动的确切含义!
广告群组
要开始使用搜索广告系列, 你首先需要为广告组制定计划。这是你映射关键字, 广告和登录页面的基本单位。但是这三个部分到底是什么?
- 关键字:用户的意图, 他们在寻找什么。
- 广告:你对用户的承诺。
- 登陆页面:你兑现的承诺。
正确映射这三个元素大约占工作量的70-80%。如果你做对了, 维护和更改将变得更加容易。
这意味着, 为了特定于用户并与用户相关, 你需要推广所拥有的产品, 并且主要集中在通过正确的消息或期望将正确的人发送到正确的页面。良好的广告活动结构可以反映并遵循网站的结构, 该结构实质上反映了业务策略。
请注意, 每个广告组都必须属于广告系列。在广告系列一级, 你拥有用于控制广告系列中所有广告组的设置, 例如语言定位, 位置, 设备, 一天中的时间等。
搜索广告系列, 分步进行
在上一节中, 你从较高的角度查看了搜索广告系列:你看到关键字, 广告和着陆页是广告组的一部分, 并且需要为你要映射的这个基本单位部门制定一个计划这三个组件以反映你的业务策略的方式。在本节中, 你将深入研究如何制作广告系列, 重点关注本教程中要执行的步骤。
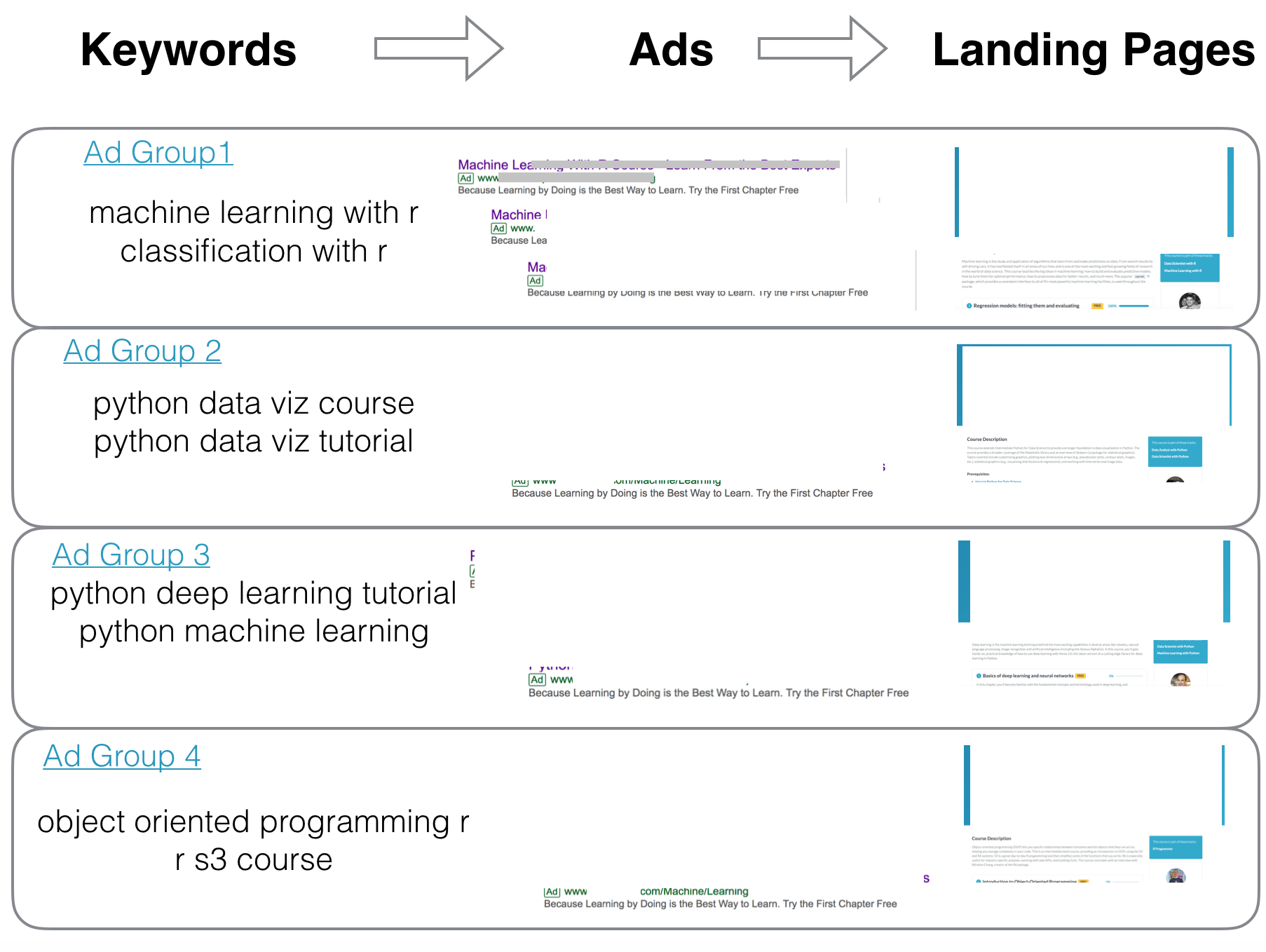
如上所示, 这是你要实现的映射。作为输出, 你最终希望拥有两个主要的DataFrame:一个用于关键字, 另一个用于广告。你可以在下面看到它的样子。
| 关键词 | ||
|---|---|---|
| 运动 | 广告群组 | 关键词 |
| 广告活动1 | 广告组1 | 关键字1 |
| 广告活动1 | 广告组2 | 关键字2 |
| 广告活动2 | 广告组1 | 关键字3 |
| 广告活动2 | 广告组1 | 关键字4 |
| 广告活动2 | 广告组2 | 关键字5 |
| 广告 | |||||
|---|---|---|---|---|---|
| 运动 | 广告群组 | 显示网址 | 最终网址 | 标题1 | 标题2 |
| 广告活动1 | 广告组1 | srcmini02.com | srcmini02.com/a | 标题1 | 标题1a |
| 广告活动1 | 广告组2 | srcmini02.com | srcmini02.com/b | 标题1 | 标题1a |
| 广告活动2 | 广告组1 | srcmini02.com | srcmini02.com/c | 标题1 | 标题1a |
| 广告活动2 | 广告组2 | srcmini02.com | srcmini02.com/d | 标题2 | 标题2a |
| 广告活动2 | 广告组3 | srcmini02.com | srcmini02.com/e | 标题3 | 标题1a |
完成这些操作后, 你就可以将其作为逗号分隔值(CSV)文件上传到Google AdWords或其他工作原理完全相同的平台。除Bing Ads, Yandex, Baidu等公司外, Google AdWords是迄今为止搜索营销商最流行的付费搜索平台。
请注意, 如果你想将数据导入其他平台而不是Google Adwords或Bing Ads, 则需要做一些细微的调整!
商业案例:srcmini
在阅读简介时, 你想为srcmini创建搜索广告系列。查看某人对公司提供的产品表达兴趣的不同方式, 即数据科学教育, 你可以轻松地列出其中一些方式的初始清单:
- 讲师:” Hadley Wickham课程”, ” Garrett Grolemund课程”等。
- 技术:” python课程”, ” r课程”, ” sql数据科学课程”等。
- 课程:我们拥有的特定课程的名称; “在python中进行无监督学习”, “在python中进行深度学习”等。
- 主题:”机器学习课程”, “数据可视化课程”等
- 包/库:”学习ggplot”, ” matplotlib教程”等。
在本教程中, 你不会进入传统的关键字研究阶段, 这是因为你拥有编程语言的能力, 可以生成所有可能的组合并将它们组合在各自的广告系列和广告组中。
因此, 你需要了解两个主要事项来进行此设置:
- 产品知识:了解srcmini拥有哪些课程和主题, 如何在网站上组织它们以及如何对其进行分组。你可以通过浏览找到答案, 当然可以通过内部知识获得更好的见解(尤其是计划中的更改!)。
- 相关关键字:某人在你提供的东西中表达欲望的所有可能方式。在srcmini的情况下, 这就是”课程”, “学习”, “教育”, “教程”等。你可以通过集思广益, 研究关键字工具和其他方法来做到这一点。
搜寻引擎营销活动的关键字产生
让我们从生成关键字开始!
1.生成教师关键字
该活动将针对那些由srcmini的任何教师搜索课程的人员。
你可以将关键字限制为”按<教师姓名>的课程”, 也可以仅针对教师姓名使用一系列广泛的关键字。刚开始时, 最好以”课程”或”课程”作为目标名称并查看效果。
你还需要检查你拥有的任何一个名称是否也恰好是另一个名人的名称, 或者是一个非常普通的名称, 然后你将需要限制该教师的关键字。
首先获取讲师的姓名和每个人的URL:
import requests
from bs4 import BeautifulSoup
instructors_page = 'https://www.srcmini02.com/instructors?all=true'
instructor_link_selector = '.instructor-block__description .instructor-block__link' # CSS class of the link
instructor_name_selector = '.mb-sm' # CSS class of the name
instructor_resp = requests.get(instructors_page)
soup = BeautifulSoup(instructor_resp.text, 'lxml')
instructor_urls = [url['href'] for url in soup.select(instructor_link_selector)]
instructor_names = [name.text.strip() for name in soup.select(instructor_name_selector)]
instructor_urls = ['https://www.srcmini02.com' + url for url in instructor_urls]
你将它们放在DataFrame中以备后用。这些网址将在以后用于生成广告。
instructor_df = pd.DataFrame({
'name': instructor_names, 'url': instructor_urls
})
print(instructor_df.shape)
instructor_df.head()
(72, 2)
| 名称 | 网址 | |
|---|---|---|
| 0 | 菲利普·舒文纳斯 | https://www.srcmini02.com/instructors/filipsch |
| 1 | 乔纳森·科尼利森(Jonathan Cornelissen) | https://www.srcmini02.com/instructors/jonathana… |
| 2 | 雨果·鲍恩·安德森 | https://www.srcmini02.com/instructors/hugobowne |
| 3 | 格雷格·威尔逊 | https://www.srcmini02.com/instructors/greg48f64… |
| 4 | 尼克·卡迪(Nick Carchedi) | https://www.srcmini02.com/instructors/nickyc |
现在你有了讲师的姓名, 你将使用一个模板, 该模板将每个姓名与与你的主题相关的一组关键字结合在一起, 这些主题主要是讲师的课程。
以下代码中使用的变量:
col_names:这是表格的标题名称的列表, 我们最后将其上传到Google AdWords。
单词:你将要与教师姓名组合的单词, 以生成完整的关键字/词组。
match_types:有关更多详细信息, 请参见AdWords帮助中心, 但这是基础知识。
[数据科学课程], “数据科学课程”和数据科学课程在技术上是三个不同的关键字。
- 完全匹配(位于方括号中)仅在用户完全按照该关键字搜索”数据科学课程”这一关键字时才触发广告。
- 词组匹配(带引号), 如果用户搜索确切的字符串以及前后的所有字符串, 则会触发你的广告。因此, “最佳数据科学课程”或”在线数据科学课程”将触发我们的广告。
- 如果有人搜索与”数据科学课程”相似或相关的内容, 则广泛匹配(无标点符号)将触发我们的广告。这取决于Google的算法, 你必须谨慎使用它, 因为例如当有人搜索”数据科学平台”时, 它可能会触发广告, 这并非我们要推广的。我喜欢更多地使用修改后的匹配匹配, 因为它限制了定位的范围。如果有人搜索该词的任何派生词, 而不是任何含义相近的词, 这基本上是在触发广告。在单词开头以” +”号表示。因此, ” +游戏”将通过”游戏”, “游戏者”而非”游戏”触发广告。
col_names = ['Campaign', 'Ad Group', 'Keyword', 'Criterion Type']
instructor_keywords = []
words = ['course', 'courses', 'learn', 'data science', 'data camp', 'srcmini']
match_types = ['Exact', 'Phrase', 'Broad']
for instructor in instructor_df['name']:
for word in words:
for match in match_types:
if match == 'Broad':
keyword = '+' + ' +'.join([instructor.replace(' ', ' +').lower(), word]) # modified broach match
else:
keyword = instructor.lower() + ' ' + word
row = ['SEM_Instructors', # campaign name
instructor, # ad group name
keyword, # instructor <keyword>
match] # keyword match type
instructor_keywords.append(row)
# do the same by having the keywords come before the instructor name
for instructor in instructor_df['name']:
for word in words:
for match in match_types:
if match == 'Broad':
keyword = '+' + ' +'.join([word, instructor.replace(' ', ' +').lower()])
else:
keyword = word + ' ' + instructor.lower()
row = ['SEM_Instructors', # campaign name
instructor, # ad group name
keyword, # <keyword> instructor
match] # keyword match type
instructor_keywords.append(row)
instructor_keywords_df = pd.DataFrame.from_records(instructor_keywords, columns=col_names)
print('total keywords:', instructor_keywords_df.shape[0])
instructor_keywords_df.head()
total keywords: 2592
| 运动 | 广告群组 | 关键词 | 标准类型 | |
|---|---|---|---|---|
| 0 | SEM_讲师 | 菲利普·舒文纳斯 | 检验课程 | 精确 |
| 1 | SEM_讲师 | 菲利普·舒文纳斯 | 检验课程 | 短语 |
| 2 | SEM_讲师 | 菲利普·舒文纳斯 | +菲律宾+坦率+课程 | 宽 |
| 3 | SEM_讲师 | 菲利普·舒文纳斯 | 检验课程 | 精确 |
| 4 | SEM_讲师 | 菲利普·舒文纳斯 | 检验课程 | 短语 |
基本上, 你正在做的是遍历教师姓名, 所有不同的关键字以及我们拥有的所有匹配类型, 以便我们拥有所有可能的组合。我们要做两次, 一次是使用模板”教师姓名关键字”和”关键字教师姓名”。
现在, 你只需对关键字以及我们如何提取数据进行少量修改即可对所有细分重复相同的操作。
我从R for Data Science中学到的一个很好的指导原则是, 如果你要复制和粘贴两次以上, 那么该编写函数了!
def generate_keywords(topics, keywords, match_types=['Exact', 'Phrase', 'Broad'], campaign='SEM_Campaign'):
col_names = ['Campaign', 'Ad Group', 'Keyword', 'Criterion Type']
campaign_keywords = []
for topic in topics:
for word in keywords:
for match in match_types:
if match == 'Broad':
keyword = '+' + ' +'.join([topic.lower().replace(' ', ' +'), word.replace(' ', ' +')])
else:
keyword = topic.lower() + ' ' + word
row = [campaign, # campaign name
topic, # ad group name
keyword, # instructor <keyword>
match] # keyword match type
campaign_keywords.append(row)
# I said more than twice! :)
for topic in topics:
for word in keywords:
for match in match_types:
if match == 'Broad':
keyword = '+' + ' +'.join([word.replace(' ', ' +'), topic.lower().replace(' ', ' +')])
else:
keyword = word + ' ' + topic.lower()
row = [campaign, # campaign name
topic, # ad group name
keyword, # <keyword> instructor
match] # keyword match type
campaign_keywords.append(row)
return pd.DataFrame.from_records(campaign_keywords, columns=col_names)
试一试吧:
topics = ['Data Science', 'Machine Learning']
keywords = ['course', 'tutorial']
generate_keywords(topics, keywords).head(10)
| 运动 | 广告群组 | 关键词 | 标准类型 | |
|---|---|---|---|---|
| 0 | SEM_Campaign | 数据科学 | 数据科学课程 | 精确 |
| 1 | SEM_Campaign | 数据科学 | 数据科学课程 | 短语 |
| 2 | SEM_Campaign | 数据科学 | +数据+科学+课程 | 宽 |
| 3 | SEM_Campaign | 数据科学 | 数据科学教程 | 精确 |
| 4 | SEM_Campaign | 数据科学 | 数据科学教程 | 短语 |
| 5 | SEM_Campaign | 数据科学 | +资料+科学+教学课程 | 宽 |
| 6 | SEM_Campaign | 机器学习 | 机器学习课程 | 精确 |
| 7 | SEM_Campaign | 机器学习 | 机器学习课程 | 短语 |
| 8 | SEM_Campaign | 机器学习 | +机器+学习+课程 | 宽 |
| 9 | SEM_Campaign | 机器学习 | 机器学习教程 | 精确 |
看起来不错现在, 让我们为你的每个细分生成相关的主题和关键字!
2.技术关键词
topics = ['R', 'Python', 'SQL', 'Git', 'Shell'] # listed on the /courses page
keywords = ['data science', 'programming', 'analytics', 'data analysis', 'machine learning', 'deep learning', 'financial analysis', 'data viz', 'visualization', 'data visualization', 'learn', 'course', 'courses', 'education', 'data import', 'data cleaning', 'data manipulation', 'probability', 'stats', 'statistics', 'course', 'courses', 'learn', 'education', 'tutorial'] # @marketing_team: this list can / should be refined or
# expanded based on the strategy and how specific the
# targeting needs to be
tech_keywords = generate_keywords(topics, keywords, campaign='SEM_Technologies')
print('total keywords:', tech_keywords.shape[0])
tech_keywords.head()
total keywords: 750
| 运动 | 广告群组 | 关键词 | 标准类型 | |
|---|---|---|---|---|
| 0 | SEM_技术 | [R | 数据科学 | 精确 |
| 1 | SEM_技术 | [R | 数据科学 | 短语 |
| 2 | SEM_技术 | [R | + R +数据+科学 | 宽 |
| 3 | SEM_技术 | [R | 编程 | 精确 |
| 4 | SEM_技术 | [R | 编程 | 短语 |
3.生成课程关键字
这可能是针对人群的最具体的细分市场, 因此也是最相关的细分受众群。如果某人正在搜索”使用r进行数据可视化”而srcmini拥有这门课程, 则该广告将非常相关, 因为你将拥有恰好满足用户需求的正确着陆页。
不过, 有一个小问题。有些课程名称与用户通常搜索的名称不符:”与专家进行机器学习:学校预算”, ” R中的情感分析:整洁的方式”。这些不是坏的课程名称, 但是在选择人们可能用来搜索它们的正确关键字时, 它们将需要注意。
同样, 你可以像在教师的活动中那样刮取名称和相应的URL:
courses_page = 'https://www.srcmini02.com/courses/all'
course_link_selector = '.courses__explore-list .course-block'
course_resp = requests.get(courses_page)
soup = BeautifulSoup(course_resp.text, 'lxml')
course_urls = [link.contents[1]['href'] for link in soup.select(course_link_selector)]
course_urls = ['https://www.srcmini02.com' + url for url in course_urls]
course_names = [link.h4.text for link in soup.select(course_link_selector)]
course_df = pd.DataFrame({
'name': course_names, 'url': course_urls
})
course_df['name_clean'] = course_df.name.str.replace('\(.*\)', '').str.strip() # remove (part x)
print('total keywords:', course_df.shape[0])
course_df.head()
total keywords: 104
| 名称 | 网址 | name_clean | |
|---|---|---|---|
| 0 | 数据科学Python简介 | https://www.srcmini02.com/courses/intro-to-pyth… | 数据科学Python简介 |
| 1 | R介绍 | https://www.srcmini02.com/courses/free-introduc… | R介绍 |
| 2 | 数据科学中级Python | https://www.srcmini02.com/courses/intermediate-… | 数据科学中级Python |
| 3 | 面向数据科学的Git简介 | https://www.srcmini02.com/courses/introduction-… | 面向数据科学的Git简介 |
| 4 | 中级R | https://www.srcmini02.com/courses/intermediate-r | 中级R |
你将对这些课程执行相同的操作(使用generate_keywords()函数), 但是你需要小心, 因为需要对其进行审核, 因为如上所述, 某些名称并不是人们真正想要的名称, 你只需根据具体情况进行说明。以下内容对于开始来说应该足够好, 然后你可以查看数据并做出决定。
请注意, 使用下面的空白字符不是错误。当然, 名称的名称足够长且足够具体, 以使其本身适合用作关键字, 而不必添加其他限定词, 例如” learn”或” course”。因此, 你将单独使用课程名称以及限定词。
keywords = ['', 'learn', 'course', 'courses', 'tutorial', 'education']
course_keywords = generate_keywords(course_df['name_clean'], keywords, campaign='SEM_Courses')
print('total keywords:', course_keywords.shape[0])
course_keywords.head(10)
total keywords: 3744
| 运动 | 广告群组 | 关键词 | 标准类型 | |
|---|---|---|---|---|
| 0 | SEM_课程 | 数据科学Python简介 | 数据科学python简介 | 精确 |
| 1 | SEM_课程 | 数据科学python简介 | 数据科学python简介 | 短语 |
| 2 | SEM_课程 | 数据科学python简介 | +介绍+ Python +数据+科学+ | 宽 |
| 3 | SEM_课程 | 数据科学python简介 | python简介以进行数据科学学习 | 精确 |
| 4 | SEM_课程 | 数据科学python简介 | python简介以进行数据科学学习 | 短语 |
| 5 | SEM_课程 | 数据科学python简介 | +介绍+ Python +数据+科学+学习 | 宽 |
| 6 | SEM_课程 | 数据科学python简介 | 数据科学课程的python简介 | 精确 |
| 7 | SEM_课程 | 数据科学python简介 | 数据科学课程的python简介 | 短语 |
| 8 | SEM_课程 | 数据科学python简介 | +简介+ Python +数据+科学+课程 | 宽 |
| 9 | SEM_课程 | 数据科学python简介 | 数据科学课程的python简介 | 精确 |
4.主题关键字
这些基本上是人们可能会感兴趣的通用主题。它们由”轨道”部分涵盖, 该部分将技能和职业作为子部分。为了你的目的, 可以将它们归为同一广告系列。就像你在前面各节中所做的一样, 过程再次相同!
技能专长
skills_page = 'https://www.srcmini02.com/tracks/skill'
skills_link_selector = '#all .shim'
skills_resp = requests.get(skills_page)
skill_soup = BeautifulSoup(skills_resp.text, 'lxml')
skills_urls = [link['href'] for link in skill_soup.select(skills_link_selector)]
skills_names = [skill.replace('/tracks/', '').replace('-', ' ') for skill in skills_urls]
skills_urls = ['https://www.srcmini02.com' + url for url in skills_urls]
招贤纳士
career_page = 'https://www.srcmini02.com/tracks/career'
career_link_selector = '#all .shim'
career_resp = requests.get(career_page)
career_soup = BeautifulSoup(career_resp.text, 'lxml')
career_urls = [link['href'] for link in career_soup.select(career_link_selector)]
career_names = [career.replace('/tracks/', '').replace('-', ' ') for career in career_urls]
career_urls = ['https://www.srcmini02.com' + url for url in career_urls]
tracks_df = pd.DataFrame({
'name': skills_names + career_names, 'url': skills_urls + career_urls
})
tracks_df['name'] = [x.title() for x in tracks_df['name']]
tracks_df.head()
| 名称 | 网址 | |
|---|---|---|
| 0 | R编程 | https://www.srcmini02.com/tracks/r-programming |
| 1 | 用R导入清洁数据 | https://www.srcmini02.com/tracks/importing-clea… |
| 2 | 使用R进行数据处理 | https://www.srcmini02.com/tracks/data-manipulat… |
| 3 | Python编程 | https://www.srcmini02.com/tracks/python-program… |
| 4 | 使用Python导入清洁数据 | https://www.srcmini02.com/tracks/importing-clea… |
tracks_keywords = generate_keywords(tracks_df['name'], keywords, campaign='SEM_Tracks')
print('total keywords:', tracks_keywords.shape[0])
tracks_keywords.head()
total keywords: 720
| 运动 | 广告群组 | 关键词 | 标准类型 | |
|---|---|---|---|---|
| 0 | SEM_Tracks | 编程 | 编程 | 精确 |
| 1 | SEM_Tracks | 编程 | 编程 | 短语 |
| 2 | SEM_Tracks | 编程 | + R +编程+ | 宽 |
| 3 | SEM_Tracks | 编程 | r编程学习 | 精确 |
| 4 | SEM_Tracks | 编程 | r编程学习 | 短语 |
最后, 你将教师_关键字, 技术关键字, 课程关键字和曲目关键字中列出的所有关键字连接起来, 以便将它们全部收集到一个大的DataFrame中:
full_keywords_df = pd.concat([instructor_keywords_df, tech_keywords, course_keywords, tracks_keywords])
print('total keywords:', full_keywords_df.shape[0])
print('total campaigns:', len(set(full_keywords_df['Campaign'])))
print('total ad groups:', len(set(full_keywords_df['Ad Group'])))
full_keywords_df.to_csv('keywords.csv', index=False)
full_keywords_df.head()
total keywords: 7806
total campaigns: 4
total ad groups: 191
| 运动 | 广告群组 | 关键词 | 标准类型 | |
|---|---|---|---|---|
| 0 | SEM_讲师 | 菲利普·舒文纳斯 | 检验课程 | 精确 |
| 1 | SEM_讲师 | 菲利普·舒文纳斯 | 检验课程 | 短语 |
| 2 | SEM_讲师 | 菲利普·舒文纳斯 | +菲律宾+坦率+课程 | 宽 |
| 3 | SEM_讲师 | 菲利普·舒文纳斯 | 检验课程 | 精确 |
| 4 | SEM_讲师 | 菲利普·舒文纳斯 | 检验课程 | 短语 |
现在, 你可以使用关键字了!如果要查看完整的数据集, 请在此处获取。接下来, 你需要为每个广告组生成广告。
让我们来生成广告。
广告生成和文案写作
你当前具有以下条件:
- 广告系列和广告组名称在full_keywords_df数据框中正确地相互映射
- 广告组名称和之前抓取的相应网址(课程, 讲师和曲目), 并且你需要为技术生成一个。
有了这个, 你可以遵循以下计划:
创建要使用的广告模板(开始时应该使用2-3个)
创建一个Campaign列并将其添加到(‘name’, ‘url’)DataFrames中
将所有(‘name’, ‘url’)数据框合并为一个大文件
为所有广告组生成所有广告;每个广告均包含以下字段(这些字段是你正在使用的同一DataFrame中的新列):
- 标题1:最多30个字符
- 标题2:最多30个字符
- 显示网址:从最终网址自动推断
- 最终到达网址:用户最终到达的完整路径(必须与显示网址位于同一域中
确保工作与关键字DataFrame一致
上传并启动广告系列!
生成广告仅意味着替换模板中所属主题名称(课程, 技术, 讲师等), 并为你拥有的每个广告组制作2-3个广告变体。

广告范本
需要注意的重要一点是, 尽管插入广告组名称所属的广告组是一个简单的过程, 但问题是你需要使字段的长度在上述限制范围内。而且, 由于你的课程和主题的名称相差很大, 因此你需要查看可以采取的措施。
让我们看看有多少个问题是:
%matplotlib inline
import matplotlib.pyplot as plt
adgroup_lengths = pd.Series([len(adgrp) for adgrp in full_keywords_df['Ad Group'].unique()])
long_adgroups = sum(adgroup_lengths > 30)
plt.figure(figsize=(9, 6))
plt.hist(adgroup_lengths, rwidth=0.9, bins=50)
plt.vlines(x=30, ymin=0, ymax=10, colors='red')
plt.title(str(long_adgroups) + ' ad group name lenghts > 30 (don\'t fit in a headline)', fontsize=17)
plt.xlabel('Ad Group Name Lengths', fontsize=15)
plt.ylabel('Count', fontsize=15)
plt.yticks(range(11))
plt.xticks(range(0, 51, 5))
plt.grid(alpha=0.5)
plt.show()

看来你的问题不是小问题, 也没有直接的解决方法。理想情况下, 你希望两个标题包含我们要推广的产品(课程)的完整标题。
我想到了不同的解决方法, 因此决定编写一个简单的算法, 将名称分成两个词组, 每个词组最多包含30个字符。
该算法不适合常规使用, 需要进行一些调整才能使其通用, 但是对于此数据集, 它的效果很好:
def split_string(string, splits=2, max_len=60):
"""Split `string` into `splits` words, each shorter than `max_len` / `splits`"""
if len(string) < max_len / splits:
return string, ''
str_words = string.split(' ')
result = ''
for i, word in enumerate(str_words):
if len(result + ' ' + word) <= max_len / splits:
result += word + ' '
else:
break
spaces = result.strip().count(' ')
result2 = string[string[len(result):].index(word) + len(result):]
return result.strip(), result2
print(split_string('this is a very long course name that needs splitting', 2, 60))
print(split_string('short course name', 2, 60))
('this is a very long course', 'name that needs splitting')
('short course name', '')
我通常不会这样做, 但是我喜欢这种技术, 我想在制作其他广告系列时会使用它。这是编写教程的一个不错的副作用!
现在, 让我们考虑一下你要编写的模板。
我使用的常规广告模板包含以下元素(通常按此顺序)。
- 产品:如果我正在Google上搜索”数据科学课程”, 则需要在某处的链接/广告中看到”数据科学课程”。
- 好处:这是人们真正追求的情感/心理事情, 而不仅仅是完成课程, “提升职业生涯”, “从人群中脱颖而出”。
- 特点:现在, 你已经向我许诺了月亮, 请告诉我你将如何到达那里! “超过100项数据科学课程”, “向顶尖专家学习”, “获得有关你的编码技能的即时反馈”。
- 呼吁采取行动:好的, 所以你告诉了我拥有的东西, 激发了我去购买它的权利, 并向我展示了我将如何到达那里。我卖了现在我该怎么做? “免费注册试用”, “免费试用第一章”, “每年订阅可节省20%”
将所有这些都放到一条长鸣叫的广告中并不容易, 其中有些可能会重叠。但是, 你会尽力而为。
- 标题1:这将始终包含课程名称(或前半部分)。
- 标题2:课程名称的后半部分, 或以下内容之一:
- 促进你的数据科学职业
- 在人群中脱颖而出
- 解决复杂的问题
- 说明:每个广告组下面都有三个变体, 它们将轮流展示。
- 直接向该领域的顶级专家学习。年度订阅可享受20%的折扣
- 掌握曲线, 掌握数据科学技能。 $ 29 /月。随时取消
- 从世界上最好的主题中选择各种各样的主题。现在开始
创建广告系列列
full_keywords_df.Campaign.unique() # just to make sure you have consistent naming conventions
array(['SEM_Instructors', 'SEM_Technologies', 'SEM_Courses', 'SEM_Tracks'], dtype=object)
course_df['Campaign'] = 'SEM_Courses'
course_df = course_df.rename(columns={'name_clean': 'name', 'name': 'old_name'})
course_df.head()
| old_name | 网址 | 名称 | 运动 | |
|---|---|---|---|---|
| 0 | 数据科学Python简介 | https://www.srcmini02.com/courses/intro-to-pyth… | 数据科学Python简介 | SEM_课程 |
| 1 | R介绍 | https://www.srcmini02.com/courses/free-introduc… | R介绍 | SEM_课程 |
| 2 | 数据科学中级Python | https://www.srcmini02.com/courses/intermediate-… | 数据科学中级Python | SEM_课程 |
| 3 | 面向数据科学的Git简介 | https://www.srcmini02.com/courses/introduction-… | 面向数据科学的Git简介 | SEM_课程 |
| 4 | 中级R | https://www.srcmini02.com/courses/intermediate-r | 中级R | SEM_课程 |
instructor_df['Campaign'] = 'SEM_Instructors'
instructor_df.head()
| 名称 | 网址 | 运动 | |
|---|---|---|---|
| 0 | 菲利普·舒文纳斯 | https://www.srcmini02.com/instructors/filipsch | SEM_讲师 |
| 1 | 乔纳森·科尼利森(Jonathan Cornelissen) | https://www.srcmini02.com/instructors/jonathana… | SEM_讲师 |
| 2 | 雨果·鲍恩·安德森 | https://www.srcmini02.com/instructors/hugobowne | SEM_讲师 |
| 3 | 格雷格·威尔逊 | https://www.srcmini02.com/instructors/greg48f64… | SEM_讲师 |
| 4 | 尼克·卡迪(Nick Carchedi) | https://www.srcmini02.com/instructors/nickyc | SEM_讲师 |
tracks_df['Campaign'] = 'SEM_Tracks'
tracks_df.head()
| 名称 | 网址 | 运动 | |
|---|---|---|---|
| 0 | 编程 | https://www.srcmini02.com/tracks/r-programming | SEM_Tracks |
| 1 | 用R导入清洁数据 | https://www.srcmini02.com/tracks/importing-clea… | SEM_Tracks |
| 2 | 使用R进行数据处理 | https://www.srcmini02.com/tracks/data-manipulat… | SEM_Tracks |
| 3 | Python编程 | https://www.srcmini02.com/tracks/python-program… | SEM_Tracks |
| 4 | 使用Python导入清洁数据 | https://www.srcmini02.com/tracks/importing-clea… | SEM_Tracks |
tech_domain = 'https://www.srcmini02.com/courses/tech:'
tech_domain_list = []
for tech in ['R', 'Python', 'SQL', 'Git', 'Shell']:
tech_domain_list.append((tech, tech_domain + tech))
tech_df = pd.DataFrame.from_records(tech_domain_list, columns=['name', 'url'])
tech_df['Campaign'] = 'SEM_Technologies'
tech_df
| 名称 | 网址 | 运动 | |
|---|---|---|---|
| 0 | [R | https://www.srcmini02.com/courses/tech:R | SEM_技术 |
| 1 | python | https://www.srcmini02.com/courses/tech:Python | SEM_技术 |
| 2 | SQL | https://www.srcmini02.com/courses/tech:SQL | SEM_技术 |
| 3 | 去 | https://www.srcmini02.com/courses/tech:Git | SEM_技术 |
| 4 | 贝壳 | https://www.srcmini02.com/courses/tech:Shell | SEM_技术 |
合并所有(‘name’, ‘url’)数据框
full_ads_df = pd.concat([course_df[['Campaign', 'name', 'url']], instructor_df, tracks_df, tech_df], ignore_index=True)
full_ads_df = full_ads_df.rename(columns={'name': 'Ad Group', 'url': 'Final URL'})
print('total rows:', full_ads_df.shape[0])
n_adgroups = full_ads_df.shape[0]
full_ads_df.head()
total rows: 201
| 运动 | 广告群组 | 最终网址 | |
|---|---|---|---|
| 0 | SEM_课程 | 数据科学python简介 | https://www.srcmini02.com/courses/intro-to-pyth… |
| 1 | SEM_课程 | R介绍 | https://www.srcmini02.com/courses/free-introduc… |
| 2 | SEM_课程 | 数据科学中级Python | https://www.srcmini02.com/courses/intermediate-… |
| 3 | SEM_课程 | 面向数据科学的Git简介 | https://www.srcmini02.com/courses/introduction-… |
| 4 | SEM_课程 | 中级R | https://www.srcmini02.com/courses/intermediate-r |
产生广告
只是为了跟踪你的位置。现在, 你的广告数据框包含正确映射的广告系列, 广告组和最终到达网址列。你需要添加标题1, 标题2和描述字段。
请记住, 对于每个广告组, 你将添加三个不同的广告变体。这是一个很好的做法, 主要用于测试目的, 例如查看用户点击的内容, 哪些广告可以带来更多转化等。你最终应获得一个DataFrame, 其数据行的数量是当前行的三倍。
首先, 在full_ads_df中将每行复制三遍:
full_ads_df = full_ads_df.iloc[[x for x in range(n_adgroups) for i in range(3)], :]
print('total rows:', full_ads_df.shape[0])
full_ads_df.head(9)
total rows: 603
| 运动 | 广告群组 | 最终网址 | |
|---|---|---|---|
| 0 | SEM_课程 | 数据科学python简介 | https://www.srcmini02.com/courses/intro-to-pyth… |
| 0 | SEM_课程 | 数据科学python简介 | https://www.srcmini02.com/courses/intro-to-pyth… |
| 0 | SEM_课程 | 数据科学python简介 | https://www.srcmini02.com/courses/intro-to-pyth… |
| 1 | SEM_课程 | R介绍 | https://www.srcmini02.com/courses/free-introduc… |
| 1 | SEM_课程 | R介绍 | https://www.srcmini02.com/courses/free-introduc… |
| 1 | SEM_课程 | R介绍 | https://www.srcmini02.com/courses/free-introduc… |
| 2 | SEM_课程 | 数据科学中级Python | https://www.srcmini02.com/courses/intermediate-… |
| 2 | SEM_课程 | 数据科学中级Python | https://www.srcmini02.com/courses/intermediate-… |
| 2 | SEM_课程 | 数据科学中级Python | https://www.srcmini02.com/courses/intermediate-… |
现在, 你添加上面创建的三个不同的描述。
Description = [
'Learn Directly From the Top Experts in the Field. 20% off Annual Subcriptions', 'Be Ahead of the Curve, Master Data Science Skills. $29 / Month. Cancel Anytime', 'Choose From a Wide Variety of Topics Tuaght by the Best in the World. Start Now'
]
Description = [x for i in range(n_adgroups) for x in Description ]
full_ads_df['Description'] = Description
full_ads_df.head()
| 运动 | 广告群组 | 最终网址 | 描述 | |
|---|---|---|---|---|
| 0 | SEM_课程 | 数据科学python简介 | https://www.srcmini02.com/courses/intro-to-pyth… | 直接向国际顶尖的专家学习… |
| 0 | SEM_课程 | 数据科学python简介 | https://www.srcmini02.com/courses/intro-to-pyth… | 领先于曲线, Master Data Science Ski … |
| 0 | SEM_课程 | 数据科学python简介 | https://www.srcmini02.com/courses/intro-to-pyth… | 从…中选择各种各样的话题 |
| 1 | SEM_课程 | R介绍 | https://www.srcmini02.com/courses/free-introduc… | 直接向国际顶尖的专家学习… |
| 1 | SEM_课程 | R介绍 | https://www.srcmini02.com/courses/free-introduc… | 领先于曲线, Master Data Science Ski … |
接下来, 将标题1和标题2添加到DataFrame。你几乎已经完成!
benefits = [
'Boost Your Data Science Career', 'Stand Out From the Crowd', 'Tackle Complex Questions'
]
如果广告组的长度小于或等于30, 则这些好处将包含在标题2中。在这种情况下, 你将有一个空字段, 将使用其中的一项福利来填充该字段。
benefits = [x for i in range(n_adgroups) for x in benefits]
headlines = [split_string(x) for x in full_ads_df['Ad Group']]
full_ads_df['Headline 1'] = [x[0] for x in headlines]
full_ads_df['Headline 2'] = [x[1] if x[1] else benefits[i] for i, x in enumerate(headlines)]
print('total ads:', full_ads_df.shape[0])
full_ads_df.head(9)
total ads: 603
| 运动 | 广告群组 | 最终网址 | 描述 | 标题1 | 标题2 | |
|---|---|---|---|---|---|---|
| 0 | SEM_课程 | 数据科学python简介 | https://www.srcmini02.com/courses/intro-to-pyth… | 直接向国际顶尖的专家学习… | Python资料简介 | 科学 |
| 0 | SEM_课程 | 数据科学python简介 | https://www.srcmini02.com/courses/intro-to-pyth… | 领先于曲线, Master Data Science Ski … | Python资料简介 | 科学 |
| 0 | SEM_课程 | 数据科学python简介 | https://www.srcmini02.com/courses/intro-to-pyth… | 从…中选择各种各样的话题 | Python资料简介 | 科学 |
| 1 | SEM_课程 | R介绍 | https://www.srcmini02.com/courses/free-introduc… | 直接向国际顶尖的专家学习… | R介绍 | 促进你的数据科学职业 |
| 1 | SEM_课程 | R介绍 | https://www.srcmini02.com/courses/free-introduc… | 领先于曲线, Master Data Science Ski … | R介绍 | 在人群中脱颖而出 |
| 1 | SEM_课程 | R介绍 | https://www.srcmini02.com/courses/free-introduc… | 从…中选择各种各样的话题 | R介绍 | 解决复杂的问题 |
| 2 | SEM_课程 | 数据科学中级Python | https://www.srcmini02.com/courses/intermediate-… | 直接向国际顶尖的专家学习… | 数据的中级Python | 科学 |
| 2 | SEM_课程 | 数据科学中级Python | https://www.srcmini02.com/courses/intermediate-… | 领先于曲线, Master Data Science Ski … | 数据的中级Python | 科学 |
| 2 | SEM_课程 | 数据科学中级Python | https://www.srcmini02.com/courses/intermediate-… | 从…中选择各种各样的话题 | 数据的中级Python | 科学 |
如你所见, ” Python for Data Science入门”足够长, 可以容纳两个领域, 因此请保持原样以使其清晰。在第二种情况下, ” Introduction to R”适合第一个标题, 因此你插入在标题2中创建的三个不同的好处。
大功告成!
仔细检查详细信息
快速检查一下, 以确保两个DataFrame中的所有广告系列和广告组名称都相同。
ads_check = (full_ads_df[['Campaign', 'Ad Group']]
.drop_duplicates()
.sort_values(['Campaign', 'Ad Group'])
.reset_index(drop=True))
keywords_check = (full_keywords_df[['Campaign', 'Ad Group']]
.drop_duplicates()
.sort_values(['Campaign', 'Ad Group'])
.reset_index(drop=True))
all(ads_check == keywords_check)
True
full_ads_df.to_csv('ads.csv', index=False)
上传并启动
如前所述, 本教程仅涵盖SEM广告系列中的特定步骤, 因此需要对搜索引擎营销的工作原理有基本的了解。如果你想了解更多有关上传和启动广告组的方法和详细信息, 可以查阅AdWords指南以开始使用。要访问不同领域的全部课程, 可以查看Google Academy for Ads。
数据科学和SEM:还有更多发现!
现在有了两个CSV文件, 你可以上传它们并开始运行广告系列。你将需要设置每日预算, 地理位置定位和其他一些参数, 但是在大多数情况下, 你还是可以这么做的。
如果要签出CSV文件, 可以在以下位置找到它们:
- 关键字
- 广告
我希望你觉得本教程有用。感谢你的阅读, 如果你想分享在Python的帮助下所做的任何增长项目, 请随时通过Twitter @eliasdabbas与我联系。
评论前必须登录!
注册