 srcmini
srcmini本文概述
- 卷积神经网络:简介
- Fashion-MNIST数据集
- 加载数据
- 分析数据
- 数据预处理
- 网络
- 建模数据
- 神经网络架构
- 编译模型
- 训练模型
- 测试集上的模型评估
- 将Dropout添加到网络
- 测试集上的模型评估
- 预测标签
- 分类报告
- 走得更远!
你可能已经听说过图像或面部识别或自动驾驶汽车。这些是卷积神经网络(CNN)的实际实现。在此博客文章中, 你将学习并了解如何在Keras中实现这些深层的前馈人工神经网络, 并学习如何使用称为”辍学”的正则化技术来克服过度拟合。
更具体地说, 你将在本教程中解决以下主题:
- 将向你介绍卷积神经网络。
- 然后, 你将首先尝试了解数据。你将使用Python及其库来加载, 浏览和分析数据,
- 之后, 你将预处理数据:将学习如何调整大小, 重新缩放, 将标签转换为一键编码矢量, 以及如何在训练和验证集中拆分数据。
- 完成所有这些步骤后, 你可以构建神经网络模型:你将学习如何对数据建模并形成网络。接下来, 你将编译, 训练和评估模型, 可视化准确性和损失图;
- 然后, 你将了解过度拟合的概念以及如何通过添加辍学层来克服它。
- 利用此信息, 你可以重新访问原始模型并重新训练模型。你还将重新评估新模型并比较两个模型的结果;
- 接下来, 你将对测试数据进行预测, 将概率转换为类标签, 并绘制一些模型正确分类和分类错误的测试样本;
- 最后, 你将可视化分类报告, 这将使你更直观地了解模型已正确分类了哪个类。
你想参加有关Keras和Python深度学习的课程吗?考虑参加srcmini的Python深度学习课程!
另外, 请不要错过我们的Keras备忘单, 它通过代码示例向你展示了在Python中构建神经网络所需要经历的六个步骤!
卷积神经网络:简介
到目前为止, 你可能已经了解机器学习和深度学习, 这是一个计算机科学分支, 专门研究可以学习的算法的设计。深度学习是机器学习的一个子领域, 受到人工神经网络的启发, 而人工神经网络又受到了生物神经网络的启发。
这种深层神经网络的一种特殊类型是卷积网络, 通常称为CNN或ConvNet。这是一个深层的前馈人工神经网络。请记住, 前馈神经网络也称为多层感知器(MLP), 这是典型的深度学习模型。这些模型被称为”前馈”, 因为信息从模型中流过。没有将模型的输出反馈到自身的反馈连接。
CNN特别是受到生物视觉皮层的启发。皮质的细胞区域很小, 对视野的特定区域敏感。 1962年, Hubel和Wiesel进行了一次引人入胜的实验, 扩大了这个想法(如果你想了解更多信息, 请观看下面的视频)。在该实验中, 研究人员表明, 大脑中的某些单个神经元仅在存在特定方向的边缘(例如垂直或水平边缘)时才激活或发射。例如, 某些神经元在暴露于垂直侧面时会激发, 而另一些则显示为水平边缘时会激发。 Hubel和Wiesel发现, 所有这些神经元都以圆柱状排列得井井有条, 并且它们能够共同产生视觉感知。在系统内部具有特定任务的专用组件这一想法是机器也要使用的一种想法, 你也可以在CNN中找到它。
卷积神经网络已成为计算机视觉领域最有影响力的创新之一。它们的性能比传统的计算机视觉要好得多, 并且产生了最新的结果。这些神经网络已被证明在许多不同的现实案例研究和应用中都是成功的, 例如:
- 图像分类, 目标检测, 分割, 人脸识别;
- 利用基于CNN的视觉系统的自动驾驶汽车;
- 使用卷积神经网络对晶体结构进行分类;
- 当然还有更多!
要了解这一成功, 你必须回到2012年, 这一年Alex Krizhevsky使用卷积神经网络赢得了当年的ImageNet竞赛, 将分类误差从26%降低到15%。
请注意, ImageNet大规模视觉识别挑战赛(ILSVRC)始于2010年, 是一项年度竞赛, 研究团队在该竞赛中根据给定的数据集评估其算法, 并竞争在多个视觉识别任务上实现更高的准确性。
这段时间过了一段时间, 神经网络才重新崭露头角。这通常被称为”神经网络的第三次浪潮”。其他两次浪潮发生在1940年代至1960年代, 以及1970年代至1980年代。
好吧, 你知道你将使用受生物视觉皮层启发的前馈网络, 但这实际上意味着什么?
看看下面的图片:
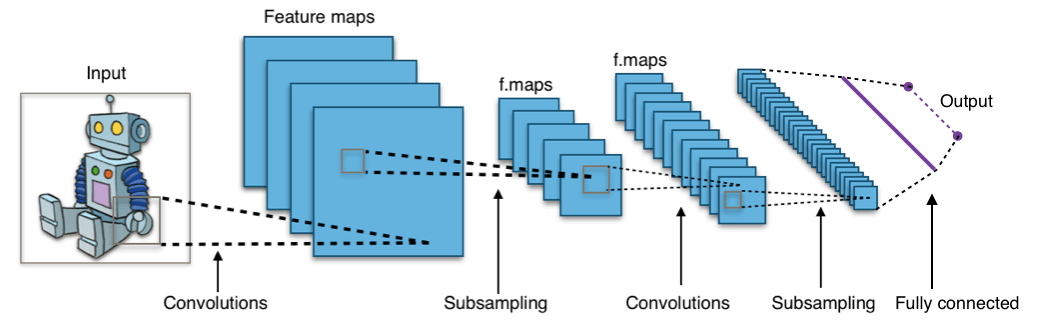
图:来自Wikimedia的卷积神经网络
该图像显示你将图像作为输入输入到网络, 该网络经过多次卷积, 二次采样, 完全连接的层并最终输出内容。
但是这些概念都是什么?
卷积层计算连接到输入中的局部区域或感受野的神经元的输出, 每个神经元计算它们的权重与它们在输入体积中所连接的小的感受野之间的点积。每次计算都会从输入图像中提取特征图。换句话说, 假设你有一个以5×5的值矩阵表示的图像, 并采用3×3的矩阵并将3×3的窗口或内核滑动到图像周围。在该矩阵的每个位置, 将3×3窗口的值乘以该窗口当前覆盖的图像中的值。结果, 你将获得一个代表该图像窗口中所有值的数字。你可以使用此层进行过滤:当窗口在图像上移动时, 你将检查图像该部分中的图案。这是因为过滤器有效, 它们乘以卷积输出的值。
二次采样的目的是通过减小输入尺寸来获得输入表示, 这有助于减少过度拟合。子采样技术之一是最大池化。使用此技术, 你可以根据区域的大小从区域中选择最高的像素值。换句话说, 最大池从内核当前覆盖的图像窗口中获取最大值。例如, 你可以有一个大小为2 x 2的最大池化层, 它将从2 x 2区域中选择最大像素强度值。你以为池层就像卷积层一样工作是正确的!你还可以获取内核或窗口, 并将其移至图像上。唯一的区别是应用于内核的功能, 并且图像窗口不是线性的。

图:来自维基百科的Max-Pooling
完全连接层的目标是使卷积层学习的高级特征变平坦并组合所有特征。它将经过展平的输出传递到输出层, 你可以在其中使用softmax分类器或S型曲面来预测输入类标签。
有关更多信息, 你可以转到此处。
Fashion-MNIST数据集
在继续加载数据之前, 最好先看看将要使用的数据! Fashion-MNIST数据集是Zalando文章图像的数据集, 其中包含来自10个类别的70, 000种时尚产品的28×28灰度图像, 每个类别7, 000个图像。训练集有60, 000张图像, 测试集有10, 000张图像。加载数据后, 你可以再次检查! 😉
Fashion-MNIST与你可能已经知道的MNIST数据集相似, 可用于对手写数字进行分类。这意味着图像尺寸, 训练和测试分割与MNIST数据集相似。提示:如果要学习如何使用后一个数据集为分类任务实现多层感知器(MLP), 请转到本教程。
你可以在此处找到Fashion-MNIST数据集, 但也可以在特定的TensorFlow和Keras模块的帮助下加载它。你将在下一部分中看到它的工作原理!
加载数据
Keras附带了一个称为数据集的库, 你可以使用该库开箱即用地加载数据集:从服务器下载数据并加快了处理速度, 因为你不必再将数据下载到计算机上。火车和测试图像以及标签一起被加载并存储在变量train_X, train_Y, test_X和test_Y中。
from keras.datasets import fashion_mnist
(train_X, train_Y), (test_X, test_Y) = fashion_mnist.load_data()
Using TensorFlow backend.
大!那很简单, 不是吗?
到目前为止, 你可能已经完成了一百万次, 但这始终是入门的重要步骤。现在你已完全准备好开始分析, 处理和建模数据!
分析数据
现在让我们分析数据集中的图像外观。即使你现在知道图像的尺寸, 也仍然值得通过程序分析来进行努力:你可能必须重新调整图像像素的大小并调整图像的大小。
import numpy as np
from keras.utils import to_categorical
import matplotlib.pyplot as plt
%matplotlib inline
print('Training data shape : ', train_X.shape, train_Y.shape)
print('Testing data shape : ', test_X.shape, test_Y.shape)
('Training data shape : ', (60000, 28, 28), (60000, ))
('Testing data shape : ', (10000, 28, 28), (10000, ))
从上面的输出中, 你可以看到训练数据的形状为60000 x 28 x 28, 因为每个28 x 28维有60, 000个训练样本。同样, 由于有10, 000个测试样本, 因此测试数据的形状为10000 x 28 x 28。
# Find the unique numbers from the train labels
classes = np.unique(train_Y)
nClasses = len(classes)
print('Total number of outputs : ', nClasses)
print('Output classes : ', classes)
('Total number of outputs : ', 10)
('Output classes : ', array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8))
共有十个输出类, 范围从0到9。
另外, 不要忘记看一下数据集中的图像:
plt.figure(figsize=[5, 5])
# Display the first image in training data
plt.subplot(121)
plt.imshow(train_X[0, :, :], cmap='gray')
plt.title("Ground Truth : {}".format(train_Y[0]))
# Display the first image in testing data
plt.subplot(122)
plt.imshow(test_X[0, :, :], cmap='gray')
plt.title("Ground Truth : {}".format(test_Y[0]))
Text(0.5, 1, u'Ground Truth : 9')

上面两个图的输出看起来像脚踝靴, 并且为该类别分配了类别标签9。类似地, 其他时尚产品将具有不同的标签, 但相似的产品将具有相同的标签。这意味着所有7, 000个踝靴图像的类别标签将为9。
数据预处理
如上图所示, 这些图像是灰度图像, 像素值范围为0到255。此外, 这些图像的尺寸为28 x28。因此, 你需要对数据进行预处理, 然后再处理将其输入模型。
- 第一步, 将火车和测试集的每个28 x 28图像转换为大小为28 x 28 x 1的矩阵, 该矩阵被馈送到网络中。
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
train_X.shape, test_X.shape
((60000, 28, 28, 1), (10000, 28, 28, 1))
- 现在的数据为int8格式, 因此在将其输入网络之前, 你需要将其类型转换为float32, 并且还必须重新缩放像素值(范围为0-1)。因此, 让我们开始吧!
train_X = train_X.astype('float32')
test_X = test_X.astype('float32')
train_X = train_X / 255.
test_X = test_X / 255.
- 现在, 你需要将类标签转换为一键编码矢量。
在单编码中, 你可以将分类数据转换为数字向量。之所以以一种热编码方式转换分类数据, 是因为机器学习算法无法直接使用分类数据。你为每个类别或类生成一个布尔列。对于每个样本, 这些列中只有一个可以取值为1。因此, 术语”一次热编码”。
对于你的问题陈述, 一个热编码将是一个行向量, 并且对于每个图像, 其尺寸将为1 x10。这里要注意的重要一点是, 该向量由全零组成, 除了其类别表示, 因此为1。例如, 你在上面绘制的踝靴图像的标签为9, 因此对于所有踝靴图像, 一个热编码矢量将为[0 0 0 0 0 0 0 0 1 0]。
因此, 让我们将训练和测试标签转换为一键编码矢量:
# Change the labels from categorical to one-hot encoding
train_Y_one_hot = to_categorical(train_Y)
test_Y_one_hot = to_categorical(test_Y)
# Display the change for category label using one-hot encoding
print('Original label:', train_Y[0])
print('After conversion to one-hot:', train_Y_one_hot[0])
('Original label:', 9)
('After conversion to one-hot:', array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]))
这很清楚, 对吧?请注意, 你还可以打印train_Y_one_hot, 它将显示大小为60000 x 10的矩阵, 其中每一行都描述图像的一键编码。
- 最后一步是至关重要的一步。在机器学习或任何特定于数据的任务中, 应正确划分数据。为了使模型更好地泛化, 你可以将训练数据分为两部分, 一部分用于训练, 另一部分用于验证。在这种情况下, 你将在训练数据的80%上训练模型, 并在剩余训练数据的20%上验证模型。这也将有助于减少过度拟合, 因为你将根据训练阶段未看到的数据来验证模型, 这将有助于提高测试性能。
from sklearn.model_selection import train_test_split
train_X, valid_X, train_label, valid_label = train_test_split(train_X, train_Y_one_hot, test_size=0.2, random_state=13)
最后, 让我们检查一下训练和验证集的形状。
train_X.shape, valid_X.shape, train_label.shape, valid_label.shape
((48000, 28, 28, 1), (12000, 28, 28, 1), (48000, 10), (12000, 10))
网络
图像的尺寸为28 x28。你将图像矩阵转换为数组, 在0和1之间重新缩放, 重新定形, 使其尺寸为28 x 28 x 1, 并将其作为输入输入到网络。
你将使用三个卷积层:
- 第一层将具有32-3 x 3个滤镜,
- 第二层将具有64-3 x 3滤镜和
- 第三层将具有128-3 x 3滤镜。
此外, 还有三个最大池化层, 每个层的大小为2 x 2。

图:模型的架构
建模数据
首先, 让我们导入训练模型所需的所有必要模块。
import keras
from keras.models import Sequential, Input, Model
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.layers.advanced_activations import LeakyReLU
你将使用64的批处理大小, 也最好使用128或256的较大批处理大小, 这完全取决于内存。它为确定学习参数做出了巨大贡献, 并影响了预测准确性。你将训练网络20个纪元。
batch_size = 64
epochs = 20
num_classes = 10
神经网络架构
在Keras中, 你可以通过一层一层地添加所需的层来堆叠层。这就是你要做的:首先使用Conv2D()添加第一个卷积层。请注意, 使用此功能是因为你正在处理图像!接下来, 添加Leaky ReLU激活功能, 该功能可帮助网络学习非线性决策边界。由于你有十个不同的类, 因此需要一个非线性决策边界, 该边界可以将这十个不能线性分离的类分开。
更具体地说, 你添加泄漏的ReLU, 因为它们试图解决整流线性单元(ReLU)垂死的问题。 ReLU激活函数在神经网络体系结构中使用很多, 更具体地说, 在卷积网络中, 已证明它比广泛使用的逻辑S形函数更有效。截至2017年, 此激活功能是用于深度神经网络的最流行的功能。 ReLU功能允许将激活阈值设为零。但是, 在培训期间, ReLU单位可以”死亡”。当较大的梯度流过ReLU神经元时, 可能会发生这种情况:这可能导致权重更新, 使得神经元永远不会再在任何数据点上激活。如果发生这种情况, 那么从该点开始, 流经设备的梯度将永远为零。泄漏的ReLU试图解决此问题:该函数将不会为零, 而是具有较小的负斜率。
接下来, 你将使用MaxPooling2D()添加max-pooling层, 依此类推。最后一层是具有10个单位的softmax激活功能的密集层, 这是此多类分类问题所需要的。
fashion_model = Sequential()
fashion_model.add(Conv2D(32, kernel_size=(3, 3), activation='linear', input_shape=(28, 28, 1), padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D((2, 2), padding='same'))
fashion_model.add(Conv2D(64, (3, 3), activation='linear', padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2), padding='same'))
fashion_model.add(Conv2D(128, (3, 3), activation='linear', padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2), padding='same'))
fashion_model.add(Flatten())
fashion_model.add(Dense(128, activation='linear'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(Dense(num_classes, activation='softmax'))
编译模型
创建模型后, 你可以使用Adam优化器(最受欢迎的优化算法之一)对其进行编译。你可以在此处阅读有关此优化器的更多信息。另外, 你可以指定损失类型, 它是用于多类分类的分类交叉熵, 也可以使用二进制交叉熵作为损失函数。最后, 你将指标指定为要在模型训练期间进行分析的准确性。
fashion_model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(), metrics=['accuracy'])
让我们使用摘要功能来可视化在上一步中创建的图层。这将在每个图层中显示一些参数(权重和偏差), 以及模型中的总参数。
fashion_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_51 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
leaky_re_lu_57 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
max_pooling2d_49 (MaxPooling (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_52 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
leaky_re_lu_58 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
max_pooling2d_50 (MaxPooling (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_53 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
leaky_re_lu_59 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
max_pooling2d_51 (MaxPooling (None, 4, 4, 128) 0
_________________________________________________________________
flatten_17 (Flatten) (None, 2048) 0
_________________________________________________________________
dense_33 (Dense) (None, 128) 262272
_________________________________________________________________
leaky_re_lu_60 (LeakyReLU) (None, 128) 0
_________________________________________________________________
dense_34 (Dense) (None, 10) 1290
=================================================================
Total params: 356, 234
Trainable params: 356, 234
Non-trainable params: 0
_________________________________________________________________
训练模型
终于是时候用Keras的fit()函数训练模型了!该模型训练20个纪元。 fit()函数将返回一个历史对象;通过在fashion_train中讲述该函数的结果, 你以后可以使用它在训练和验证之间绘制精度和损失函数图, 这将帮助你直观地分析模型的性能。
fashion_train = fashion_model.fit(train_X, train_label, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(valid_X, valid_label))
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.4661 - acc: 0.8311 - val_loss: 0.3320 - val_acc: 0.8809
Epoch 2/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.2874 - acc: 0.8951 - val_loss: 0.2781 - val_acc: 0.8963
Epoch 3/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.2420 - acc: 0.9111 - val_loss: 0.2501 - val_acc: 0.9077
Epoch 4/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.2088 - acc: 0.9226 - val_loss: 0.2369 - val_acc: 0.9147
Epoch 5/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1838 - acc: 0.9324 - val_loss: 0.2602 - val_acc: 0.9070
Epoch 6/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1605 - acc: 0.9396 - val_loss: 0.2264 - val_acc: 0.9193
Epoch 7/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1356 - acc: 0.9488 - val_loss: 0.2566 - val_acc: 0.9180
Epoch 8/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1186 - acc: 0.9553 - val_loss: 0.2556 - val_acc: 0.9149
Epoch 9/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0985 - acc: 0.9634 - val_loss: 0.2681 - val_acc: 0.9204
Epoch 10/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0873 - acc: 0.9670 - val_loss: 0.2712 - val_acc: 0.9221
Epoch 11/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0739 - acc: 0.9721 - val_loss: 0.2757 - val_acc: 0.9202
Epoch 12/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0628 - acc: 0.9767 - val_loss: 0.3126 - val_acc: 0.9132
Epoch 13/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0569 - acc: 0.9789 - val_loss: 0.3556 - val_acc: 0.9081
Epoch 14/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0452 - acc: 0.9833 - val_loss: 0.3441 - val_acc: 0.9189
Epoch 15/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0421 - acc: 0.9847 - val_loss: 0.3400 - val_acc: 0.9165
Epoch 16/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0379 - acc: 0.9861 - val_loss: 0.3876 - val_acc: 0.9195
Epoch 17/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0405 - acc: 0.9855 - val_loss: 0.4112 - val_acc: 0.9164
Epoch 18/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0285 - acc: 0.9897 - val_loss: 0.4150 - val_acc: 0.9181
Epoch 19/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0322 - acc: 0.9877 - val_loss: 0.4584 - val_acc: 0.9196
Epoch 20/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0262 - acc: 0.9906 - val_loss: 0.4396 - val_acc: 0.9205
最后!你在fashion-MNIST上对模型进行了20个训练, 通过观察训练的准确性和损失, 你可以说该模型表现出色, 因为经过20个训练后, 训练准确性为99%, 训练损失非常低。
但是, 该模型似乎过拟合, 因为验证损失为0.4396, 验证准确性为92%。过度拟合的直觉是, 网络已经很好地记住了训练数据, 但是不能保证能在看不见的数据上工作, 这就是为什么训练和验证准确性存在差异的原因。
你可能需要处理这个问题。在下一部分中, 你将学习如何通过在网络中添加一个Dropout层并使所有其他层保持不变来使模型的性能更好。
但是首先, 在得出结论之前, 让我们在测试集上评估模型的性能。
测试集上的模型评估
test_eval = fashion_model.evaluate(test_X, test_Y_one_hot, verbose=0)
print('Test loss:', test_eval[0])
print('Test accuracy:', test_eval[1])
('Test loss:', 0.46366268818555401)
('Test accuracy:', 0.91839999999999999)
测试精度看起来令人印象深刻。事实证明, 你的分类器要比此处报告的基准更好, 后者是平均精度为0.897的SVM分类器。此外, 与fashion-MNIST数据集的创建者的GitHub个人资料上提到的某些深度学习模型相比, 该模型的性能很好。
但是, 你看到该模型看起来过拟合。这些结果真的很好吗?
让我们将模型评估放到透视图中, 并绘制训练和验证数据之间的准确性和损失图:
accuracy = fashion_train.history['acc']
val_accuracy = fashion_train.history['val_acc']
loss = fashion_train.history['loss']
val_loss = fashion_train.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'bo', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()


从以上两个图可以看出, 验证精度在4-5个时期后几乎停滞, 在某些时期很少增加。最初, 验证准确性随损失呈线性增加, 但随后并没有增加太多。
验证损失表明, 这是过度拟合的迹象, 类似于验证精度, 它线性下降, 但在4-5个时期之后, 它开始增加。这意味着该模型尝试存储数据并成功。
考虑到这一点, 是时候在我们的模型中引入一些辍学了, 看看它是否有助于减少过度拟合。
将Dropout添加到网络
你可以添加一个辍学层, 以在某种程度上克服过拟合的问题。在训练过程中, 辍学现象会随机关闭一部分神经元, 从而减少对训练集的依赖性。你想关闭多少个神经元部分由超参数决定, 可以对它进行相应的调整。这样, 关闭一些神经元将不允许网络存储训练数据, 因为并非所有神经元都将同时处于活动状态, 并且非活动神经元将无法学习任何内容。
因此, 让我们再次创建, 编译和训练网络, 但这一次是辍学。并以64个批处理大小运行20个纪元。
batch_size = 64
epochs = 20
num_classes = 10
fashion_model = Sequential()
fashion_model.add(Conv2D(32, kernel_size=(3, 3), activation='linear', padding='same', input_shape=(28, 28, 1)))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D((2, 2), padding='same'))
fashion_model.add(Dropout(0.25))
fashion_model.add(Conv2D(64, (3, 3), activation='linear', padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2), padding='same'))
fashion_model.add(Dropout(0.25))
fashion_model.add(Conv2D(128, (3, 3), activation='linear', padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2), padding='same'))
fashion_model.add(Dropout(0.4))
fashion_model.add(Flatten())
fashion_model.add(Dense(128, activation='linear'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(Dropout(0.3))
fashion_model.add(Dense(num_classes, activation='softmax'))
fashion_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_54 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
leaky_re_lu_61 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
max_pooling2d_52 (MaxPooling (None, 14, 14, 32) 0
_________________________________________________________________
dropout_29 (Dropout) (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_55 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
leaky_re_lu_62 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
max_pooling2d_53 (MaxPooling (None, 7, 7, 64) 0
_________________________________________________________________
dropout_30 (Dropout) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_56 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
leaky_re_lu_63 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
max_pooling2d_54 (MaxPooling (None, 4, 4, 128) 0
_________________________________________________________________
dropout_31 (Dropout) (None, 4, 4, 128) 0
_________________________________________________________________
flatten_18 (Flatten) (None, 2048) 0
_________________________________________________________________
dense_35 (Dense) (None, 128) 262272
_________________________________________________________________
leaky_re_lu_64 (LeakyReLU) (None, 128) 0
_________________________________________________________________
dropout_32 (Dropout) (None, 128) 0
_________________________________________________________________
dense_36 (Dense) (None, 10) 1290
=================================================================
Total params: 356, 234
Trainable params: 356, 234
Non-trainable params: 0
_________________________________________________________________
fashion_model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(), metrics=['accuracy'])
fashion_train_dropout = fashion_model.fit(train_X, train_label, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(valid_X, valid_label))
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
48000/48000 [==============================] - 66s 1ms/step - loss: 0.5954 - acc: 0.7789 - val_loss: 0.3788 - val_acc: 0.8586
Epoch 2/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3797 - acc: 0.8591 - val_loss: 0.3150 - val_acc: 0.8832
Epoch 3/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3302 - acc: 0.8787 - val_loss: 0.2836 - val_acc: 0.8961
Epoch 4/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3034 - acc: 0.8868 - val_loss: 0.2663 - val_acc: 0.9002
Epoch 5/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2843 - acc: 0.8936 - val_loss: 0.2481 - val_acc: 0.9083
Epoch 6/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2699 - acc: 0.9002 - val_loss: 0.2469 - val_acc: 0.9032
Epoch 7/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2561 - acc: 0.9049 - val_loss: 0.2422 - val_acc: 0.9095
Epoch 8/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2503 - acc: 0.9068 - val_loss: 0.2429 - val_acc: 0.9098
Epoch 9/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2437 - acc: 0.9096 - val_loss: 0.2230 - val_acc: 0.9173
Epoch 10/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2307 - acc: 0.9126 - val_loss: 0.2170 - val_acc: 0.9187
Epoch 11/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2307 - acc: 0.9135 - val_loss: 0.2265 - val_acc: 0.9193
Epoch 12/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2229 - acc: 0.9160 - val_loss: 0.2136 - val_acc: 0.9229
Epoch 13/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2202 - acc: 0.9162 - val_loss: 0.2173 - val_acc: 0.9187
Epoch 14/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2161 - acc: 0.9188 - val_loss: 0.2142 - val_acc: 0.9211
Epoch 15/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2119 - acc: 0.9196 - val_loss: 0.2133 - val_acc: 0.9233
Epoch 16/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2073 - acc: 0.9222 - val_loss: 0.2159 - val_acc: 0.9213
Epoch 17/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2050 - acc: 0.9231 - val_loss: 0.2123 - val_acc: 0.9233
Epoch 18/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2016 - acc: 0.9238 - val_loss: 0.2191 - val_acc: 0.9235
Epoch 19/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2001 - acc: 0.9244 - val_loss: 0.2110 - val_acc: 0.9258
Epoch 20/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.1972 - acc: 0.9255 - val_loss: 0.2092 - val_acc: 0.9269
让我们保存模型, 以便你可以直接加载它, 而不必再训练20个纪元。这样, 你可以稍后在需要时加载模型并修改架构。或者, 你可以在此保存的模型上开始训练过程。保存模型-甚至包括模型的权重-始终是一个好主意, 因为它可以节省你的时间。请注意, 你还可以在每个时期之后保存模型, 这样, 如果发生某个问题而在某个时期停止训练, 则不必从头开始训练。
fashion_model.save("fashion_model_dropout.h5py")
测试集上的模型评估
最后, 让我们还评估你的新模型并查看其性能!
test_eval = fashion_model.evaluate(test_X, test_Y_one_hot, verbose=1)
10000/10000 [==============================] - 5s 461us/step
print('Test loss:', test_eval[0])
print('Test accuracy:', test_eval[1])
('Test loss:', 0.21460009642243386)
('Test accuracy:', 0.92300000000000004)
哇!即使测试准确性没有显着提高, 但与以前的结果相比, 测试损失却有所减少, 在我们的模型中添加Dropout看起来还是可行的。
现在, 让我们最后绘制一次训练和验证数据之间的准确性和损失图。
accuracy = fashion_train_dropout.history['acc']
val_accuracy = fashion_train_dropout.history['val_acc']
loss = fashion_train_dropout.history['loss']
val_loss = fashion_train_dropout.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'bo', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()


最后, 你可以看到验证损失和验证准确性都与训练损失和训练准确性同步。即使验证损失和准确性线不是线性的, 但它表明你的模型并未过拟合:验证损失正在减少且没有增加, 并且训练和验证准确性之间没有太大的差距。
因此, 你可以说你的模型的泛化能力变得更好, 因为测试集和验证集的损失都比训练损失略多。
预测标签
predicted_classes = fashion_model.predict(test_X)
由于你得到的预测是浮点值, 因此将预测的标签与真实的测试标签进行比较是不可行的。因此, 你将舍入输出, 该输出会将float值转换为整数。此外, 你将使用np.argmax()选择行中具有较高值的索引号。
例如, 假设一个测试图像的预测为0 1 0 0 0 0 0 0 0 0 0 0, 该图像的输出应为类标签1。
predicted_classes = np.argmax(np.round(predicted_classes), axis=1)
predicted_classes.shape, test_Y.shape
((10000, ), (10000, ))
correct = np.where(predicted_classes==test_Y)[0]
print "Found %d correct labels" % len(correct)
for i, correct in enumerate(correct[:9]):
plt.subplot(3, 3, i+1)
plt.imshow(test_X[correct].reshape(28, 28), cmap='gray', interpolation='none')
plt.title("Predicted {}, Class {}".format(predicted_classes[correct], test_Y[correct]))
plt.tight_layout()
Found 9188 correct labels

incorrect = np.where(predicted_classes!=test_Y)[0]
print "Found %d incorrect labels" % len(incorrect)
for i, incorrect in enumerate(incorrect[:9]):
plt.subplot(3, 3, i+1)
plt.imshow(test_X[incorrect].reshape(28, 28), cmap='gray', interpolation='none')
plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], test_Y[incorrect]))
plt.tight_layout()
Found 812 incorrect labels

通过查看几张图片, 你无法确定为什么模型无法正确分类以上图片, 但是尽管CNN是一个分类器, 但似乎出现在多个类上的各种相似模式都会影响分类器的性能。健壮的架构。例如, 图像5和6都属于不同的类别, 但是看起来有点相似, 例如夹克或长袖衬衫。
分类报告
分类报告将帮助我们更详细地识别错误分类的类别。你将能够观察到模型在给定的十个类别中表现不佳的原因。
from sklearn.metrics import classification_report
target_names = ["Class {}".format(i) for i in range(num_classes)]
print(classification_report(test_Y, predicted_classes, target_names=target_names))
precision recall f1-score support
Class 0 0.77 0.90 0.83 1000
Class 1 0.99 0.98 0.99 1000
Class 2 0.88 0.88 0.88 1000
Class 3 0.94 0.92 0.93 1000
Class 4 0.88 0.87 0.88 1000
Class 5 0.99 0.98 0.98 1000
Class 6 0.82 0.72 0.77 1000
Class 7 0.94 0.99 0.97 1000
Class 8 0.99 0.98 0.99 1000
Class 9 0.98 0.96 0.97 1000
avg / total 0.92 0.92 0.92 10000
你可以看到, 分类器在精度和查全率两方面都不如第6类。对于0类和2类, 分类器缺乏精度。同样, 对于第4类, 分类器略微缺乏准确性和召回率。
走得更远!
本教程是使用Keras在Python中进行卷积神经网络的良好起点。如果你能够轻松地进行工作, 甚至只需付出更多的努力, 那就做好了!尝试使用相同的模型架构但使用不同类型的可用公共数据集进行一些实验。
仍然有很多内容要讨论, 所以为什么不参加srcmini的Python深度学习课程呢?同时, 还请确保查看Keras文档(如果你尚未这样做的话)。你将找到有关所有函数, 参数, 更多层等的更多示例和信息。当你学习如何在Python中使用神经网络时, 它无疑是必不可少的资源!
如果你想阅读一本解释深度学习基础知识(使用Keras)以及其在实践中的用法的书, 那么你绝对应该阅读FrançoisChollet的Python深度学习书。
评论前必须登录!
注册