 srcmini
srcmini本文概述
- 先决条件
- 准备你的问题
- 为什么主题建模有用?
- 库和功能
- 音乐与书籍
- 获取数据
- 检查数据
- 创建文档术语矩阵
- 设定变数
- 拟合模型
- 用热门单词识别主题
- 分类文件
- 识别艺术家/作者
- 设置变量并拟合模型
- 用热门单词识别K-Means主题
- 检查数据
- 创建DTM并设置变量
- 拟合模型并确定主题
- 分类文件
- 推荐类似作家
- 按类型推荐类似文件
- 使用NLP改进模型
- 检查NLP输出
- 使用NLP设置变量
- 拟合模型并确定主题
- 随着时间的主题
将尖端技术与R, NLP和机器学习一起使用, 可以对文本主题进行建模, 并建立自己的音乐推荐系统!
这是一个分为三部分的系列教程的第二部分, 其中第二部分是B, 你将继续使用R来执行传奇艺术家Prince以及其他艺术家和作者的音乐歌词案例研究中的各种分析任务。这三个教程涵盖以下内容:
- 第一部分:使用NLP进行歌词分析和使用R进行机器学习
- 第二部分-A:R中的整洁情绪分析
- 第二部分B:使用R的机器学习和NLP-主题建模和音乐分类
- 第三部分:歌词分析:结合R使用机器学习进行预测分析
假设你是为NASA工作的数据科学家。你需要监视两个用于登月轨道的航天器, 它们将研究月球与太阳的相互作用。与任何航天器一样, 在测试或发射后可能会捕获问题。这些异常以自然语言记录在将近20, 000个问题报告中。你的工作是确定报告语料库中最受欢迎的主题和趋势主题, 并向工程师和程序主管提供规范性的分析结果, 从而影响太空探索的未来。
这是一个真实场景的示例, 应该让你了解在学习如何使用尖端技术(例如带有机器学习的主题建模, 自然语言处理(NLP))后触手可及的强大功能和R编程。幸运的是, 你不必为NASA工作就可以进行创新。在本教程中, 你的任务(如果你选择接受)是学习主题建模以及如何基于音乐歌词和非小说类书籍构建简单的推荐(又称为”推荐”)系统。
纯娱乐!
这与主题建模无关, 而只是出于娱乐目的, 使用上一个教程中介绍的名为circlize的出色程序包来激发这些感光器, 并享受你将在本教程中使用的所有源的圆形图。
library(jpeg)
library(circlize) #you'll use this package later
#read in the list of jpg files of album/book covers
files = list.files("jpg\\", full.names = TRUE)
#clean up the file names so we can use them in the diagram
removeSpecialChars <- function(x) gsub("[^a-zA-Z]", " ", x)
names <- lapply(files, removeSpecialChars)
names <- gsub("jpg", "", names )
#read up on the circlize package for details
#but there will be comments in later sections
circos.clear()
circos.par("points.overflow.warning" = FALSE)
circos.initialize(names, xlim = c(0, 2))
circos.track(ylim = c(0, 1), panel.fun = function(x, y) {
image = as.raster(readJPEG(files[CELL_META$sector.numeric.index]))
circos.text(CELL_META$xcenter, CELL_META$cell.ylim[1] - uy(1.5, "mm"), CELL_META$sector.index, CELL_META$sector.index, facing = "clockwise", niceFacing = TRUE, adj = c(1, 0.5), cex = 0.9)
circos.raster(image, CELL_META$xcenter, CELL_META$ycenter, width = "1.5cm", facing = "downward")
}, bg.border = 1, track.height = .4)
内容
介绍
准备工作
使用LDA建立模型
模型一:三位作家的LDA
模型2:三位作家的K均值
模型三:LDA适用于12位作家
模式四:歌曲歌曲的LDA
总结
结构体
在以前的教程中, 你使用词频, tf-idf统计信息和情感分析研究了Prince歌词的内容。通过使用主题建模的概念, 你可以更深入地了解歌词和其他文本。
在本教程中, 你将使用潜在Dirichlet分配(LDA)和K-Means集群机器学习算法构建四个模型。我将在本教程的后面部分解释算法。
模型一利用王子的歌词中的文字结合两本非小说类书籍。该模型的目的是为你提供一个简单的示例, 该示例使用LDA(一种无监督算法)来生成共同建议主题的单词集合。这些主题没有标签, 需要人工解释。一旦确定了预定义数量的主题, 就可以获取模型的结果, 并将每首歌曲或书籍页面分类为每个类别。一首歌曲可能包含你所生成的所有主题, 但可能更清晰地融入其中。这称为文档分类, 但是由于你知道文档的作者, 因此你实际上是在将作者分类为主题组。
模型二使用模型一数据集, 并快速浏览了使用不同算法k均值生成主题的过程, 以及它可能不是主题建模的最佳选择。
模型三再次使用LDA, 利用更大的数据集, 其中包含来自不同流派的多个艺术家和更多的书作家。当你将来自作者/艺术家的大多数文档分类为最有可能的主题时, 你便具有了将具有相似主题构成的作家分组的能力。对于实体模型, 你应该看到相似的体裁出现在同一主题分组中。例如, 说唱艺术家将出现在一个主题中, 而两本关于同一主题的书应一起出现在另一个主题中。因此, 你可能会推荐类似的作家!显然, 作者及其类型都带有标签, 但主题没有, 因此不受监督。
模型四仅在王子的歌词上使用LDA。这次, 你将使用在本教程之外生成的带注释的数据集, 该数据集将每个单词标记为语音的一部分(即名词, 动词等)以及单词的词根形式(词根化)。你还将检查主题如何随时间变化。
NLP和机器学习是人工智能的子领域。最近有尝试使用AI进行歌曲创作。这不是本教程的目的, 但这是如何将AI用作艺术的示例。毕竟, 前三个字母是A-R-T!暂时, 将AI与歌曲创作进行比较:你可以轻松地遵循一种模式并创建一种结构(诗歌, 合唱, 诗歌等), 但是使歌曲更出色的是作者在创作过程中注入了创造力。在本教程中, 你需要锻炼自己的技术技能来构建模型, 但是你还需要调用自己的艺术创造力, 并具有解释和解释结果的能力。
考虑一下:如果主题建模是一门艺术, 那么歌词就是代码, 歌曲创作是算法, 歌曲就是模型!你的比喻是什么?
典型的推荐系统并不完全基于文本。例如, Netflix可以根据先前的选择和关联的元数据来推荐电影。潘多拉盒鼠(Pandora)采用不同的方法, 它依赖于音乐基因组, 该基因组包含400种音乐属性, 包括旋律, 节奏, 作曲和歌词摘要。然而, 这种基因组开发始于2000年, 花了5年时间和30名音乐理论专家来完成。有很多研究论文根据情节摘要处理电影推荐。很难找到基于实际歌词内容的音乐推荐系统的示例。想试试看?
先决条件
本教程系列的第二部分B要求对整洁的数据有基本的了解, 特别是dplyr和ggplot2之类的软件包。还建议你使用tidytext进行文本挖掘的实践, 因为以前的教程已经介绍了该实践。你还需要熟悉R函数, 因为你将利用一些函数为每个模型重用代码。为了专注于获取见解, 我提供了旨在在你自己的数据集上使用的代码, 但是详细的解释可能需要你进一步调查。
准备你的问题
你可以使用主题建模做什么?也许有些文档包含你可以挖掘的关键业务信息。也许你可以从Twitter抓取数据, 然后找出人们对你公司产品的评价。也许你可以构建自己的分类系统, 以将某些文档发送到正确的部门进行分析。你可以探索无限的世界!去吧!
为什么主题建模有用?
这是主题建模的几种应用程序:
- 文档摘要:使用主题模型来理解和总结科学文章, 从而加快研发速度。这同样适用于历史文献, 报纸, 博客, 甚至小说。
- 文本分类:主题建模可以通过将主题中的相似单词组合在一起而不是将每个单词用作单个功能来改善分类。
- 推荐系统:使用基于相似度的概率, 可以构建推荐系统。你可以为读者推荐主题结构类似于已阅读文章的文章。
- 你还有其他想法吗?
库和功能
本教程中唯一不在第一部分或第二部分-A中的新软件包是topicmodel, tm和plotly。你将使用topicmodels的LDA()函数, 该函数允许模型学习区分不同的文档。 tm包用于文本挖掘, 你只需使用一次inspect()函数即可查看文档术语矩阵的内部, 我将在后面解释。你仅会使用一次plotly创建ggplot2图的交互式版本。
library(tidytext) #text mining, unnesting
library(topicmodels) #the LDA algorithm
library(tidyr) #gather()
library(dplyr) #awesome tools
library(ggplot2) #visualization
library(kableExtra) #create attractive tables
library(knitr) #simple table generator
library(ggrepel) #text and label geoms for ggplot2
library(gridExtra)
library(formattable) #color tile and color bar in `kables`
library(tm) #text mining
library(circlize) #already loaded, but just being comprehensive
library(plotly) #interactive ggplot graphs
在先前的教程中定义了以下功能, 但word_chart()除外;但是, word_chart()的内容和描述也可以在第二部分B中找到。首先, 你需要知道它以独特的方式使用ggplot()来创建基于单词而非点的视觉效果。
#define some colors to use throughout
my_colors <- c("#E69F00", "#56B4E9", "#009E73", "#CC79A7", "#D55E00", "#D65E00")
#customize ggplot2's default theme settings
#this tutorial doesn't actually pass any parameters, but you may use it again in future tutorials so it's nice to have the options
theme_lyrics <- function(aticks = element_blank(), pgminor = element_blank(), lt = element_blank(), lp = "none")
{
theme(plot.title = element_text(hjust = 0.5), #center the title
axis.ticks = aticks, #set axis ticks to on or off
panel.grid.minor = pgminor, #turn on or off the minor grid lines
legend.title = lt, #turn on or off the legend title
legend.position = lp) #turn on or off the legend
}
#customize the text tables for consistency using HTML formatting
my_kable_styling <- function(dat, caption) {
kable(dat, "html", escape = FALSE, caption = caption) %>%
kable_styling(bootstrap_options = c("striped", "condensed", "bordered"), full_width = FALSE)
}
word_chart <- function(data, input, title) {
data %>%
#set y = 1 to just plot one variable and use word as the label
ggplot(aes(as.factor(row), 1, label = input, fill = factor(topic) )) +
#you want the words, not the points
geom_point(color = "transparent") +
#make sure the labels don't overlap
geom_label_repel(nudge_x = .2, direction = "y", box.padding = 0.1, segment.color = "transparent", size = 3) +
facet_grid(~topic) +
theme_lyrics() +
theme(axis.text.y = element_blank(), axis.text.x = element_blank(), #axis.title.x = element_text(size = 9), panel.grid = element_blank(), panel.background = element_blank(), panel.border = element_rect("lightgray", fill = NA), strip.text.x = element_text(size = 9)) +
labs(x = NULL, y = NULL, title = title) +
#xlab(NULL) + ylab(NULL) +
#ggtitle(title) +
coord_flip()
}
音乐与书籍
为了真正了解主题建模和分类的力量, 你不仅将像先前的教程一样使用Prince的歌词, 而且还将与Billboard Charts上认可的不同流派的其他几位艺术家合作。此外, 我还添加了一些有关不同主题的书, 例如运动营养, 冰山甚至机器学习!通过使用不同的数据集, 你可以将文档分类为关联的主题, 并区分相似的艺术家/作者。
提示:我将歌曲和书籍页面称为文档, 将音乐家/作者称为作家。在代码中, 你将看到对单词source的引用。这只是指数据引用哪个作者。我将使用流派一词来指代音乐流派和一本书的类别。为了清楚起见, 我没有使用书名, 而是使用书名。在你逐步学习本教程时, 这些参考将很有意义。
获取数据
为了专注于建模, 我在本教程之外进行了数据调节, 并在下面这三个文件中为你提供了所需的所有数据, 并且已经应用了以下条件:
- 在网上刮掉了八位歌手的歌词
- 使用pdftools包中的pdf_text()函数收集四本书的内容(每个页面代表一个不同的文档)
- 清理所有数据, 删除停用词, 并使用第一部分中所述的tidytext包创建整齐的版本
- 合并并平衡数据, 以便每个作者(源)具有相同数量的单词
你将在本教程中使用三个不同的数据集:
- three_sources_tidy_balanced:包含王子歌词和两本书
- all_sources_tidy_balanced:包含八位艺术家的歌词和四本书
- prince_tidy:仅包含王子歌词
我还包括了Prince歌词的注释数据集。我将解释当你进入Model 4时带注释的含义。
#Get Tidy Prince Dataset and Balanced Tidy Dataset of All Sources and 3 Sources
three_sources_tidy_balanced <- read.csv("three_sources_tidy_balanced.csv", stringsAsFactors = FALSE)
all_sources_tidy_balanced <- read.csv("all_sources_tidy_balanced.csv", stringsAsFactors = FALSE)
prince_tidy <- read.csv("prince_tidy.csv", stringsAsFactors = FALSE)
主题建模的主要目标是在非结构化文本数据中找到重要的与主题相关的术语(主题), 这些术语以单词共现模式进行衡量。主题模型的基本组件是文档, 术语和主题。潜在狄利克雷分配(LDA)是一种无监督的学习方法, 它可以发现文档集合下的不同主题, 其中每个文档都是单词的集合。 LDA做以下假设:
- 每个文档都是一个或多个主题的组合
- 每个主题都是言语交融
LDA寻求找到相关单词的组。它是一种迭代的生成算法。这是两个主要步骤:
- 在初始化期间, 每个单词都分配给一个随机主题
- 该算法迭代地遍历每个单词, 并出于以下考虑将单词重新分配给主题:
- 单词属于主题的概率
- 主题产生文件的可能性
LDA主题模型背后的概念是, 属于主题的单词会同时出现在文档中。它尝试将每个文档建模为主题的混合, 将每个主题建模为单词的混合。 (你可能会将此称为混合成员模型。)然后, 你可以使用文档属于特定主题的概率对其进行相应的分类。在你的情况下, 由于你从原始数据中了解文档的作者, 因此可以根据类似的主题结构推荐一位艺术家/作者。现在该看一个例子了。
检查数据
对于此模型, 你将数据集与三个不同的作者(即来源)结合使用, 并查找隐藏的主题。为了帮助你了解主题建模的功能, 这三个选定的来源非常不同, 直观上你知道它们涵盖了三个不同的主题。结果, 你将告诉模型创建三个主题, 并查看它的智能程度。首先, 你要使用my_kable_styling()函数以及formattable包中的color_bar()和color_tile()来检查数据集。
#group the dataset by writer (source) and count the words
three_sources_tidy_balanced %>%
group_by(source) %>%
mutate(word_count = n()) %>%
select(source, genre, word_count) %>% #only need these fields
distinct() %>%
ungroup() %>%
#assign color bar for word_count that varies according to size
#create static color for source and genre
mutate(word_count = color_bar("lightpink")(word_count), source = color_tile("lightblue", "lightblue")(source), genre = color_tile("lightgreen", "lightgreen")(genre)) %>%
my_kable_styling("Three Sources Stats")
在这里, 你将使用Prince歌词, 一本名为”机器学习傻瓜”的书和另一本名为” Why Icebergs Float”的书, 每个书有30, 000(不明显)的单词。

创建文档术语矩阵
由于你当前拥有一个平衡, 整洁的数据集, 其中包含Prince歌词和两本书, 因此你首先要创建一个文档术语矩阵(DTM), 其中每个文档都是一行, 而每一列都是一个术语。 LDA算法需要此格式。文档是指歌词中的歌曲和书中的页码。首先, 你将获取整洁的数据并计算文档中的单词, 然后将其通过管道传递到tidytext的cast_dtm()函数中, 其中document是带有文档名称的字段名称, 而word是带有术语的字段名称。你可以传递其他参数, 但这两个参数是必需的。
three_sources_dtm_balanced <- three_sources_tidy_balanced %>%
#get word count per document to pass to cast_dtm
count(document, word, sort = TRUE) %>%
ungroup() %>%
#create a DTM with docs as rows and words as columns
cast_dtm(document, word, n)
#examine the structure of the DTM
three_sources_dtm_balanced
<<DocumentTermMatrix (documents: 1449, terms: 13608)>>
Non-/sparse entries: 71386/19646606
Sparsity : 100%
Maximal term length: 27
Weighting : term frequency (tf)
这告诉你拥有多少文档和术语, 并且这是一个非常稀疏的矩阵。稀疏一词表示DTM主要包含空字段。由于所有文档中可能使用的术语的词汇量很大, 因此每个单独的文档中只会使用少数几个术语。
如果使用tm包中的inspect()函数查看DTM的几行和几列的内容, 你会看到每一行都是一个文档, 每一列都是一个术语。 (随时使用str()查看实际结构。)
#look at 4 documents and 8 words of the DTM
inspect(three_sources_dtm_balanced[1:4, 1:8])
<<DocumentTermMatrix (documents: 4, terms: 8)>>
Non-/sparse entries: 9/23
Sparsity : 72%
Maximal term length: 9
Weighting : term frequency (tf)
Sample :
Terms
Docs beautiful dance party push rock roll shake style
party up 0 0 40 0 1 2 0 0
push it up 0 1 1 56 0 0 0 0
shake 0 0 1 0 0 0 52 0
style 0 0 0 0 0 0 0 32
设定变数
现在你已经知道构建模型所需的输入, 现在设置两个变量, 你可以在构建每个模型时简单地将其重置。你将把它们称为source_dtm和source_tidy。
#assign the source dataset to generic var names
#so we can use a generic function per model
source_dtm <- three_sources_dtm_balanced
source_tidy <- three_sources_tidy_balanced
拟合模型
最后, 你将获得模型拟合的有趣部分。代码很简单, 但是要成为一名优秀的数据科学家, 你需要了解幕后发生的事情。尽管这只是一个粗略的描述, 但在线LDA上有大量信息。为了你的目的, 你只需要知道四个参数:输入, 主题数, 采样方法和种子。
由于你知道数据集包含三个不同的编写器, 因此可以将k设置为3并将种子设置为常数, 以便获得可重复的结果。还有其他控制参数, 因此是代码中的列表格式, 但是你现在仅使用种子。方法参数定义要使用的采样算法。你将使用GIBBS采样方法。默认值为VEM, 但根据我的经验, 它的性能不及替代GIBBS采样方法。
GIBBS采样的简短技术解释是, 它执行随机游走, 该游走始于你可以初始化的某个点(你将使用默认值0), 并在每一步以相等的概率移动正负1。如果你对详细信息感兴趣, 请在此处阅读详细说明。
注意:我已经详细介绍了LDA算法的细节。尽管你不需要了解统计理论即可使用它, 但我建议你阅读Ethen Liu撰写的本文档, 该文档提供了扎实的解释。
k <- 3 #number of topics
seed = 1234 #necessary for reproducibility
#fit the model passing the parameters discussed above
#you could have more control parameters but will just use seed here
lda <- LDA(source_dtm, k = k, method = "GIBBS", control = list(seed = seed))
#examine the class of the LDA object
class(lda)
[1] "LDA_Gibbs"
attr(, "package")
[1] "topicmodels"
你可以在此处看到这创建了一个包含三个主题的LDA_Gibbs对象。由于输出量很大, 我没有在这里运行str(lda), 但请自行进行操作以查看其中包含的内容。
下一步是打开该对象并查看结果。你可以使用tidy()函数将其放置为易于理解的格式。在对tidy()的调用内, 传递LDA对象和矩阵参数的beta。通过测试版可为你提供模型中每个主题每个单词的概率。下面的示例使用术语”冰山”来显示该单词出现在每个主题中的可能性。在主题1中, “冰山”一词更有可能产生。
#convert the LDA object into a tidy format
#passing "beta" shows the word probabilities
#filter on the word iceberg as an example
#results show probability of iceberg for each topic
tidy(lda, matrix = "beta") %>% filter(term == "iceberg")
[#小标题:3 x 3主题字词测试版
1 1冰山0.000198
2 2冰山0.00000292 3 3冰山0.00000315]
用热门单词识别主题
为了清楚地了解模型, 你需要查看每个主题中的术语。构建一个可以整理LDA模型的函数, 并提取每个主题的热门术语。换句话说, 每个主题的术语具有最大的beta值。在此函数内, 你将引用之前构建的word_chart(), 以很好地显示三个主题和最重要的单词。在此示例中, 将num_words设置为10, 但是你可以使用该数字来获得关于主题的不同观点。
num_words <- 10 #number of words to visualize
#create function that accepts the lda model and num word to display
top_terms_per_topic <- function(lda_model, num_words) {
#tidy LDA object to get word, topic, and probability (beta)
topics_tidy <- tidy(lda_model, matrix = "beta")
top_terms <- topics_tidy %>%
group_by(topic) %>%
arrange(topic, desc(beta)) %>%
#get the top num_words PER topic
slice(seq_len(num_words)) %>%
arrange(topic, beta) %>%
#row is required for the word_chart() function
mutate(row = row_number()) %>%
ungroup() %>%
#add the word Topic to the topic labels
mutate(topic = paste("Topic", topic, sep = " "))
#create a title to pass to word_chart
title <- paste("LDA Top Terms for", k, "Topics")
#call the word_chart function you built in prep work
word_chart(top_terms, top_terms$term, title)
}
#call the function you just built!
top_terms_per_topic(lda, num_words)
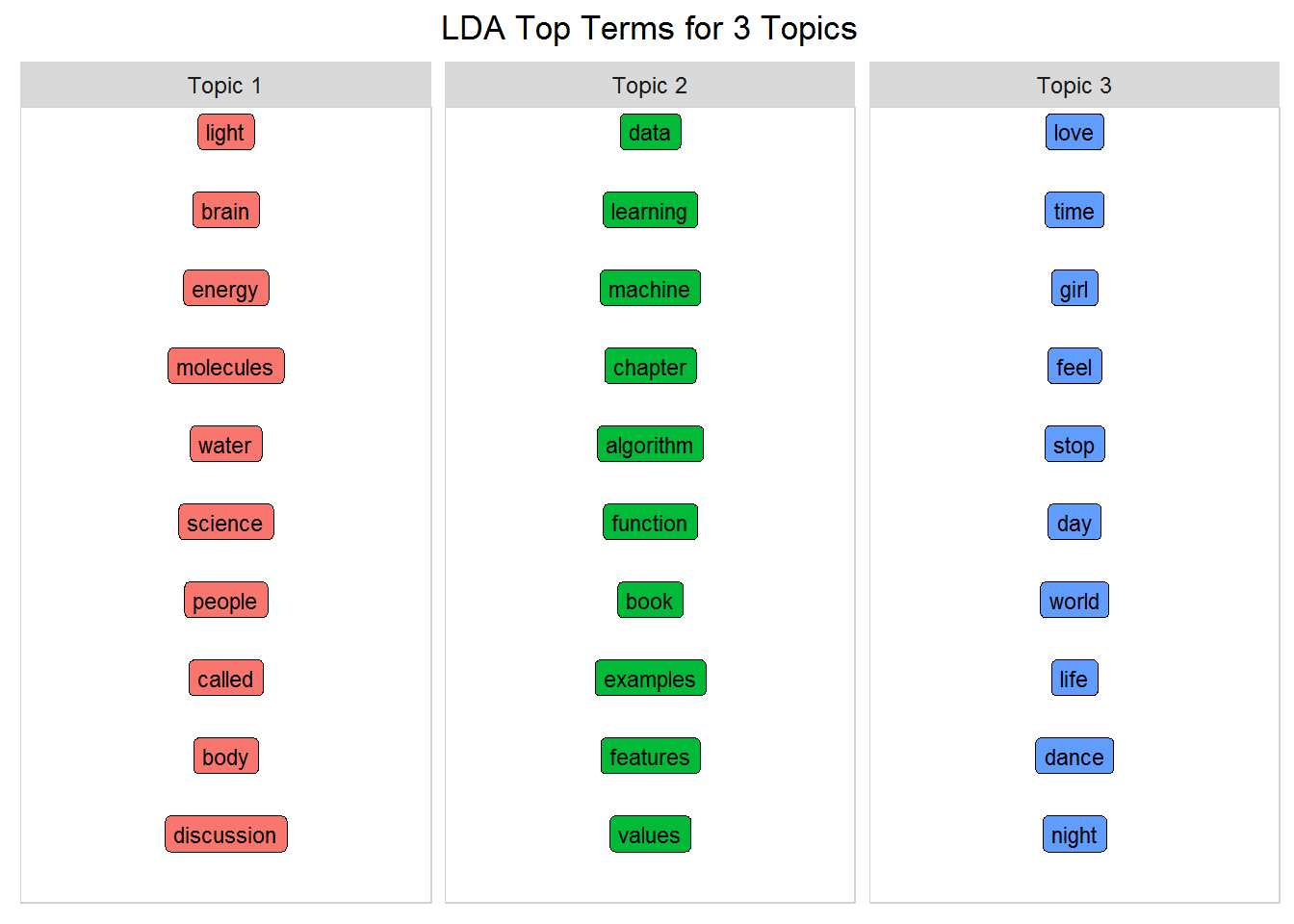
无监督学习总是需要人为解释…但是这些主题清楚地反映了冰山, 机器学习和王子的三个来源!即使这是一个非常简单的示例, 但当你考虑各种可能性时, 它还是非常惊人的!
分类文件
除了将每个主题估计为单词的混合词之外, LDA还将每个文档显示为主题的混合词。这次, 当你整理LDA模型时, 使用matrix =” gamma”, 你将获得每个文档每个主题的概率。例如, 查看Prince的歌曲1999。在这里你会看到, 就像一个单词将与多个主题相关联一样, 文档也是如此。这又回到了混合成员概念。在下面你可以看到1999最有可能出现在主题3中。
#this time use gamma to look at the prob a doc is in a topic
#just look at the Prince song 1999 as an example
tidy(lda, matrix = "gamma") %>% filter(document == "1999")
# A tibble: 3 x 3
document topic gamma
<chr> <int> <dbl>
1 1999 1 0.170
2 1999 2 0.170
3 1999 3 0.661
这首歌属于每个主题, 但以伽玛值表示的百分比不同。有些文档比某些文档更适合某些主题。如上所示, 1999年主题3的伽玛值更高。
和弦图
为了阐明你对LDA的作用的理解, 请看一下该圆形图。该图显示了来自每个来源的文档中属于每个主题的百分比。为了创建它, 请将整齐的LDA模型重新连接到存储实际源(即编写器)的source_tidy, 然后按文档进行连接。然后, 如果你进行适当的分组, 则可以获得每个源, 每个主题的平均伽玛值。现在, 你可以看到每个来源的大多数文档都属于哪个主题。
如果你以前没有使用过圆图, 请花一秒钟时间仔细检查一下。 (请参阅第二部分-A, 了解如何使用chordDiagrams()和circlize软件包。有关该软件包的所有你所需要知道的内容, 在Zuguang Gu的本书中都有介绍。)
#using tidy with gamma gets document probabilities into topic
#but you only have document, topic and gamma
source_topic_relationship <- tidy(lda, matrix = "gamma") %>%
#join to orig tidy data by doc to get the source field
inner_join(three_sources_tidy_balanced, by = "document") %>%
select(source, topic, gamma) %>%
group_by(source, topic) %>%
#get the avg doc gamma value per source/topic
mutate(mean = mean(gamma)) %>%
#remove the gamma value as you only need the mean
select(-gamma) %>%
#removing gamma created duplicates so remove them
distinct()
#relabel topics to include the word Topic
source_topic_relationship$topic = paste("Topic", source_topic_relationship$topic, sep = " ")
circos.clear() #very important! Reset the circular layout parameters
#assign colors to the outside bars around the circle
grid.col = c("prince" = my_colors[1], "icebergs" = my_colors[2], "machine_learning" = my_colors[3], "Topic 1" = "grey", "Topic 2" = "grey", "Topic 3" = "grey")
# set the global parameters for the circular layout. Specifically the gap size (15)
#this also determines that topic goes on top half and source on bottom half
circos.par(gap.after = c(rep(5, length(unique(source_topic_relationship[[1]])) - 1), 15, rep(5, length(unique(source_topic_relationship[[2]])) - 1), 15))
#main function that draws the diagram. transparancy goes from 0-1
chordDiagram(source_topic_relationship, grid.col = grid.col, transparency = .2)
title("Relationship Between Topic and Source")
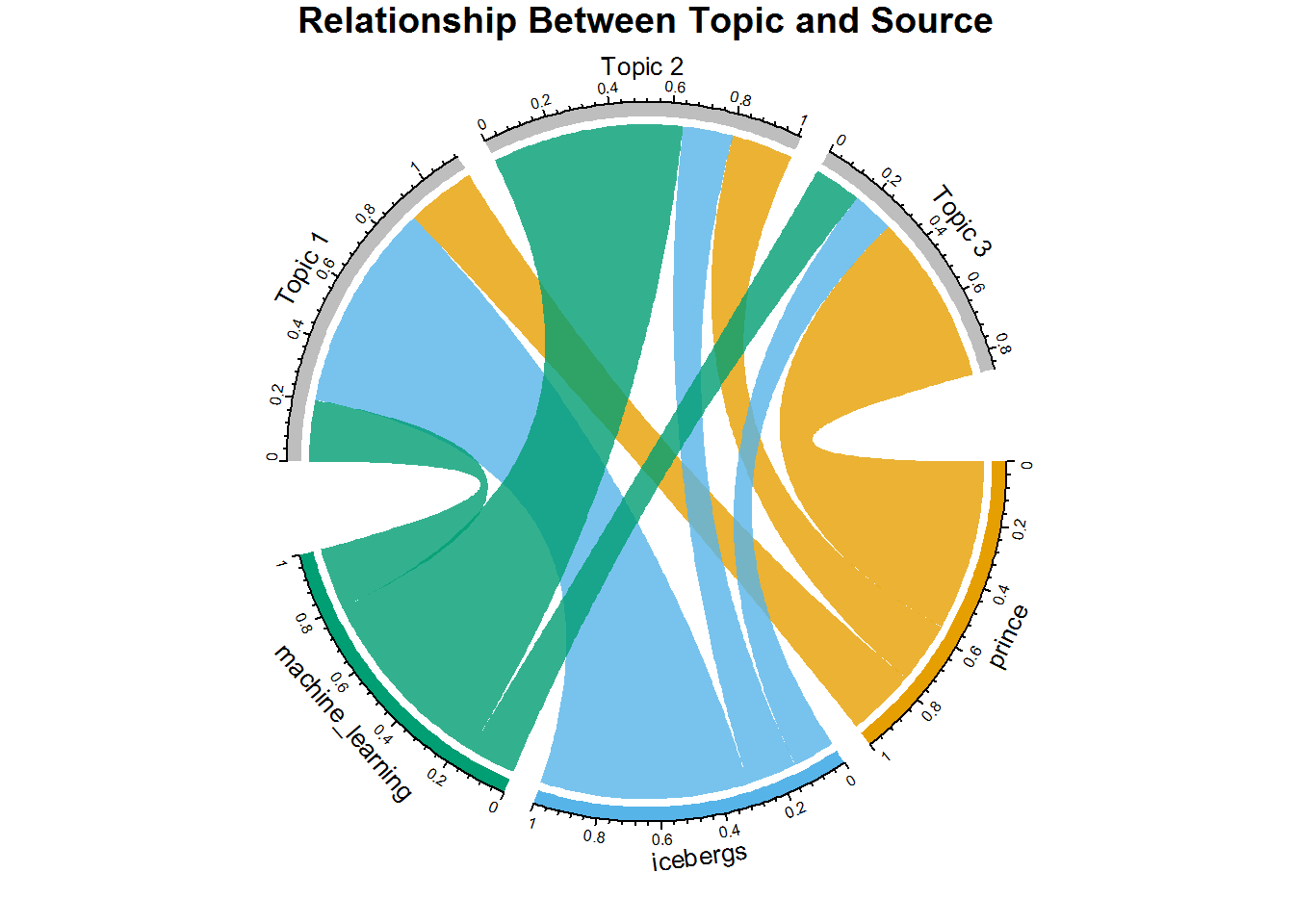
这是一种非常有趣的方式, 即使每个来源的文档都出现在每个主题中, 每个来源显然都在特定主题中占多数。例如, 王子歌曲主要与主题3相关联, 因为该和弦大于主题1和主题2的和弦。 Icebergs和主题1, 机器学习和主题2发生相同的事情。一旦看到这里的模式, 就很清楚正在发生什么。
如果你考虑刚刚完成的工作, 实际上是根据主题/来源的伽马平均值将文档分类为主题。如果你知道文档的作者, 并且知道作者针对特定主题撰写大多数歌词或书籍, 则可以假设类似类型的艺术家会属于同一主题, 因此你可以推荐相似的作家…当查看更大的数据集时, 将练习进行练习。
每个主题的主要文档
现在查看单个文档级别, 并查看每个主题的主要文档。
number_of_documents = 5 #number of top docs to view
title <- paste("LDA Top Documents for", k, "Topics")
#create tidy form showing topic, document and its gamma value
topics_tidy <- tidy(lda, matrix = "gamma")
#same process as used with the top words
top_documents <- topics_tidy %>%
group_by(topic) %>%
arrange(topic, desc(gamma)) %>%
slice(seq_len(number_of_documents)) %>%
arrange(topic, gamma) %>%
mutate(row = row_number()) %>%
ungroup() %>%
#re-label topics
mutate(topic = paste("Topic", topic, sep = " "))
title <- paste("LDA Top Documents for", k, "Topics")
word_chart(top_documents, top_documents$document, title)

识别艺术家/作者
由于你可能不知道文档/歌曲标题的名称(即带下划线的页面来自机器学习书), 因此我将文档名称替换为源名称。
title <- paste("Sources for Top Documents for", k, "Topics")
topics_tidy <- tidy(lda, matrix = "gamma")
top_sources <- top_documents %>%
#join back to the tidy form to get the source field
inner_join(source_tidy) %>%
select(document, source, topic) %>%
distinct() %>%
group_by(topic) %>%
#needed by word_chart (not relevant here)
mutate(row = row_number()) %>%
ungroup()
word_chart(top_sources, top_sources$source, title)

如上图所示, 每个主题的重要文档都被其来源替换。你的代码在对这些文档进行分类方面做得很好, 因为它们属于同一类别(至少对于前五名而言)!最大的问题是, 这是否适用于不止三个来源。如果结果准确, 则可以推荐主题相似的作家。
你将使用另一种机器学习技术(k-means算法)创建第二个模型。与LDA一样, k-means是一种无监督的学习算法, 需要你提前确定主题数。与LDA混合成员模型相反, k均值将文档划分为明显不相交的簇(即主题)。在此, 算法基于相似性度量将文档聚类为不同的组。它将文档转换为数字矢量, 并为每个文档的单词分配权重(类似于tf-idf)。每个文档将恰好显示在一个群集中。这称为硬聚类。输出是一组簇及其文档。相反, LDA是一种模糊(软)聚类技术, 其中一个数据点可以属于多个聚类。
因此, 从概念上讲, 当文本通常包含多个主题时, LDA在应用于自然语言时应比k均值给出更现实的结果, 以进行主题分配。现在建立模型, 检查k-means对象, 看看你的假设是否成立。
设置变量并拟合模型
#use the same three sources you started with
source_dtm <- three_sources_dtm_balanced
source_tidy <- three_sources_tidy_balanced
#Set a seed for replicable results
set.seed(1234)
k <- 3
kmeansResult <- kmeans(source_dtm, k)
str(kmeansResult)
List of 9
$ cluster : Named int [1:1449] 1 3 2 2 3 1 3 2 2 3 ...
..- attr(*, "names")= chr [1:1449] "push it up" "shake" "party up" "style" ...
$ centers : num [1:3, 1:13608] 42 0.01065 0.00758 0 0.01141 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:3] "1" "2" "3"
.. ..$ : chr [1:13608] "push" "shake" "party" "style" ...
$ totss : num 237535
$ withinss : num [1:3] 640 202211 28285
$ tot.withinss: num 231137
$ betweenss : num 6398
$ size : int [1:3] 2 1315 132
$ iter : int 3
$ ifault : int 0
- attr(*, "class")= chr "kmeans"
k均值对象的结构揭示了两个重要的信息:聚类和中心。你可以使用下面的格式查看歌曲1999和该歌曲中出现的单词party的每个变量的内容。
head(kmeansResult$cluster["1999"])
1999
2
head(kmeansResult$centers[, "party"])
1 2 3
0.5000000 0.1269962 0.1439394
这些字段显示1999被放置在单个群集(群集2)中, party在所有三个群集中, 但主要落在群集1中。因此, 现在基于中心值查看最重要的词以识别主题。
用热门单词识别K-Means主题
请记住, 该数据集包含三个来源:Prince, Icebergs和Machine Learning。打印每个群集的关键字, 然后将结果与LDA输出进行比较。为了使用word_chart()函数, 你只需要稍微调整一下数据格式即可。你可以按照代码进行操作, 但是这里的细节并不像对主要单词的实际分析那样重要。
num_words <- 8 #number of words to display
#get the top words from the kmeans centers
kmeans_topics <- lapply(1:k, function(i) {
s <- sort(kmeansResult$centers[i, ], decreasing = T)
names(s)[1:num_words]
})
#make sure it's a data frame
kmeans_topics_df <- as.data.frame(kmeans_topics)
#label the topics with the word Topic
names(kmeans_topics_df) <- paste("Topic", seq(1:k), sep = " ")
#create a sequential row id to use with gather()
kmeans_topics_df <- cbind(id = rownames(kmeans_topics_df), kmeans_topics_df)
#transpose it into the format required for word_chart()
kmeans_top_terms <- kmeans_topics_df %>% gather(id, 1:k)
colnames(kmeans_top_terms) = c("topic", "term")
kmeans_top_terms <- kmeans_top_terms %>%
group_by(topic) %>%
mutate(row = row_number()) %>% #needed by word_chart()
ungroup()
title <- paste("K-Means Top Terms for", k, "Topics")
word_chart(kmeans_top_terms, kmeans_top_terms$term, title)

k均值算法足够聪明, 可以将书籍和音乐之间的主题分开。换句话说, 主题1和3显然是Prince主题, 主题2是这两本书的组合。但是, 它无法像使用LDA一样区分这两本书。可以调整K均值以获得更好的性能, 但是LDA也可以。快速浏览一下, 使用默认参数, k-means的性能似乎不如LDA好, 实际上, 对于主题建模, 通常不使用硬聚类。 (有关其他选择, 请检查槌包装。)
对于此模型, 你将在数据集中使用LDA算法, 并使用12种不同的来源/作者来覆盖多种类型。数据集已经平衡, 每个作者拥有相似数量的文档和单词。以下是数据概述:
检查数据
all_sources_tidy_balanced %>%
group_by(source) %>%
#get the word count and doc count per source
mutate(word_count = n(), source_document_count = n_distinct(document)) %>%
select(source, genre, word_count, source_document_count) %>%
distinct() %>%
ungroup() %>%
#bars change size according to number
#tiles are static sizes
mutate(word_count = color_bar("lightpink")(word_count), source_document_count = color_bar("lightpink")(source_document_count), source = color_tile("lightblue", "lightblue")(source), genre = color_tile("lightgreen", "lightgreen")(genre)) %>%
my_kable_styling("All Sources Stats")
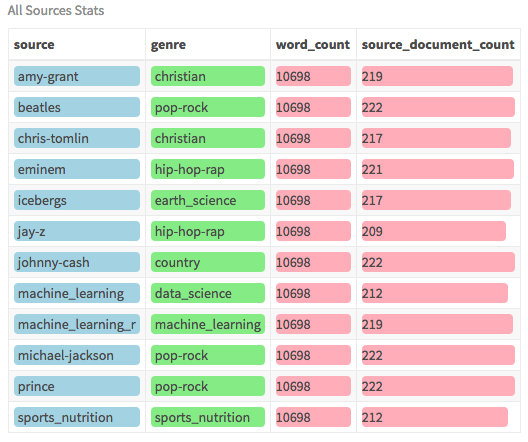
该数据集包含各种各样的艺术家, 从王子, 约翰尼·卡什(国家)到阿姆(说唱), 以及四本不同的书。之所以选择这些艺术家, 是因为他们在各自的流派中排名最高。内容从歌词网站上删除。尽管有两本机器学习书籍, 但一本着重于通用数据科学, 另一本着眼于R编程特定的机器学习。所有书籍均可下载为PDF。 (由于提供了整齐的版本, 因此此分析不需要原始的PDF)。
只是快速清理房间的步骤:对于我们的图表而言, 某些类型的描述太长了, 因此请创建缩写形式以使其更具可读性。
all_sources_tidy_balanced <- all_sources_tidy_balanced %>%
mutate(source = ifelse(source == "machine_learning", "m_learn", ifelse(source == "machine_learning_r", "m_learn_r", ifelse(source == "michael_jackson", "mi_jackson", ifelse(source == "sports_nutrition", "nutrition", source))))) %>%
mutate(genre = ifelse(genre == "machine_learning", "m_learn", ifelse(genre == "sports_nutrition", "nutrition", genre)))
创建DTM并设置变量
#this time use the dataset with 12 sources
all_sources_dtm_balanced <- all_sources_tidy_balanced %>%
count(document, word, sort = TRUE) %>%
ungroup() %>%
cast_dtm(document, word, n)
source_dtm <- all_sources_dtm_balanced
source_tidy <- all_sources_tidy_balanced
拟合模型并确定主题
这次你有十二位作家和八种风格。我希望来自同一类型的作家会被归入同一主题。那才是真正的考验。因此, 将主题数设置为8, 然后使用更大的数据集再次拟合模型。
k <- 8 #number of topics chosen to match the number of genres
num_words <- 10 #number of words we want to see in each topic
seed = 1234 #make it repeatable
#same as before
lda <- LDA(source_dtm, k = k, method = "GIBBS", control = list(seed = seed))
top_terms_per_topic(lda, num_words)

不影响你的意见, 但我的反应是:”哇!”在此模型的输入下, 你可以看到主题吗?查看每个主题, 并尝试将其与八种已知类型相匹配。有些将很难区分, 但另一些则将是显而易见的。例如, 这里有一些解释的可能性:
- 主题一-机器学习与数据科学
- 主题二-流行/摇滚
- 主题三:运动营养
- 主题四-国家
- 主题五-嘻哈说唱
- 主题六-国家或流行摇滚
- 主题七-冰山, 地球科学
- 主题八-宗教
不要忘记混合成员概念, 并且这些主题并不意味着完全脱节, 但是让我惊讶的是, 结果如你在这里看到的那样离散。恰如其分:LDA算法使用的参数比你使用的参数更多, 因此你可以调整模型以使其更强大。
下一部分真的很令人兴奋。你如何才能更轻松地了解这些主题的含义?在大多数情况下, 很难解释, 但是使用正确的数据集, 模型可以表现良好。如果你的模型可以确定哪些文档更可能属于每个主题, 则可以开始将作者归为一组。而且由于你的情况, 你知道作家的类型, 因此可以在一定程度上验证你的结果!第一步是对每个文档进行分类。
分类文件
和弦图
提醒一下, 每个文档都包含多个主题, 但是以gamma值表示的百分比不同。一些文档比某些主题更适合某些主题。该图显示了每个主题的每个来源的文档的平均伽玛值。这与你以前与三位作者使用的方法相同, 只是这次你将查看流派字段。这是展示作者类型与主题之间关系的一种奇妙方式。
source_topic_relationship <- tidy(lda, matrix = "gamma") %>%
#join to the tidy form to get the genre field
inner_join(source_tidy, by = "document") %>%
select(genre, topic, gamma) %>%
group_by(genre, topic) %>%
#avg gamma (document) probability per genre/topic
mutate(mean = mean(gamma)) %>%
select(genre, topic, mean) %>%
ungroup() %>%
#re-label topics
mutate(topic = paste("Topic", topic, sep = " ")) %>%
distinct()
circos.clear() #very important! Reset the circular layout parameters
#this is the long form of grid.col just to show you what I'm doing
#you can also assign the genre names individual colors as well
grid.col = c("Topic 1" = "grey", "Topic 2" = "grey", "Topic 3" = "grey", "Topic 4" = "grey", "Topic 5" = "grey", "Topic 6" = "grey", "Topic 7" = "grey", "Topic 8" = "grey")
#set the gap size between top and bottom halves set gap size to 15
circos.par(gap.after = c(rep(5, length(unique(source_topic_relationship[[1]])) - 1), 15, rep(5, length(unique(source_topic_relationship[[2]])) - 1), 15))
chordDiagram(source_topic_relationship, grid.col = grid.col, annotationTrack = "grid", preAllocateTracks = list(track.height = max(strwidth(unlist(dimnames(source_topic_relationship))))))
#go back to the first track and customize sector labels
#use niceFacing to pivot the label names to be perpendicular
circos.track(track.index = 1, panel.fun = function(x, y) {
circos.text(CELL_META$xcenter, CELL_META$ylim[1], CELL_META$sector.index, facing = "clockwise", niceFacing = TRUE, adj = c(0, 0.5))
}, bg.border = NA) # here set bg.border to NA is important
title("Relationship Between Topic and Genre")
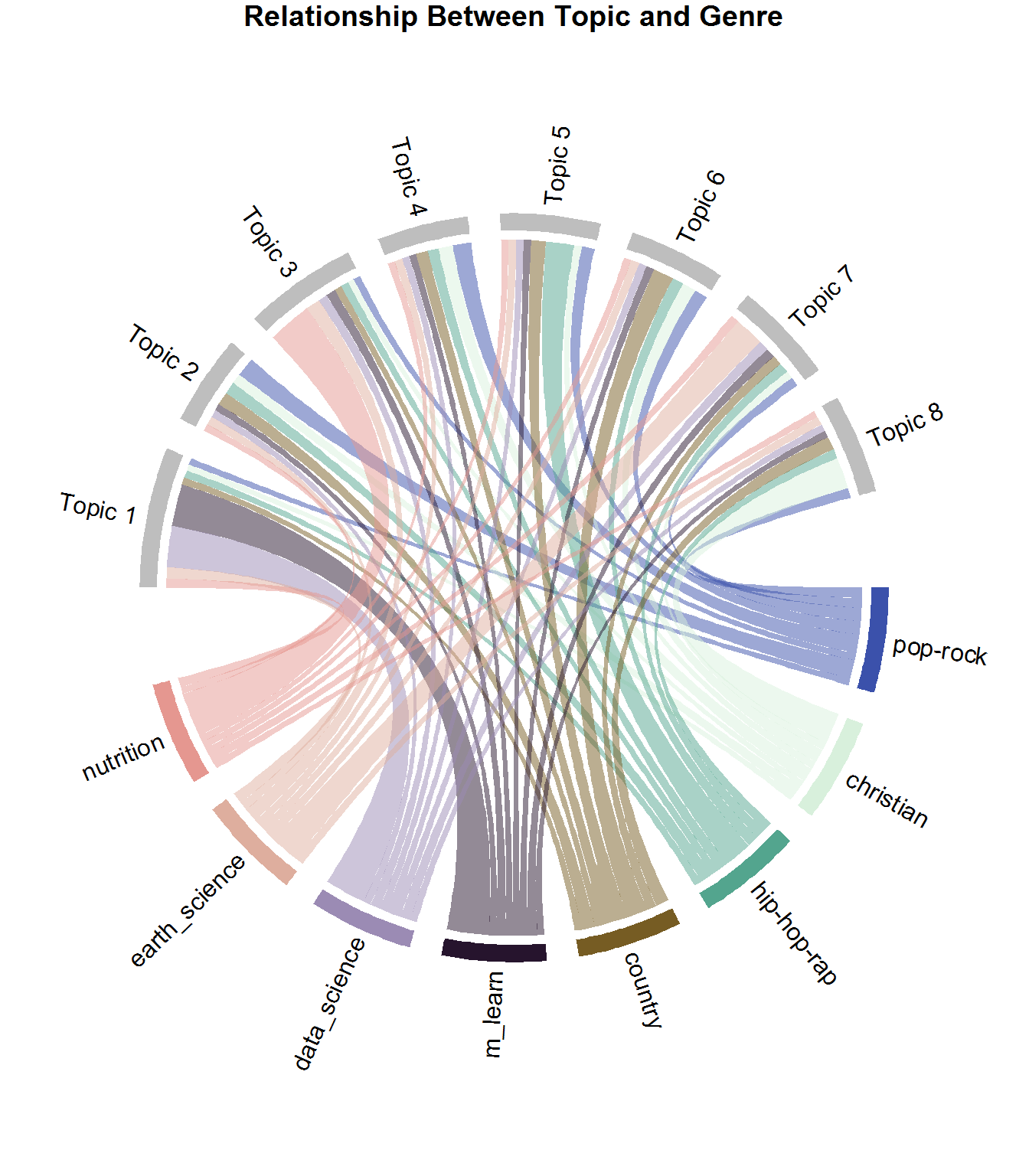
每个和弦(即链接)代表属于主题的每种流派的平均伽玛值。如果查看sports_nutrition部分, 你会看到主题3的和弦大于其其他和弦。这意味着更多的运动营养页面属于该主题。显然, 大多数机器学习和数据科学页面都属于主题1;地球科学的大多数文献都属于主题7, 正如你所期望的, Pop-Rock在多个主题之间划分得相当好。这完全有道理, 因为按照定义, Pop代表流行, 是一种广义的流派。另一方面, Rap-Hip-Hop在主题5中更为常见。那么你可以使用此信息做什么?你可以根据主题内容向听众提出建议!
当然, 抒情内容不一定是推荐系统使用的唯一功能, 而是可以与元数据(例如节奏, 乐器, 速度等)组合在一起, 以获得更好的聆听体验。
推荐类似作家
现在你可以查看文档和主题之间的关系, 按来源(即作者)和主题进行分组, 并获得每组的伽玛值总和。然后使用top_n(1)为每个主题选择具有最高topic_sum的作者。由于你想要对类型进行与在writer上相同的操作, 因此创建一个名为top_items_per_topic()的函数并将source作为类型传递。这样, 当你按类型对文档进行分类时, 便可以再次调用它。
这是你实际将作者映射到特定主题的关键时刻。你期望会发生什么?
#this function can be used to show genre and source via passing the "type"
top_items_per_topic <- function(lda_model, source_tidy, type) {
#get the tidy version by passing gamma for the per document per topic probs
document_lda_gamma <- tidy(lda_model, matrix = "gamma") %>%
#join to the tidy form to get source and genre
inner_join(source_tidy) %>%
select(document, gamma, source, genre, topic) %>%
distinct() %>% #remove duplicates
#group so that you can get sum per topic/source
group_by(source, topic) %>%
#sort by decending gamma value
arrange(desc(gamma)) %>%
#create the sum of all document gamma vals per topic/source. Important!
mutate(topic_sum = sum(gamma)) %>%
select(topic, topic_sum, source, genre) %>%
distinct() %>%
ungroup() %>%
#type will be either source or genre
group_by(source, genre ) %>%
#get the highest topic_sum per type
top_n(1, topic_sum) %>%
mutate(row = row_number()) %>%
mutate(label = ifelse(type == "source", source, genre), title = ifelse(type == "source", "Recommended Writers Per Topic", "Genres Per Topic")) %>%
ungroup() %>%
#re-label topics
mutate(topic = paste("Topic", topic, sep = " ")) %>%
select(label, topic, title)
#slightly different format from word_chart input, so use this version
document_lda_gamma %>%
#use 1, 1, and label to use words without numeric values
ggplot(aes(1, 1, label = label, fill = factor(topic) )) +
#you want the words, not the points
geom_point(color = "transparent") +
#make sure the labels don't overlap
geom_label_repel(nudge_x = .2, direction = "y", box.padding = 0.1, segment.color = "transparent", size = 3) +
facet_grid(~topic) +
theme_lyrics() +
theme(axis.text.y = element_blank(), axis.text.x = element_blank(), axis.title.y = element_text(size = 4), panel.grid = element_blank(), panel.background = element_blank(), panel.border = element_rect("lightgray", fill = NA), strip.text.x = element_text(size = 9)) +
xlab(NULL) + ylab(NULL) +
ggtitle(document_lda_gamma$title) +
coord_flip()
}
top_items_per_topic(lda, source_tidy, "source")

这真让人兴奋!但是, 由于你可能不太了解这些艺术家, 因此, 我将通过以该类型代替作家来弄清楚。做好准备…
按类型推荐类似文件
top_items_per_topic(lda, source_tidy, "genre")

嘻哈歌手们聚集在一起;基督徒艺术家在一起。两位流行摇滚艺术家在一起, 每本书都有自己的主题!令人惊奇的是, 无监督学习可以完全基于文本产生这样的结果(识别不同体裁)。如果你选择不同数量的主题会怎样?它会组合或分开哪些类型?也许你可以自己尝试一下。现在, 你的下一个模型将集中于你在先前教程中使用的Prince数据集。
对于此模型, 你将仅将数据集与Prince歌曲一起使用。尽管歌词中涵盖了不同的主题, 但通常一首歌涵盖多个主题。当你的数据集中只有一位艺术家时, 你的主题将变得更加混杂且不那么混乱。这使解释成为非常关键的一步。你将使用如下所述的略有修改的版本, 而不是使用Prince歌词中的原始数据。
使用NLP改进模型
以前, 你已经使用了出现在文本中的单词。但是现在, 你将使用由带注释的NLP软件包(称为cleanNLP)产生的数据的带注释的形式。该软件包是用于自然语言处理的整洁数据模型, 可提供注释任务, 例如标记化, 语音标记, 命名实体识别, 实体链接, 情感分析以及许多其他任务。该练习是在本教程之外进行的, 但是我提供了主题建模所需的全部内容。
检查NLP输出
在带注释的数据集中, Prince歌词的语料库中的每个单词都有一行, 其中包含有关每个单词的重要信息。
通过检查字段名称来仔细查看标记化注释对象。
#read in the provided annotated dataset
prince_annotated <- read.csv("prince_data_annotated.csv")
#look at the fields provided in the dataset
names(prince_annotated)
[1] "X" "id" "sid" "tid" "word"
[6] "lemma" "upos" "pos" "cid" "pid"
[11] "case" "definite" "degree" "foreign" "gender"
[16] "mood" "num_type" "number" "person" "poss"
[21] "pron_type" "reflex" "tense" "verb_form" "voice"
目前, 你将仅利用以下两条信息:
- 引理(lemma):词素化的形式(即, 将变形词还原为其基本形式的形式)
- upos:每个单词的语音通用部分
单词字段是原始单词, 而引理是词素化的版本。 upos是语音代码的通用部分。如果你在upos上调用table(), 则会看到落入语音的每个标记部分的单词计数。 (请注意, 某些单词可能会多次标记。)
table(prince_annotated$upos)
ADJ ADP ADV AUX CCONJ DET INTJ NOUN NUM PART PRON PROPN
15193 19157 20439 19855 5601 20777 5399 48047 5439 10087 50932 523
SCONJ SYM VERB X
5626 72 43673 3095
为了让你大致了解数据的样子, 请放大几首内引词与原始单词不同的歌曲, 然后删除停用词。
prince_annotated %>%
#most lemmas are the same as the raw word so ignore those
filter((as.character(word) != as.character(lemma))
& (id %in% c("broken", "1999"))) %>% #filter on 2 songs
anti_join(stop_words) %>%
select(song = id, word, lemma, upos) %>%
distinct() %>%
my_kable_styling("Annotated Subset")
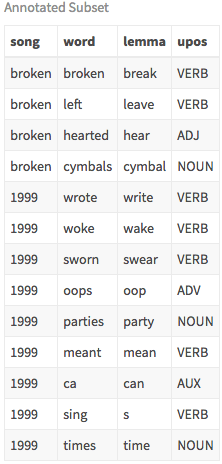
这显示了你如何选择模型中的内容(即单词, 引理或词性)。这实际上是关于使用去修饰词还是原始词的判断。或者, 你甚至可能想要使用第二部分-A中提到的词干(词干)的另一种形式。你也可能会质疑cleanNLP的结果, 以及确定是名词还是形容词的结果。我建议你尝试几种不同的配置, 直到找到最适合你的配置。
在本教程中, 你将仅对名词建模。为了获取相关的Prince元数据(例如流派和年份), 请按单词和文档将prince_annotated加入prince_tidy, 然后照常创建DTM。我选择删除所有主题中都存在的一些非常常见的单词, 只是为了使其有趣。 (请注意, 使用第1部分中介绍的tf-idf概念是你可以考虑删除常用单词的另一种方法。)
使用NLP设置变量
source_tidy <- prince_annotated %>%
select(document = id, word, lemma, upos) %>%
filter(upos == "NOUN") %>% #choose only the nouns
inner_join(prince_tidy, by = c("word", "document")) %>%
select(document, word, lemma, upos, source, genre, year) %>%
distinct()
source_dtm <- source_tidy %>%
#filter out some words that exist across themes just for our purposes
filter(!word %in% c("love", "time", "day", "night", "girl")) %>%
count(document, word, sort = TRUE) %>%
ungroup() %>%
cast_dtm(document, word, n)
拟合模型并确定主题
#Changing these parameters or the source data will cause different results!!
k <- 7
num_words <- 6
seed = 4321
lda <- LDA(source_dtm, k = k, method = "GIBBS", control = list(seed = seed))
top_terms_per_topic(lda, num_words)

以下是多年来人们将其标记为王子音乐中潜在主题的主题列表。它们用某些单词标记, 并且与所有主题建模一样, 存在重叠。但是, 请查看这些手动标记的主题(以随机顺序列出!), 看看是否可以在构建的模型中找到它们。
- 爱, 时间, 生活
- 人, 家人
- 战争, 和平, 争议, 自由
- 疼痛悲伤悲伤
- 性别, 毒品
- 自我, 社会, 宗教
- 音乐, 舞蹈, 聚会
你的主题1似乎与人和家庭有关;主题7是关于音乐, 舞蹈和聚会的;主题4是关于自我, 社会和宗教的。这需要非常主观的解释。在业务环境中, 此步骤最好由可能对预期有想法的主题专家执行。现在你可以了解为什么NLP真正是人工智能和计算语言学的交集!
尝试使用不同数量的主题或仅使用动词, 或者使用原始单词与经过修饰的形式, 或者使用不同数量的热门单词来运行此功能, 并查看可以得出的见解。有一些新方法可以帮助你确定主题数:请参见此处的困惑概念或此处的ldatuning软件包。
随着时间的主题
由于Prince数据集包含年份, 因此你可以随时间跟踪主题。你在这里可能真的很有创造力, 但现在只看两个主题中的几句话, 并查看一段时间内的频率。趋势分析本身可能就是一个完整的教程, 因此, 如果你真的有兴趣, 请查看此资源。
p1 <- prince_tidy %>%
filter(!year == "NA") %>% #remove songs without years
filter(word %in% c("music", "party", "dance")) %>%
group_by(year) %>%
mutate(topic_7_count = n()) %>%
select(year, topic_7_count) %>%
distinct() %>%
ggplot(aes(year, topic_7_count)) + geom_smooth(se = FALSE, col = "red")
p2 <- prince_tidy %>%
filter(!year == "NA") %>% #remove songs without years
filter(word %in% c("heaven", "hand", "soul")) %>%
group_by(year) %>%
mutate(topic_4_count = n()) %>%
select(year, topic_4_count) %>%
distinct() %>%
ggplot(aes(year, topic_4_count)) + geom_smooth(se = FALSE)
grid.arrange(p1, p2, ncol = 2)
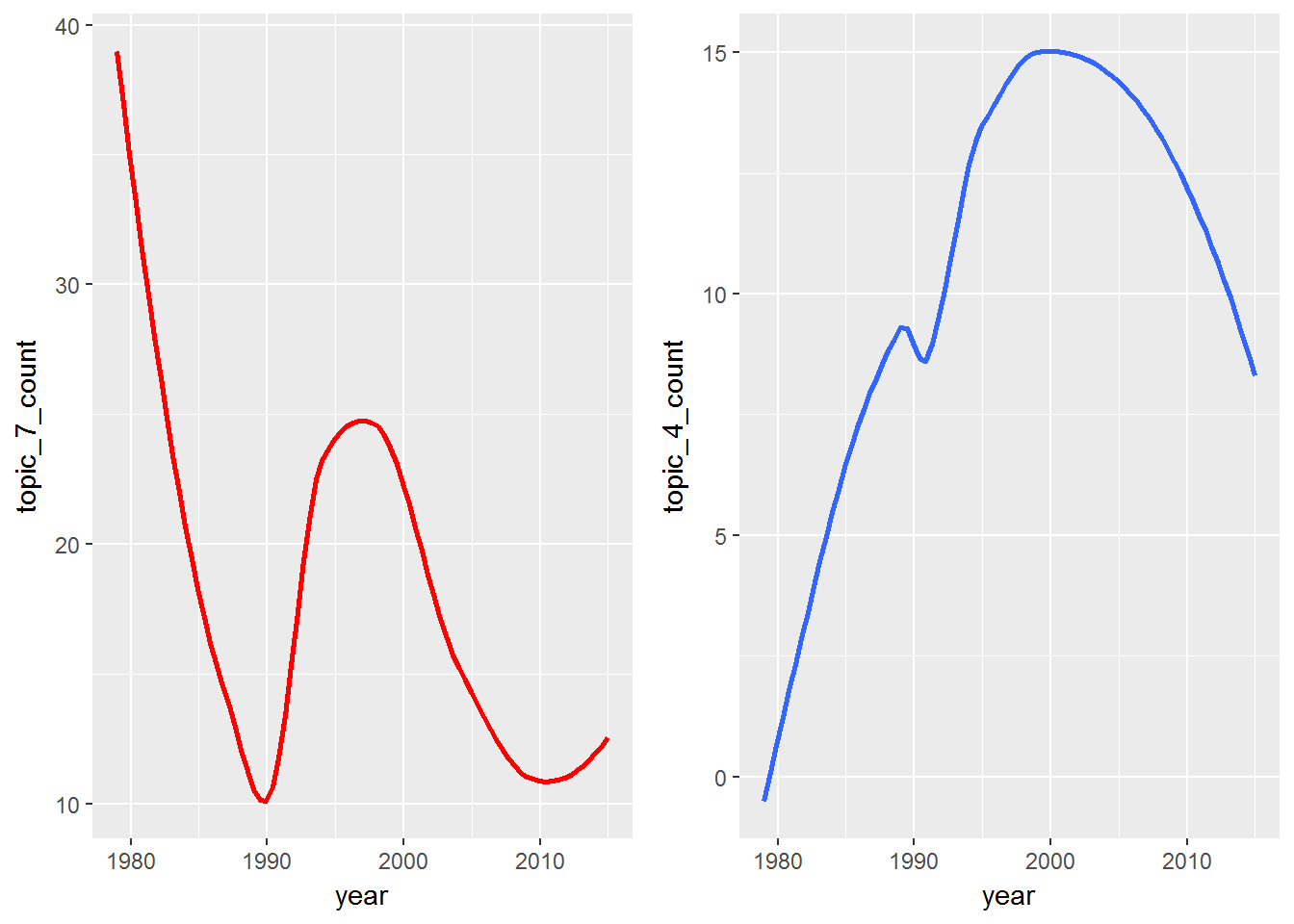
这是主题随时间变化的极其原始的示例, 但是如果你将这种分析类型扩展到音乐之外怎么办?也许你的公司对产品销售与有关你产品的客户推文中的趋势主题之间的相关性感兴趣。有许多应用程序可用于理解主题随时间的变化。
本教程仅概述主题建模, NLP和机器学习的功能。这是数据科学的新兴领域, 并且随着越来越多的科学家解决未遍历的非结构化数据海洋, 它将继续蓬勃发展。在音乐中, 基于歌词对歌曲进行分类的概念主要出现在研究论文中, 因此也许你可以跳出这份工作, 为AI世界做出自己的贡献。
你使用了来自歌词和非小说类书籍的数据来识别主题, 将单个文档分类为最可能的主题, 并根据主题内容来识别相似的作者。这样, 你就可以基于文本和带标签的作者构建一个简单的推荐系统。
保持最小;你正在尝试使用机器为艺术品建模。艺术家可以说”你是我的眼睛中的苹果”, 但它们并不是指水果或身体部位。你必须找到隐藏的内容。当你听音乐时, 你并不总是听到背景声, 但是它们在那里。调出你喜欢的歌曲, 聆听主唱的声音, 你可能会惊讶地发现一个隐藏信息的世界。因此, 在探索过程中将逻辑放在后台, 将创造力带到最前沿!
像本系列中的所有教程一样, 我鼓励你使用此处提供的数据作为一个有趣的案例研究, 也可以用作分析你感兴趣的文本的想法生成器。它可能是你自己喜欢的艺术家, 社交媒体, 公司, 科学或社会经济文本。你对主题建模的潜在应用有何看法?请在下面留下你的想法的评论!
请继续关注本系列的第三部分(第四篇文章):歌词分析:使用R进行机器学习的预测分析。在这里, 你将使用歌词和标记的元数据来预测歌曲的未来。你将使用决策树, 朴素贝叶斯等几种不同算法, 以及更多算法来预测类型, 十年, 甚至可能预测一首歌曲是否会排行榜!我希望很快能见到你!
注意事项:
注意事项一:获得相同结果的唯一方法是, 如果你对相同的未修改数据文件以完全相同的顺序运行代码。否则, 参考特定主题将毫无意义。
警告二:这项工作没有严格的规定, 这是基于我自己的研究。尽管现实世界中确实存在主题建模, 但是围绕完全基于歌词开发音乐推荐器的活动并不多。
警告三:主题建模很棘手。建立模型是一回事, 但解释结果具有挑战性, 主观性且难以完全验证(尽管正在进行研究:请参阅Thomas W. Jones的这篇文章)。该过程是无监督的, 生成的, 迭代的并且基于概率。主题是微妙的, 隐藏的和暗示的, 而不是明确的。
如果你想了解更多有关使用R进行机器学习的信息, 请查看我们的初学者教程。另外, 参加我们的机器学习入门课程。
评论前必须登录!
注册