 srcmini
srcmini在机器学习中, 学习的类型大致可分为三类:1.监督学习, 2。非监督学习和3.半监督学习。属于无监督学习家族的算法没有变量可以预测与数据相关。数据没有输入, 而只有输入, 该输入将是描述数据的多个变量。这就是群集的作用。
一定要看一看我们的Python无监督学习课程。
群集的任务是将一组对象组合在一起, 以使同一群集中的对象彼此之间的相似性高于其他群集中的对象。相似度是反映两个数据对象之间关系强度的度量。聚类主要用于探索性数据挖掘。它在机器学习, 模式识别, 图像分析, 信息检索, 生物信息学, 数据压缩和计算机图形学等许多领域都有广泛的用途。
但是, 本文试图阐明K-Means的内部工作原理, 这是一种非常流行的聚类技术。在K-Means上还有一篇非常不错的srcmini帖子, 其中通过案例研究说明了聚类的类型(硬聚类和软聚类), 聚类方法的类型(连通性, 质心, 分布和密度)。该算法将帮助你处理未标记的数据集(即没有任何类标签的数据集), 并轻松地从中得出自己的推断。
K-Means属于基于质心的聚类。重心是群集中心的数据点(虚部或实部)。在基于质心的聚类中, 聚类由中心向量或质心表示。此质心可能不一定是数据集的成员。基于质心的聚类是一种迭代算法, 其中相似性的概念是通过数据点与聚类的质心的接近程度得出的。
在这篇文章中, 你将了解:
- K-Means算法的内部运作
- 一个简单的Python案例研究
- K-Means的缺点
K-Means聚类算法的内部工作原理:
为此, 你将需要一个样本数据集(训练集):
| 对象 | X | 和 | 同 |
|---|---|---|---|
| OB-1 | 1 | 4 | 1 |
| OB-2 | 1 | 2 | 2 |
| OB-3 | 1 | 4 | 2 |
| OB-4 | 2 | 1 | 2 |
| OB-5 | 1 | 1 | 1 |
| OB-6 | 2 | 4 | 2 |
| OB-7 | 1 | 1 | 2 |
| OB-8 | 2 | 1 | 1 |
样本数据集包含8个对象, 它们的X, Y和Z坐标。你的任务是将这些对象聚类为两个聚类(在这里, 你将(K均值的)K的值定义为2)。
因此, 该算法的工作原理是:
- 最初考虑其帐户中的任何两个质心或数据点(因为你将2取为K, 因此质心的数量也为2)。
- 选择质心后(例如C1和C2), 数据点(此处的坐标)将分配给任何聚类(让我们暂时取质心=聚类), 具体取决于它们和质心之间的距离。
- 假设算法选择OB-2(1, 2, 2)和OB-6(2, 4, 2)作为质心, 同时选择聚类1和聚类2。
- 为了测量距离, 你需要使用以下距离测量功能(也称为相似性测量功能):
$ d = | x2 – x1 | + | y2 – y1 | + | z2 – z1 | $
这也称为计程车距离或曼哈顿距离, 其中d是两个对象之间的距离测量值, (x1, y1, z1)和(x2, y2, z2)是针对以下两个对象获取的任何X, Y和Z坐标距离测量。
随时查看其他距离测量功能, 例如欧几里得距离, 余弦距离等。
下表显示了对象和质心(OB-2和OB-6)之间的距离(使用上述距离测量功能)的计算:
| 对象 | X | 和 | 同 | Distance from C1(1, 2, 2) | Distance from C2(2, 4, 2) |
|---|---|---|---|---|---|
| OB-1 | 1 | 4 | 1 | 3 | 2 |
| OB-2 | 1 | 2 | 2 | 0 | 3 |
| OB-3 | 1 | 4 | 2 | 2 | 1 |
| OB-4 | 2 | 1 | 2 | 2 | 3 |
| OB-5 | 1 | 1 | 1 | 2 | 5 |
| OB-6 | 2 | 4 | 2 | 3 | 0 |
| OB-7 | 1 | 1 | 2 | 1 | 4 |
| OB-8 | 2 | 1 | 1 | 3 | 4 |
根据对象在质心之间的距离对对象进行聚类。一个质心(例如C1)之间的距离比另一个质心(例如C2)短的对象将落入C1的簇中。在初始通过集群之后, 集群对象将如下所示:
| 集群1 |
|---|
| OB-2 |
| OB-4 |
| OB-5 |
| OB-7 |
| OB-8 |
| 集群2 |
|---|
| OB-1 |
| OB-3 |
| OB-6 |
现在, 该算法将继续更新聚类质心(即坐标), 直到无法再对其进行更新(有关何时无法稍后更新的更多信息)。更新以下列方式发生:
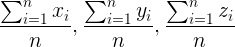
(其中n =属于该特定集群的对象数)
因此, 遵循此规则, 更新后的群集1将为((1 + 2 + 1 + 1 + 2)/ 5, (2 + 1 + 1 + 1 + 1)/ 5, (2 + 2 + 1 + 2 + 1 )/ 5)=(1.4, 1.2, 1.6)。对于群集2, 它将是((1 + 1 + 2)/ 3, (4 + 4 + 4)/ 3, (1 + 2 + 2)/ 3)=(1.33, 4, 1.66)。
此后, 该算法再次开始查找数据点与新导出的聚类质心之间的距离。因此, 新距离将如下所示:
| 对象 | X | 和 | 同 | Distance from C1(1.4, 1.2, 1.6) | Distance from C2(1.33, 4, 1.66) |
|---|---|---|---|---|---|
| OB-1 | 1 | 4 | 1 | 3.8 | 1 |
| OB-2 | 1 | 2 | 2 | 1.6 | 2.66 |
| OB-3 | 1 | 4 | 2 | 3.6 | 0.66 |
| OB-4 | 2 | 1 | 2 | 1.2 | 4 |
| OB-5 | 1 | 1 | 1 | 1.2 | 4 |
| OB-6 | 2 | 4 | 2 | 3.8 | 1 |
| OB-7 | 1 | 1 | 2 | 1 | 3.66 |
| OB-8 | 2 | 1 | 1 | 1.4 | 4.33 |
关于更新集群的对象的新分配将是:
| 集群1 |
|---|
| OB-2 |
| OB-4 |
| OB-5 |
| OB-7 |
| OB-8 |
| 集群2 |
|---|
| OB-1 |
| OB-3 |
| OB-6 |
这是算法不再更新质心的地方。因为当前簇的组成没有变化, 所以它与先前的簇相同。
现在, 当你完成了使用K均值的聚类形成后, 你可以将其应用于算法以前从未见过的某些数据(称为测试集)。让我们生成:
| 对象 | X | 和 | 同 |
|---|---|---|---|
| OB-1 | 2 | 4 | 1 |
| OB-2 | 2 | 2 | 2 |
| OB-3 | 1 | 2 | 1 |
| OB-4 | 2 | 2 | 1 |
在上述数据集上应用K均值后, 最终的聚类将是:
| 集群1 |
|---|
| OB-2 |
| OB-3 |
| OB-4 |
| 集群2 |
|---|
| OB-1 |
如果不确定算法的性能, 则该算法的任何应用都不完整。现在, 为了知道K-Means算法的性能如何, 有一些指标需要考虑。这些指标包括:
- 调整后的兰特指数
- 基于互信息的评分
- 同质性, 完整性和v测度
现在你已经熟悉了K-Means的内部机制, 让我们看看K-Means的实际作用。
一个简单的Python中的K-Means案例研究:
对于实现部分, 你将使用Titanic数据集(在此处可用)。在继续进行之前, 我想讨论一下有关数据本身的一些事实。 RMS泰坦尼克号沉没是历史上最臭名昭著的沉船之一。 1912年4月15日, 泰坦尼克号在处女航途中与冰山相撞后沉没, 使2224名乘客和机组人员中的1502人丧生。这一耸人听闻的悲剧震惊了国际社会, 并导致了更好的船舶安全规定。
沉船事故导致人员丧生的原因之一是没有足够的救生艇供乘客和船员使用。尽管在下沉中幸存有一定的运气, 但是某些群体比其他群体更可能生存, 例如妇女, 儿童和上层阶级。
现在, 谈论数据集, 训练集包含有关泰坦尼克号乘客的几条记录(因此称为数据集)。它具有12个功能, 可捕获有关旅客舱位, 入境口岸, 票价等信息。数据集的标签为生存, 表示特定乘客的生存状态。你的任务是将记录分为两部分, 即幸存的记录和未幸存的记录。
你可能会认为, 由于它是标记的数据集, 如何将其用于聚类任务?你只需要从数据集中删除”生存”列, 并使其未标记即可。 K-Means的任务是对数据集的记录进行生存或不生存的聚类。
对于本教程, 你将需要以下Python软件包:pandas, NumPy, scikit-learn, Seaborn和Matplotlib。
# Dependencies
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
你已经导入了本教程中需要的所有依赖项。现在, 你将加载数据集。
# Load the train and test datasets to create two DataFrames
train_url = "http://s3.amazonaws.com/assets.srcmini02.com/course/Kaggle/train.csv"
train = pd.read_csv(train_url)
test_url = "http://s3.amazonaws.com/assets.srcmini02.com/course/Kaggle/test.csv"
test = pd.read_csv(test_url)
通过打印来自训练和测试DataFrame的一些样本, 让我们预览将要使用的数据类型。
print("***** Train_Set *****")
print(train.head())
print("\n")
print("***** Test_Set *****")
print(test.head())
***** Train_Set *****
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S
***** Test_Set *****
PassengerId Pclass Name Sex \
0 892 3 Kelly, Mr. James male
1 893 3 Wilkes, Mrs. James (Ellen Needs) female
2 894 2 Myles, Mr. Thomas Francis male
3 895 3 Wirz, Mr. Albert male
4 896 3 Hirvonen, Mrs. Alexander (Helga E Lindqvist) female
Age SibSp Parch Ticket Fare Cabin Embarked
0 34.5 0 0 330911 7.8292 NaN Q
1 47.0 1 0 363272 7.0000 NaN S
2 62.0 0 0 240276 9.6875 NaN Q
3 27.0 0 0 315154 8.6625 NaN S
4 22.0 1 1 3101298 12.2875 NaN S
你可以使用pandas的describe()方法获得有关Train和Test DataFrame的一些初始统计信息。
print("***** Train_Set *****")
print(train.describe())
print("\n")
print("***** Test_Set *****")
print(test.describe())
***** Train_Set *****
PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 714.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008
std 257.353842 0.486592 0.836071 14.526497 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000
75% 668.500000 1.000000 3.000000 38.000000 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000
Parch Fare
count 891.000000 891.000000
mean 0.381594 32.204208
std 0.806057 49.693429
min 0.000000 0.000000
25% 0.000000 7.910400
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 512.329200
***** Test_Set *****
PassengerId Pclass Age SibSp Parch Fare
count 418.000000 418.000000 332.000000 418.000000 418.000000 417.000000
mean 1100.500000 2.265550 30.272590 0.447368 0.392344 35.627188
std 120.810458 0.841838 14.181209 0.896760 0.981429 55.907576
min 892.000000 1.000000 0.170000 0.000000 0.000000 0.000000
25% 996.250000 1.000000 21.000000 0.000000 0.000000 7.895800
50% 1100.500000 3.000000 27.000000 0.000000 0.000000 14.454200
75% 1204.750000 3.000000 39.000000 1.000000 0.000000 31.500000
max 1309.000000 3.000000 76.000000 8.000000 9.000000 512.329200
因此, 从上面的输出中, 你绝对可以了解数据集的功能及其一些基本统计信息。我将为你列出功能名称:
print(train.columns.values)
['PassengerId' 'Survived' 'Pclass' 'Name' 'Sex' 'Age' 'SibSp' 'Parch'
'Ticket' 'Fare' 'Cabin' 'Embarked']
需要特别注意的是, 并非所有的机器学习算法都支持你要提供给它们的数据中的缺失值。 K-均值就是其中之一。因此, 我们需要处理数据中存在的缺失值。首先让我们看一下缺少的值:
# For the train set
train.isna().head()
# For the test set
test.isna().head()
让我们获取两个数据集中缺失值的总数。
print("*****In the train set*****")
print(train.isna().sum())
print("\n")
print("*****In the test set*****")
print(test.isna().sum())
*****In the train set*****
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
*****In the test set*****
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
因此, 你可以在训练集中看到”年龄”, “机舱”和”登机”列中的值缺失, 而在测试集中, “年龄”和”机舱”列中包含值缺失。
有两种方法可以处理缺失值:
- 删除缺少值的行
- 估算缺失值
我更喜欢后者, 因为如果删除具有缺失值的行, 可能会导致数据不足, 进而导致机器学习模型的训练效率低下。
现在, 有几种方法可以执行插补:
- 在域中具有含义的常数值, 例如0, 不同于所有其他值。
- 来自另一个随机选择的记录的值。
- 列的平均值, 中位数或众数值。
- 由另一个机器学习模型估计的值。
当需要根据最终机器学习模型进行预测时, 将来必须在测试数据上执行在火车集合上执行的所有估算。选择如何估算缺失值时, 必须考虑到这一点。
Pandas提供fillna()函数, 用于用特定值替换缺失值。让我们将其应用于均值插补。
# Fill missing values with mean column values in the train set
train.fillna(train.mean(), inplace=True)
# Fill missing values with mean column values in the test set
test.fillna(test.mean(), inplace=True)
现在你已经估算出数据集中的缺失值, 现在该看看数据集是否仍然存在任何缺失值。
对于训练数据集:
print(train.isna().sum())
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
让我们看看测试集中是否有任何缺失的值。
print(test.isna().sum())
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64
是的, 你可以看到”机舱”和”登机”列中仍有一些缺失值。这是因为这些值是非数字的。为了执行插补, 值必须为数字形式。有多种方法可以将非数字值转换为数字值。稍后再详细介绍。
让我们做更多的分析, 以便更好地理解数据。真正需要了解才能执行任何机器学习任务。让我们开始找出哪些特征是分类特征, 哪些是数字特征。
- 分类:幸存, 性和上船。顺序:Pclass。
- 连续:年龄, 票价。离散:SibSp, Parch。
遗漏了以上两个类别中未列出的两个功能。是的, 你猜对了, 票务和机舱。票证是数字和字母数字数据类型的混合。机舱为字母数字。让我们看一些样本值。
train['Ticket'].head()
0 A/5 21171
1 PC 17599
2 STON/O2. 3101282
3 113803
4 373450
Name: Ticket, dtype: object
train['Cabin'].head()
0 NaN
1 C85
2 NaN
3 C123
4 NaN
Name: Cabin, dtype: object
让我们来看看乘客在以下方面的生存率:
- P类
- 性别
- 锡卜
- 版本号
让我们一个接一个地做:
关于Pclass的生存计数:
train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| P类 | 幸存下来 | |
|---|---|---|
| 0 | 1 | 0.629630 |
| 1 | 2 | 0.472826 |
| 2 | 3 | 0.242363 |
关于性别的生存期:
train[["Sex", "Survived"]].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| 性别 | 幸存下来 | |
|---|---|---|
| 0 | 女 | 0.742038 |
| 1 | 男 | 0.188908 |
你可以看到, 女性乘客的存活率明显高于男性。
关于SibSp的生存计数:
train[["SibSp", "Survived"]].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| 锡卜 | 幸存下来 | |
|---|---|---|
| 1 | 1 | 0.535885 |
| 2 | 2 | 0.464286 |
| 0 | 0 | 0.345395 |
| 3 | 3 | 0.250000 |
| 4 | 4 | 0.166667 |
| 5 | 5 | 0.000000 |
| 6 | 8 | 0.000000 |
现在该进行一些快速绘图了。让我们首先绘制”年龄与生存”的关系图:
g = sns.FacetGrid(train, col='Survived')
g.map(plt.hist, 'Age', bins=20)
<seaborn.axisgrid.FacetGrid at 0x7fa990f87080>

是时候用图表来了解Pclass和Survived功能之间的关系了:
grid = sns.FacetGrid(train, col='Survived', row='Pclass', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend();

到目前为止, 足够的可视化和分析功能!让我们用训练集实际构建一个K-Means模型。但是在此之前, 你还需要进行一些数据预处理。你可以看到并非所有要素值都属于同一类型。其中有些是数字的, 有些则不是。为了简化计算, 你将所有数值数据输入模型。让我们看看你拥有的不同功能的数据类型:
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
因此, 你可以看到以下功能部件是非数字的:
- 名称
- 性别
- 票
- 舱
- 出发
在将它们转换为数字形式之前, 你可能需要进行一些要素工程设计, 即, 姓名, 票务, 客舱和登机等要素不会对乘客的生存状态产生任何影响。通常, 只使用重要功能训练模型比使用所有功能(包括不必要的功能)训练模型更好。它不仅有助于高效建模, 而且模型的训练也可以在更短的时间内完成。尽管特征工程本身就是整个研究领域, 但我还是鼓励你进一步研究它。但是对于本教程而言, 请知道可以删除名称, 票证, 客舱和登机功能, 并且它们对K-Means模型的训练不会产生重大影响。
train = train.drop(['Name', 'Ticket', 'Cabin', 'Embarked'], axis=1)
test = test.drop(['Name', 'Ticket', 'Cabin', 'Embarked'], axis=1)
现在完成删除部分, 让我们将”性别”特征转换为数字形式(现在仅保留”性别”, 这是非数字特征)。你将使用称为标签编码的技术来完成此操作。
labelEncoder = LabelEncoder()
labelEncoder.fit(train['Sex'])
labelEncoder.fit(test['Sex'])
train['Sex'] = labelEncoder.transform(train['Sex'])
test['Sex'] = labelEncoder.transform(test['Sex'])
# Let's investigate if you have non-numeric data left
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 8 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Sex 891 non-null int64
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Fare 891 non-null float64
dtypes: float64(2), int64(6)
memory usage: 55.8 KB
请注意, 测试集不具有”幸存”功能。
test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 7 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Sex 418 non-null int64
Age 418 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Fare 418 non-null float64
dtypes: float64(2), int64(5)
memory usage: 22.9 KB
辉煌!
看来你现在就去训练K-Means模型很好。
你可以先使用drop()函数从数据中删除”生存”列。
X = np.array(train.drop(['Survived'], 1).astype(float))
y = np.array(train['Survived'])
你可以使用train.info()查看要提供给算法的所有功能。
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 7 columns):
PassengerId 891 non-null int64
Pclass 891 non-null int64
Sex 891 non-null int64
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Fare 891 non-null float64
dtypes: float64(2), int64(5)
memory usage: 48.8 KB
现在让我们建立K-Means模型。
kmeans = KMeans(n_clusters=2) # You want cluster the passenger records into 2: Survived or Not survived
kmeans.fit(X)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300, n_clusters=2, n_init=10, n_jobs=1, precompute_distances='auto', random_state=None, tol=0.0001, verbose=0)
你可以查看模型中除n_clusters之外的所有其他参数。通过查看正确聚类的乘客记录的百分比, 看看模型的运行情况如何。
correct = 0
for i in range(len(X)):
predict_me = np.array(X[i].astype(float))
predict_me = predict_me.reshape(-1, len(predict_me))
prediction = kmeans.predict(predict_me)
if prediction[0] == y[i]:
correct += 1
print(correct/len(X))
0.5084175084175084
第一次去那很好。你的模型能够以50%(模型的准确性)正确地聚类。但是, 为了增强模型的性能, 你可以调整模型本身的一些参数。我将列出K-Means的scikit-learn实现提供的一些参数:
- 算法
- max_iter
- n_jobs
让我们调整这些参数的值, 看看结果是否有变化。
在scikit-learn文档中, 你将找到有关这些参数的可靠信息, 你应该对其进行进一步挖掘。
kmeans = kmeans = KMeans(n_clusters=2, max_iter=600, algorithm = 'auto')
kmeans.fit(X)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=600, n_clusters=2, n_init=10, n_jobs=1, precompute_distances='auto', random_state=None, tol=0.0001, verbose=0)
correct = 0
for i in range(len(X)):
predict_me = np.array(X[i].astype(float))
predict_me = predict_me.reshape(-1, len(predict_me))
prediction = kmeans.predict(predict_me)
if prediction[0] == y[i]:
correct += 1
print(correct/len(X))
0.49158249158249157
你会看到分数下降。原因之一是你没有缩放要馈送到模型的不同要素的值。数据集中的要素包含不同的值范围。因此, 发生的事情是某个功能的微小更改不会影响其他功能。因此, 将要素的值缩放到相同范围也很重要。
现在开始进行操作, 对于本实验, 你将采用0-1作为所有要素的统一值范围。
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
kmeans.fit(X_scaled)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=600, n_clusters=2, n_init=10, n_jobs=1, precompute_distances='auto', random_state=None, tol=0.0001, verbose=0)
correct = 0
for i in range(len(X)):
predict_me = np.array(X[i].astype(float))
predict_me = predict_me.reshape(-1, len(predict_me))
prediction = kmeans.predict(predict_me)
if prediction[0] == y[i]:
correct += 1
print(correct/len(X))
0.6262626262626263
大!你会看到分数立即增加了12%。
到目前为止, 你已经能够加载数据, 对其进行相应的预处理, 进行少量的特征工程, 最后你就可以制作一个K-Means模型并进行实际操作。
现在, 让我们讨论K-Means的局限性。
K-均值的缺点
现在你已经对K-Means算法的工作原理有了一个很好的了解, 让我们讨论一下它的一些缺点。
最大的缺点是, K-Means要求你预先指定群集数(k)。但是, 对于泰坦尼克号数据集, 你拥有一些可用的领域知识, 可以告诉你在沉船中幸存的人数。对于现实世界的数据集可能并非总是如此。分层集群是一种不需要特定选择集群的替代方法。 k均值的另一个缺点是, 它对异常值敏感, 如果更改数据的顺序, 则会出现不同的结果。
K-Means是一个懒惰的学习者, 训练数据的推广被延迟到对系统进行查询之前。这意味着K-Means仅在你触发它时才开始工作, 因此惰性学习方法可以针对每个遇到的查询为目标函数构造不同的近似值或结果。这是一种在线学习的好方法, 但是它可能需要大量的内存来存储数据, 并且每个请求都涉及从头开始识别本地模型。
总结
因此, 在本教程中, 你介绍了最流行的群集技术之一-K-Means的表面。你了解了它的内部机制, 并使用Python中的Titanic数据集实现了它, 并且对它的缺点也有了一个很好的认识。如果你想了解有关这些集群技术的更多信息, 强烈建议你查看我们的Python无监督学习课程。
评论前必须登录!
注册