 srcmini
srcmini本文概述
作为数据科学家, 你将必须分析数据集中要素的分布。通常, 这是通过使用直方图完成的, 这对于显示值的可变范围, 其偏差以及值集中的位置非常有用。
教程目标
在本教程中, 你将学习如何
- 使用ggplot创建和自定义直方图。
- 用MASS :: kde2d函数拟合双变量分布。
- 创建轮廓图。
- 生成热图。
本教程使用R。如果你还不熟悉R, 建议你参加免费的srcmini R入门课程。
自行车共享数据集
对于本教程, 你将使用kaggle竞赛中的Bike Sharing Demand数据集。
按照链接进入数据标签, 然后下载train.csv文件。

将数据集加载到R中。
library(dplyr)
bike<- read.csv("train.csv", na.strings = FALSE, strip.white = TRUE)
glimpse(bike)
数据集功能
| 特征 | 描述 |
|---|---|
| 约会时间 | 每小时日期+时间戳 |
| 季节 | 1 =春季2 =夏季3 =秋季4 =冬季 |
| 假日 | 那天是否被认为是假期 |
| 工作日 | 一天既不是周末也不是假期 |
| 天气 | 1:晴, 少云, 局部多云, 局部多云2:薄雾+多云, 薄雾+碎云, 薄雾+少量云, 薄雾3:小雪, 小雨+雷暴+零星云, 小雨+零星云4:重雨+冰板+雷暴+雾, 雪+雾 |
| 温度 | 摄氏温度 |
| 暂时的 | 摄氏温度的”感觉” |
| 湿度 | 相对湿度 |
| 风速 | 风速 |
| 随便的 | 发起的未注册用户租金的数量 |
| 注册 | 已启动的注册用户租金数量 |
| 计数 | 总租金数 |
功能选择
你将按季节分析温度和湿度之间的关系, 因此请从数据集中选择它们。记住要加载dplyr软件包。
bike_data<-
bike %>%
dplyr::select(season, atemp, humidity)
head(bike_data)
直方图
好了, 现在你可以开始分析数据了, 首先按季节为每个要素创建一个直方图。你将使用ggplot2库进行此操作, 因此不要忘记加载它。
湿度直方图
library(ggplot2)
bike_data %>%
ggplot( aes(x=humidity) ) +
geom_histogram(bins=30) +
facet_wrap(~season, ncol = 2)

使用直方图, 你可以看到冬季湿度较高(这很明显), 但是你可以了解每个季节的湿度分布情况。
现在添加密度, 密度地毯并更改构面名称, 只是为了获得更好的外观。
bike_data %>%
mutate(season_label = case_when(
season == 1 ~ "Spring", season == 2 ~ "Summer", season == 3 ~ "fall", season == 4 ~ "winter")) %>%
ggplot( aes(x=humidity) ) +
geom_histogram(bins=30, aes(y = ..density..)) +
geom_rug()+
geom_density()+
facet_wrap(~season_label, ncol = 2)+
ggtitle("Histogram of humidity by season")

现在, 这可以使你更好地了解湿度的行为, 在不带温度的情况下也是如此。
非临时直方图
重用上面的代码并将变量更改为atemp,
bike_data %>%
mutate(season_label = case_when(
season == 1 ~ "Spring", season == 2 ~ "Summer", season == 3 ~ "fall", season == 4 ~ "winter")) %>%
ggplot( aes(x=atemp) ) +
geom_histogram(bins=30, aes(y = ..density..)) +
geom_rug()+
geom_density()+
facet_wrap(~season_label, ncol = 2)+
ggtitle("Histogram of atemp by season")
按季节划分的无节直方图
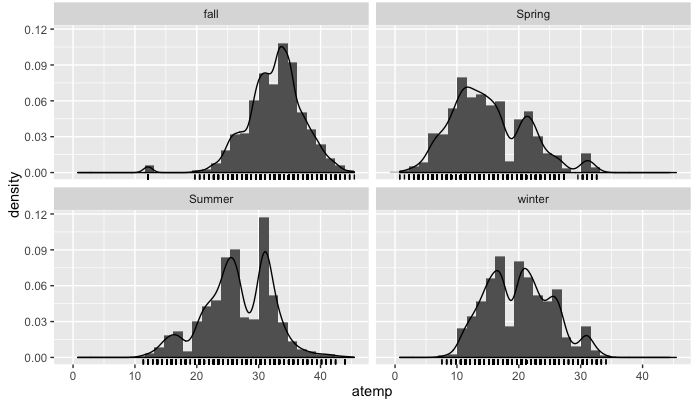
好的, 到目前为止, 一切都按照你对每个赛季的期望进行。在每个图中, 你都具有概率分布函数的近似值。
但是, 基于此图很难可视化要素之间的交互方式。遇到的第一个困难是直方图必须是3D的, 因为你正试图找到这两个特征的分布函数。
将双变量分布拟合到你的数据
目标是可视化双变量分布, 要做到这一点, 你首先需要将双变量分布拟合到数据。这将使用MASS库和kde2d函数完成。假设随机变量的正态性, 则kde2d函数将估算双变量分布。此功能的输入如下:
| 输入 | 描述 |
|---|---|
| X | x坐标数据 |
| 和 | y坐标数据 |
| ñ | 每个轴的网格点数 |
| lims | x和y的极限 |
现在将其应用于夏季的数据集过滤,
library(MASS)
bike_data_summer <- bike_data %>% filter(season==1)
bike_density <- kde2d(bike_data_summer$atemp, bike_data_summer$humidity, n=1000)
注意:加载MASS库时, 它带有一个select函数, 这与dplyr select函数有关, 因此要解决此问题, 使用dplyr select时, 你需要向其中添加dplyr ::, 例如dplyr :: select()它可以正常工作。
现在来看一下bike_density的类和结构
class(bike_density)
str(bike_density)
它是一个具有3个值x, y和z的列表。前两个具有特征值, 第三个是具有pdf值的矩阵。用轮廓函数看一下密度,
contour(bike_density)
text(12.2, 92, "1", cex=1.5)
points(12.2, 89, col="red", pch=18)
text(10.4, 47, "2", cex=1.5)
points(10.4, 43, col="red", pch=18)
text(21, 45, "3", cex=1.5)
points(21, 40, col="red", pch=18)
text(21.6, 82, "4", cex=1.5)
points(21.6, 78, col="red", pch=18)

查看此点, 你可以确定一些累积点, 这可以理解为这两个特征组合的最频繁值。下表中恢复了每个点的值,
| 点 | 温度(°C) | 谦卑(%) |
|---|---|---|
| 1 | 12.2 | 89 |
| 2 | 10.4 | 43 |
| 3 | 21 | 43 |
| 4 | 21.6 | 78 |
热图
要创建你的热图, 你首先需要定义要使用的色标, 你可以使用函数colorRampPalette进行操作
hm_col_scale<-colorRampPalette(c("black", "blue", "green", "orange", "red"))(1000)
hm_col_scale是使用RGB代码以1000步从黑色变为红色的向量。
现在, 使用图像函数绘制热图, 该函数用于绘制矩阵。
image(bike_density$z, col = hm_col_scale, zlim=c(min(bike_density$z), max(bike_density$z)))
text(0.31, 0.46, "Most Frequent", col="blue", cex=0.8)
points(0.31, 0.45, col="blue", pch=18)
现在, 你可以看到它比等高线图具有更多信息, 因为现在颜色告诉我们累积点的高度。你可以看到春季最频繁的湿度和非温度值在点$(10.4, 43)$附近
总结
现在你知道了如何创建热点图, 现在该轮到你自己创建了。首先查看其他季节以及与其他变量的关系。
考虑到最频繁的点具有较高的概率, 你将如何使用它来了解必须为变量的不同值提供多少辆自行车。
如果你想了解有关使用ggplot生成数据可视化的更多信息, 请务必查看我们的使用ggplot2进行数据可视化的课程。
评论前必须登录!
注册