 srcmini
srcmini本文概述
如果你在应用机器学习算法方面经验不足, 那么你会发现它不需要任何统计知识就可以。
但是, 了解一些统计信息对于从技术上和直观上理解机器学习都是有益的。当你想要开始验证结果并解释它们时, 最终将需要知道一些统计信息。毕竟, 当有数据时, 就有统计数据。就像数学一样, 科学也是语言。统计是数据科学和机器学习的一种语言。
统计学是数学领域, 具有许多理论和发现。但是, 从该领域可以采用各种概念, 工具, 技术和符号来使机器学习当今的情况。你可以使用描述性统计方法来帮助将观察结果转换为有用的信息, 你将能够理解这些信息并与他人共享。你可以使用推论统计技术来推理从少量数据样本到整个域。在本文的后面, 你将学习描述性和推论统计。所以, 不用担心。
在开始之前, 让我们看一下十个示例, 其中在应用的机器学习项目中使用统计方法:
- 问题框架:需要使用探索性数据分析和数据挖掘。
- 数据理解:需要使用摘要统计信息和数据可视化。
- 数据清理:需要使用离群值检测, 插补等功能。
- 数据选择:需要使用数据采样和特征选择方法。
- 数据准备:需要使用数据转换, 缩放, 编码等等。
- 模型评估:需要实验设计和重采样方法。
- 模型配置:需要使用统计假设检验和估计统计量。
- 模型选择:需要使用统计假设检验和估计统计量。
- 模型表示:需要使用估计统计信息, 例如置信区间。
- 模型预测:需要使用估计统计信息, 例如预测间隔。
资料来源:机器学习的统计方法
那不是很迷人吗?
这篇文章将为你成为一名优秀的机器学习从业人员提供必要但必要的统计数据的扎实背景。
在这篇文章中, 你将学习:
- 统计概论及其类型
- 数据准备统计
- 模型评估统计
- 高斯和描述性统计
- 变量相关
- 非参数统计
你要覆盖的内容很多, 所有主题都同样重要。让我们开始吧!
统计概论及其类型
让我们简要地研究如何用简单的术语定义统计信息。
统计被认为是数学的一个子领域。它涉及用于处理数据并使用该数据回答许多类型问题的多种方法。
在实践中使用统计工具时, 将统计领域划分为两大类方法可能会有所帮助:描述性统计用于汇总数据, 推理性统计用于得出数据样本(机器学习统计( 7天迷你课程))。
- 描述统计:描述统计用于描述研究中数据的基本特征。它们提供了有关样本和度量的简单摘要。它们与简单的图形分析一起, 构成了几乎所有数据定量分析的基础。下面的信息图很好地总结了描述性统计信息:

资料来源:IntellSpot
推论统计:推论统计是有助于从一组称为样本的观测数据中量化域或种群属性的方法。以下是一个图表, 精美描述了推论统计:
资料来源:Analytics Vidhya
在下一部分中, 你将研究使用统计数据进行数据准备。
数据准备统计
在为你的机器学习模型开发训练和测试数据时需要统计方法。
这包括用于以下方面的技术:
- 离群值检测
- 缺少价值估算
- 资料取样
- 数据缩放
- 可变编码
需要对数据分布, 描述性统计信息和数据可视化有基本的了解, 以帮助你确定执行这些任务时要选择的方法。
让我们简要分析以上各点。
离群值检测:
首先让我们看看什么是离群值。
离群值被认为是与样本中其他观察值有偏差的观察值。下图使定义更加突出。

资料来源:MathWorks
如上图所示, 你可以在数据中发现异常值。
许多机器学习算法对输入数据中属性值的范围和分布很敏感。输入数据中的异常值可能会歪曲和误导机器学习算法的训练过程, 从而导致训练时间更长, 模型精度较低, 最终结果更为平庸。
出于以下原因, 识别潜在异常值至关重要:
- 离群值可能表示数据不正确。例如, 数据可能编码不正确, 或者实验未正确运行。如果可以确定一个外围点实际上是错误的, 则应该从分析中删除该外围点的值。如果可以纠正, 那是另一种选择。
- 在某些情况下, 可能无法确定外围点是否为不良数据点。离群值可能是由于随机变化, 也可能表示某些科学有趣的现象。无论如何, 你通常不希望只删除外围的观测值。但是, 如果数据包含明显的异常值, 则可能需要考虑使用可靠的统计技术。
因此, 离群值通常不利于你的预测模型(尽管有时可以将这些离群值用作优势。但这超出了本文的范围)。你需要统计知识来有效处理离群值。
缺少价值估算:
好吧, 现在大多数数据集都存在缺少值的问题。如果你要馈送到模型的数据包含缺失值, 则可能无法有效地训练机器学习模型。统计工具和技术来这里进行救援。
许多人倾向于丢弃包含缺失值的数据实例。但这不是一个好习惯, 因为在此过程中, 你可能会丢失数据的基本功能/表示形式。尽管有用于解决价值缺失问题的高级方法, 但这些方法是人们会追求的快速技术:均值插补和中值插补。
你必须了解均值和中位数。
假设你有一个要素X1, 它具有以下值-13, 18, 13, 14, 13, 13, 16, 14, 21, 13
平均值是通常的平均值, 因此我将相加然后除以:
(13 + 18 + 13 + 14 + 13 + 16 + 14 + 21 + 13) / 9 = 15
请注意, 在这种情况下, 平均值不是原始列表中的值。这是普遍的结果。你不应假设你的均值将是原始数字之一。
中位数是中间值, 因此首先, 你必须按数字顺序重写列表:
13, 13, 13, 13, 14, 14, 16, 18, 21
列表中有九个数字, 因此中间的一个将是(9 +1)/ 2 = 10/2 =第五个数字:
13, 13, 13, 13, 14, 14, 16, 18, 21
因此中位数为14。
数据采样:
数据被认为是应用机器学习的货币。因此, 它的收集和使用同等重要。
数据采样是指统计方法, 用于从域中选择观测值, 以估计总体参数。换句话说, 抽样是一个收集观测数据的活跃过程, 目的是估计总体变量。
数据集的每一行代表一个表示特定种群的观察值。使用数据时, 通常无法访问所有可能的观察结果。原因可能有很多, 例如:
- 进行更多观察可能很困难或昂贵。
- 将所有观察结果收集在一起可能是一个挑战。
- 预计将来会进行更多观察。
很多时候, 你将没有正确比例的数据样本。因此, 你将不得不根据问题的类型进行欠采样或过采样。
当特定类别的数据样本与其他类别相比非常高时, 你将执行欠采样, 这意味着你从类别较高的数据样本中丢弃了一些数据样本。当特定类型的数据样本明显低于其他样本时, 你将执行过采样。在这种情况下, 你将生成数据样本。
这也适用于多类方案。
统计采样是一个广泛的研究领域, 但是在应用机器学习中, 可能会使用三种类型的采样:简单随机采样, 系统采样和分层采样。
- 简单随机抽样:从域中以均匀的概率抽取样本。
- 系统采样:使用预先指定的图案(例如, 以一定间隔)抽取样品。
- 分层抽样:在预先指定的类别(即分层)中抽取样本。
尽管这些是你可能会遇到的更常见的采样类型, 但是还有其他技术(《统计采样和重新采样的温和介绍》)。
数据缩放
通常, 数据集的特征可能会在范围上大相径庭。某些要素的比例可能为0到100, 而其他要素的范围可能为0.01-0.001、10000-20000等。
这对于有效建模是非常成问题的。因为该要素的较小变化(其值范围比其他要素低)可能不会对那些其他要素产生重大影响。它影响良好学习的过程。处理此问题称为数据缩放。
有不同的数据缩放技术, 例如最小-最大缩放, 绝对缩放, 标准缩放等。
变量编码:
有时, 你的数据集包含数字和非数字数据的混合。像scikit-learn这样的许多机器学习框架都希望所有数据以所有数字格式显示。这也有助于加快计算过程。
同样, 统计数据是为你省钱。
标签编码, 一键编码等技术可用于将非数字数据转换为数字。
现在是时候应用这些技术了!
你现在已经涵盖了很多理论。你将应用其中的一些以获得真实的感觉。
你将首先应用一些统计方法来检测离群值。
你将使用Z-Score指数来检测离群值, 为此, 你将调查Boston House Price数据集。让我们从sklearn的实用程序中导入数据集开始, 然后逐步开始必要的概念。
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston
# Load the Boston dataset into a variable called boston
boston = load_boston()
# Separate the features from the target
x = boston.data
y = boston.target
要以标准表格格式查看具有所有要素名称的数据集, 请将其转换为pandas数据框。
# Take the columns separately in a variable
columns = boston.feature_names
# Create the dataframe
boston_df = pd.DataFrame(boston.data)
boston_df.columns = columns
boston_df.head()
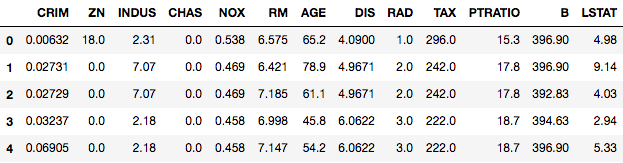
从单变量离群分析开始的一种常见做法是, 你一次只考虑一个功能。通常, 使用简单的特定功能箱形图可以为你提供良好的起点。你将使用seaborn绘制箱形图, 并使用DIS功能。
import seaborn as sns
sns.boxplot(x=boston_df['DIS'])
import matplotlib.pyplot as plt
plt.show()
<matplotlib.axes._subplots.AxesSubplot at 0x8abded0>

要查看箱线图, 你已经进行了第二次matplotlib的导入, 因为显示的seaborn图与普通的matplotlib图一样。
上图显示了10点到12点之间的三个点, 这些点是异常值, 因为它们未包含在其他观察值框中。在这里你分析了单变量离群值, 即你仅使用DIS功能来检查离群值。
现在让我们继续Z-Score。
” Z分数是标准偏差的有符号数, 通过该标准偏差, 观察值或数据点的值高于所观察或测量的平均值。” -维基百科
Z分数背后的想法是描述有关数据与该组数据点的标准偏差和均值之间关系的任何数据点。 Z分数用于查找平均值为0且标准偏差为1的数据分布, 即正态分布。
等待!这到底如何帮助识别异常值?
好了, 在计算Z分数时, 你可以重新缩放和居中数据(平均值为0, 标准偏差为1), 并查找距离零太远的实例。这些距离零太远的数据点被视为离群值。在大多数情况下, 使用3或-3阈值。例如, 说Z分数分别大于或小于3或-3。然后, 该数据点将被识别为异常值。
你将使用scipy库中定义的Z分数功能检测异常值。
from scipy import stats
z = np.abs(stats.zscore(boston_df))
print(z)
[[0.41771335 0.28482986 1.2879095 ... 1.45900038 0.44105193 1.0755623 ]
[0.41526932 0.48772236 0.59338101 ... 0.30309415 0.44105193 0.49243937]
[0.41527165 0.48772236 0.59338101 ... 0.30309415 0.39642699 1.2087274 ]
...
[0.41137448 0.48772236 0.11573841 ... 1.17646583 0.44105193 0.98304761]
[0.40568883 0.48772236 0.11573841 ... 1.17646583 0.4032249 0.86530163]
[0.41292893 0.48772236 0.11573841 ... 1.17646583 0.44105193 0.66905833]]
仅查看上面的输出是不可能检测到异常值的。你更聪明!你将为自己定义阈值, 并使用简单条件来检测超出阈值的异常值。
threshold = 3
print(np.where(z > 3))
(array([ 55, 56, 57, 102, 141, 142, 152, 154, 155, 160, 162, 163, 199, 200, 201, 202, 203, 204, 208, 209, 210, 211, 212, 216, 218, 219, 220, 221, 222, 225, 234, 236, 256, 257, 262, 269, 273, 274, 276, 277, 282, 283, 283, 284, 347, 351, 352, 353, 353, 354, 355, 356, 357, 358, 363, 364, 364, 365, 367, 369, 370, 372, 373, 374, 374, 380, 398, 404, 405, 406, 410, 410, 411, 412, 412, 414, 414, 415, 416, 418, 418, 419, 423, 424, 425, 426, 427, 427, 429, 431, 436, 437, 438, 445, 450, 454, 455, 456, 457, 466], dtype=int32), array([ 1, 1, 1, 11, 12, 3, 3, 3, 3, 3, 3, 3, 1, 1, 1, 1, 1, 1, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 5, 3, 3, 1, 5, 5, 3, 3, 3, 3, 3, 3, 1, 3, 1, 1, 7, 7, 1, 7, 7, 7, 3, 3, 3, 3, 3, 5, 5, 5, 3, 3, 3, 12, 5, 12, 0, 0, 0, 0, 5, 0, 11, 11, 11, 12, 0, 12, 11, 11, 0, 11, 11, 11, 11, 11, 11, 0, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11], dtype=int32))
再次, 令人困惑的输出!第一个数组包含行号列表, 第二个数组包含其各自的列号。例如, z [55] [1]的Z分数高于3。
print(z[55][1])
3.375038763517309
因此, 列ZN上的第55条记录是一个异常值。你可以从这里扩展内容。
你了解了如何使用Z-Score并设置其阈值以检测数据中的潜在异常值。接下来, 你将看到如何进行一些缺失值的估算。
你将使用著名的Pima印度糖尿病数据集, 该数据集已知值缺失。但是在继续进行之前, 你将必须将数据集加载到工作空间中。
你将数据集加载到DataFrame对象数据中。
data = pd.read_csv("https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv", header=None)
print(data.describe())
0 1 2 3 4 5 \
count 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000
mean 3.845052 120.894531 69.105469 20.536458 79.799479 31.992578
std 3.369578 31.972618 19.355807 15.952218 115.244002 7.884160
min 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000 27.300000
50% 3.000000 117.000000 72.000000 23.000000 30.500000 32.000000
75% 6.000000 140.250000 80.000000 32.000000 127.250000 36.600000
max 17.000000 199.000000 122.000000 99.000000 846.000000 67.100000
6 7 8
count 768.000000 768.000000 768.000000
mean 0.471876 33.240885 0.348958
std 0.331329 11.760232 0.476951
min 0.078000 21.000000 0.000000
25% 0.243750 24.000000 0.000000
50% 0.372500 29.000000 0.000000
75% 0.626250 41.000000 1.000000
max 2.420000 81.000000 1.000000
你可能已经注意到, 此处的列名是数字。这是因为你使用的是已经预处理的数据集。但请放心, 你很快就会发现这些名称。
现在, 已知该数据集具有缺失值, 但是乍一看上述统计数据, 似乎该数据集根本不包含缺失值。但是, 如果仔细研究, 你会发现有些列中的零值完全无效。这些是缺少的值。
具体来说, 以下各列的无效零值为最小值:
- 血浆葡萄糖浓度
- 舒张压
- 三头肌皮褶厚度
- 2小时血清胰岛素
- 体重指数
让我们通过查看原始数据来确认这一点, 该示例将打印前20行数据。
data.head(20)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
| 5 | 5 | 116 | 74 | 0 | 0 | 25.6 | 0.201 | 30 | 0 |
| 6 | 3 | 78 | 50 | 32 | 88 | 31.0 | 0.248 | 26 | 1 |
| 7 | 10 | 115 | 0 | 0 | 0 | 35.3 | 0.134 | 29 | 0 |
| 8 | 2 | 197 | 70 | 45 | 543 | 30.5 | 0.158 | 53 | 1 |
| 9 | 8 | 125 | 96 | 0 | 0 | 0.0 | 0.232 | 54 | 1 |
| 10 | 4 | 110 | 92 | 0 | 0 | 37.6 | 0.191 | 30 | 0 |
| 11 | 10 | 168 | 74 | 0 | 0 | 38.0 | 0.537 | 34 | 1 |
| 12 | 10 | 139 | 80 | 0 | 0 | 27.1 | 1.441 | 57 | 0 |
| 13 | 1 | 189 | 60 | 23 | 846 | 30.1 | 0.398 | 59 | 1 |
| 14 | 5 | 166 | 72 | 19 | 175 | 25.8 | 0.587 | 51 | 1 |
| 15 | 7 | 100 | 0 | 0 | 0 | 30.0 | 0.484 | 32 | 1 |
| 16 | 0 | 118 | 84 | 47 | 230 | 45.8 | 0.551 | 31 | 1 |
| 17 | 7 | 107 | 74 | 0 | 0 | 29.6 | 0.254 | 31 | 1 |
| 18 | 1 | 103 | 30 | 38 | 83 | 43.3 | 0.183 | 33 | 0 |
| 19 | 1 | 115 | 70 | 30 | 96 | 34.6 | 0.529 | 32 | 1 |
显然, 第2、3、4和5列中有0个值。
由于此数据集的缺失值表示为0, 因此仅使用常规方法来处理它可能会比较棘手。让我们总结一下你将采用的解决方法:
- 获取你先前看到的每个列中的零计数。
- 确定上一步骤中哪些列的零值最多。
- 用NaN替换这些列中的零值。
- 检查NaN是否得到适当反映。
- 使用插补策略调用fillna()函数。
# Step 1: Get the count of zeros in each of the columns
print((data[[1, 2, 3, 4, 5]] == 0).sum())
1 5
2 35
3 227
4 374
5 11
dtype: int64
你可以看到第1, 2和5列只有几个零值, 而第3和第4列则显示了更多的值, 几乎占行的一半。
# Step -2: Mark zero values as missing or NaN
data[[1, 2, 3, 4, 5]] = data[[1, 2, 3, 4, 5]].replace(0, np.NaN)
# Count the number of NaN values in each column
print(data.isnull().sum())
0 0
1 5
2 35
3 227
4 374
5 11
6 0
7 0
8 0
dtype: int64
现在, 通过查看整个数据集, 可以确保你的NaN替代品大获成功:
# Step 4
data.head(20)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148.0 | 72.0 | 35.0 | NaN | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85.0 | 66.0 | 29.0 | NaN | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183.0 | 64.0 | NaN | NaN | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89.0 | 66.0 | 23.0 | 94.0 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137.0 | 40.0 | 35.0 | 168.0 | 43.1 | 2.288 | 33 | 1 |
| 5 | 5 | 116.0 | 74.0 | NaN | NaN | 25.6 | 0.201 | 30 | 0 |
| 6 | 3 | 78.0 | 50.0 | 32.0 | 88.0 | 31.0 | 0.248 | 26 | 1 |
| 7 | 10 | 115.0 | NaN | NaN | NaN | 35.3 | 0.134 | 29 | 0 |
| 8 | 2 | 197.0 | 70.0 | 45.0 | 543.0 | 30.5 | 0.158 | 53 | 1 |
| 9 | 8 | 125.0 | 96.0 | NaN | NaN | NaN | 0.232 | 54 | 1 |
| 10 | 4 | 110.0 | 92.0 | NaN | NaN | 37.6 | 0.191 | 30 | 0 |
| 11 | 10 | 168.0 | 74.0 | NaN | NaN | 38.0 | 0.537 | 34 | 1 |
| 12 | 10 | 139.0 | 80.0 | NaN | NaN | 27.1 | 1.441 | 57 | 0 |
| 13 | 1 | 189.0 | 60.0 | 23.0 | 846.0 | 30.1 | 0.398 | 59 | 1 |
| 14 | 5 | 166.0 | 72.0 | 19.0 | 175.0 | 25.8 | 0.587 | 51 | 1 |
| 15 | 7 | 100.0 | NaN | NaN | NaN | 30.0 | 0.484 | 32 | 1 |
| 16 | 0 | 118.0 | 84.0 | 47.0 | 230.0 | 45.8 | 0.551 | 31 | 1 |
| 17 | 7 | 107.0 | 74.0 | NaN | NaN | 29.6 | 0.254 | 31 | 1 |
| 18 | 1 | 103.0 | 30.0 | 38.0 | 83.0 | 43.3 | 0.183 | 33 | 0 |
| 19 | 1 | 115.0 | 70.0 | 30.0 | 96.0 | 34.6 | 0.529 | 32 | 1 |
你可以看到标记缺失值具有预期的效果。
到目前为止, 你已经分析了数据丢失时的基本趋势, 以及如何利用简单的统计手段来掌握数据。现在, 你将使用均值插补来插补缺失值, 这实际上是插补各个列的平均值来代替缺失值。
# Step 5: Call the fillna() function with the imputation strategy
data.fillna(data.mean(), inplace=True)
# Count the number of NaN values in each column to verify
print(data.isnull().sum())
0 0
1 0
2 0
3 0
4 0
5 0
6 0
7 0
8 0
dtype: int64
优秀的!
这篇srcmini文章有效地指导你实现数据缩放作为数据预处理步骤。请务必检查一下。
接下来, 你将进行变量编码。
在此之前, 你需要一个实际上包含非数字数据的数据集。你将为此使用著名的Iris数据集。
# Load the dataset to a DataFrame object iris
iris = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data", header=None)
# See first 20 rows of the dataset
iris.head(20)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 虹膜柔滑 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 虹膜柔滑 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 虹膜柔滑 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 虹膜柔滑 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 虹膜柔滑 |
| 5 | 5.4 | 3.9 | 1.7 | 0.4 | 虹膜柔滑 |
| 6 | 4.6 | 3.4 | 1.4 | 0.3 | 虹膜柔滑 |
| 7 | 5.0 | 3.4 | 1.5 | 0.2 | 虹膜柔滑 |
| 8 | 4.4 | 2.9 | 1.4 | 0.2 | 虹膜柔滑 |
| 9 | 4.9 | 3.1 | 1.5 | 0.1 | 虹膜柔滑 |
| 10 | 5.4 | 3.7 | 1.5 | 0.2 | 虹膜柔滑 |
| 11 | 4.8 | 3.4 | 1.6 | 0.2 | 虹膜柔滑 |
| 12 | 4.8 | 3.0 | 1.4 | 0.1 | 虹膜柔滑 |
| 13 | 4.3 | 3.0 | 1.1 | 0.1 | 虹膜柔滑 |
| 14 | 5.8 | 4.0 | 1.2 | 0.2 | 虹膜柔滑 |
| 15 | 5.7 | 4.4 | 1.5 | 0.4 | 虹膜柔滑 |
| 16 | 5.4 | 3.9 | 1.3 | 0.4 | 虹膜柔滑 |
| 17 | 5.1 | 3.5 | 1.4 | 0.3 | 虹膜柔滑 |
| 18 | 5.7 | 3.8 | 1.7 | 0.3 | 虹膜柔滑 |
| 19 | 5.1 | 3.8 | 1.5 | 0.3 | 虹膜柔滑 |
你可以使用LabelEncoder轻松地将字符串值转换为整数值。三个类别值(鸢尾花, 鸢尾花, 鸢尾)被映射到整数值(0、1、2)。
在这种情况下, 数据集的第四列/功能包含非数字值。因此, 你需要将其分开。
# Convert the DataFrame to a NumPy array
iris = iris.values
# Separate
Y = iris[:, 4]
# Label Encode string class values as integers
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
label_encoder = label_encoder.fit(Y)
label_encoded_y = label_encoder.transform(Y)
现在, 让我们研究另一个需要统计学基础知识的领域。
模型评估统计
你已经设计并开发了机器学习模型。现在, 你想根据测试数据评估模型的性能。在这方面, 你寻求各种统计指标的帮助, 例如精度, 召回率, ROC, AUC, RMSE等。你还从多种数据重采样技术(例如k倍交叉验证)中寻求帮助。
统计信息可以有效地用于:
- 估计假设的准确性
- 确定两个假设的误差
- 使用McNemar的测试比较学习算法
重要的是要注意, 假设是指学习的模型。在数据集上运行学习算法的结果。评估和比较假设意味着比较学习的模型, 这不同于评估和比较机器学习算法, 机器学习算法可以针对来自同一问题或各种问题的不同样本进行训练。
现在让我们研究高斯统计和描述统计。
高斯和描述性统计简介
数据样本不过是来自某个域或过程生成的所有潜在观测值的更广泛总体的快照。
有趣的是, 许多观测值符合称为正态分布, 或更正式地称为高斯分布的典型模式或分布。你可能会注意到这是钟形分布。下图表示高斯分布:

资料来源:HyperPhysics
高斯过程和高斯分布本身就是另一个子领域。但是, 你现在将学习构成整个高斯分布世界的两个最基本要素。
从高斯分布中获取的任何样本数据都可以用两个参数来汇总:
- 均值:分布中的中心趋势或最可能的值(钟形顶部)。
- 方差:观测值与分布平均值之间的平均差异(价差)。
术语方差还引起另一个关键术语, 即标准偏差, 其仅是方差的平方根。
可以使用numpy从数据样本直接计算平均值, 方差和标准偏差。
首先, 你将从高斯分布中提取100个随机数的样本, 其均值为50, 标准差为5。然后, 你将计算汇总统计信息。
首先, 你将导入所有依赖项。
# Dependencies
from numpy.random import seed
from numpy.random import randn
from numpy import mean
from numpy import var
from numpy import std
接下来, 设置随机数生成器种子, 以使结果可重复。
seed(1)
# Generate univariate observations
data = 5 * randn(10000) + 50
# Calculate statistics
print('Mean: %.3f' % mean(data))
print('Variance: %.3f' % var(data))
print('Standard Deviation: %.3f' % std(data))
Mean: 50.049
Variance: 24.939
Standard Deviation: 4.994
足够接近了, 是吗?
现在让我们研究下一个主题。
变量相关
通常, 数据集中包含的要素通常可以相互关联, 这在实践中非常明显。用统计术语来说, 数据集要素之间的这种关系(简单或复杂)通常称为相关性。
找出数据集中要素的相关程度至关重要。从本质上讲, 此步骤用作要素选择, 涉及从数据集中选择最重要的要素。这一步是标准机器学习管道中最重要的步骤之一, 因为它可以在短时间内显着提高准确性。
为了更好地理解并使之更加实用, 让我们了解为什么功能可以相互关联:
- 一个功能可以决定另一个功能
- 一个功能可能在某种程度上与另一个功能相关联
- 多个功能可以组合并诞生另一个功能
特征之间的相关性可以分为三种类型:-正相关, 其中两个特征均沿同一方向变化;中性相关, 其中两个特征均无变化时;负相关, 其中两个特征均沿相反方向变化。
相关性测量形成了基于滤波器的特征选择技术的基础。如果你想学习更多有关功能选择的信息, 请查阅本文。
你可以使用称为Pearson相关系数的统计方法, 以数学上两个变量的样本之间的关系, 该方法以该方法的开发者Karl Pearson的名字命名。
你可以使用方法参数为pearson的pandas的corr()函数来计算Pearson的相关评分。让我们研究你之前使用的Pima Indians Diabetes数据集的特征之间的相关性。你已经拥有了良好的数据。
# Data
data.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148.0 | 72.0 | 35.00000 | 155.548223 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85.0 | 66.0 | 29.00000 | 155.548223 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183.0 | 64.0 | 29.15342 | 155.548223 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89.0 | 66.0 | 23.00000 | 94.000000 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137.0 | 40.0 | 35.00000 | 168.000000 | 43.1 | 2.288 | 33 | 1 |
# Create the matrix of correlation score between the features and the label
scoreTable = data.corr(method='pearson')
# Visulaize the matrix
data.corr(method='pearson').style.format("{:.2}").background_gradient(cmap=plt.get_cmap('coolwarm'), axis=1)
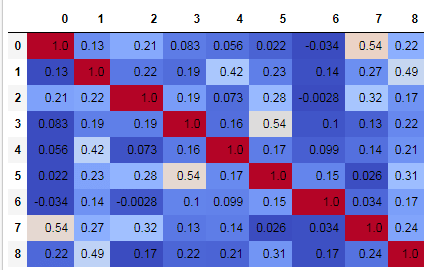
你可以清楚地看到所有要素与数据集标签之间的Pearson相关性。
在下一节中, 你将研究非参数统计。
非参数统计
统计和统计方法领域的很大一部分专用于已知分布的数据。
当没有或很少有关种群参数的信息时, 非参数统计将派上用场。非参数测试不对数据分布做任何假设。
在使用非参数数据的情况下, 可以使用专门的非参数统计方法, 该方法会丢弃有关分布的所有信息。因此, 这些方法通常称为无分布方法。
在应用非参数统计方法之前, 必须将数据转换为等级格式。期望以等级格式的数据的统计方法有时称为等级统计。等级统计的示例可以是等级相关和等级统计假设检验。排名数据正是顾名思义。
Mann-Whitney U检验是一种广泛用于检验两个独立样本之间差异的非参数统计假设检验, 以亨利·曼恩和唐纳德·惠特尼命名。
你将通过SciPy提供的mannwhitneyu()在Python中实现此测试。
# The dependencies that you need
from scipy.stats import mannwhitneyu
from numpy.random import rand
# seed the random number generator
seed(1)
# Generate two independent samples
data1 = 50 + (rand(100) * 10)
data2 = 51 + (rand(100) * 10)
# Compare samples
stat, p = mannwhitneyu(data1, data2)
print('Statistics = %.3f, p = %.3f' % (stat, p))
# Interpret
alpha = 0.05
if p > alpha:
print('Same distribution (fail to reject H0)')
else:
print('Different distribution (reject H0)')
Statistics = 4077.000, p = 0.012
Different distribution (reject H0)
alpha是由你确定的阈值参数。 mannwhitneyu()返回两件事:
- 统计信息:Mann-Whitney U统计信息, 如果Alternative等于None(不推荐使用;为向后兼容而存在), 则等于min(U表示x, U表示y), 否则等于U。
- pvalue:假定渐近正态分布的p值。
如果要研究非参数统计的其他方法, 则可以从此处开始。
你可以使用的另外两个流行的非参数统计显着性检验是:
- 弗里德曼检验
- Wilcoxon秩检验
这需要总结!
你终于做到了。在本文中, 你研究了各种基本的统计概念, 这些概念在你的机器学习项目中起着至关重要的作用。因此, 了解它们非常重要。
从仅仅是介绍到统计, 你还可以通过几种实现将其带到统计排名。这绝对是一个壮举。你研究了三个不同的数据集, 充分利用了熊猫和numpy的功能, 而且还使用了SciPy。如果你想进一步了解这些内容, 那么下面是一些链接:
- 统计学习的要素
- 汤姆·米切尔的机器学习书
- 全部用于统计
以下是我从帮助中撰写此博客的资源:
- 机器学习精通统计学迷你课程
- 统计采样和重采样的简要介绍
- https://www.khanacademy.org/math/statistics-probability
- 斯坦福大学统计学习课程
在评论部分让我知道你的意见/查询。另外, 请查阅srcmini的” Python中的统计思维”课程, 该课程非常实用。
评论前必须登录!
注册