 srcmini
srcmini本文概述
作为数据科学家, 你通常必须处理大量数据。处理数据(大量存在)并不容易。因此, 要尽可能高效地处理数据, 你需要对数据的物理组织方式有一个清晰的了解, 以便可以使用便捷的技术对其进行处理。
SQL是任何现代软件工程师必备的技能, 因为大多数软件都依赖某种数据, 并且与RDBMS(关系数据库管理系统)很好地集成在一起。无论是Web应用程序, API还是内部应用程序, RDBMS始终存在。 SQL是查询RDBMS的语言。
作为数据科学家, 了解SQL及其相关技术至关重要。为了能够查询RDBMS并获得有关要处理的数据的特定问题的答案, SQL是最低要求。
在与srcmini合作的最新视频中, David Robinson(首席数据科学家@ srcmini)向我们展示了他如何在数据科学问题中使用SQL。请检查一下。他的工作流程非常有趣。
今天, 你将学习一种称为索引的技术, 该技术主要涉及数据库内部数据的组织, 并且你将使用SQL来实现其中的一些技术。这将为你提供有关如何使用索引将信息存储在数据库内部以及如何缩短执行时间的概述。
以下将是本教程的概述:
- 关于文件中记录组织的简要说明
- 为什么需要索引?
- 索引文件的结构
- 索引分类
- 每种类型的解剖
- SQL中的示例
N.B .:在开始阅读本教程之前, 强烈建议你学习SQL基础知识(如果你不熟悉SQL基础知识的话)。如果你想刷新SQL基础知识, srcmini的SQL for Data Science入门课程是一个很好的资源。
关于文件中记录组织的简要说明
在开始研究有关索引的任何内容之前, 必须了解文件中数据的物理组织方式。显然, 你不会涉及所有细节, 但是对组织有一个良好的概览将有助于你非常清楚地理解索引。让我们开始吧。
记录/数据的组织通常处理记录的存储方式, 组织大致可分为两种类型:
- 有序组织:文件中的所有记录都按某个搜索关键字值排序。通常并入二进制搜索以搜索在有序文件内部存在的任何数量。由于搜索时间复杂度保持在对数时间内, 因此这使搜索非常有效。但是插入文件变得昂贵的操作, 因为你可能必须重组整个文件以方便使用新项目。
- 无序组织:在这种类型的情况下, 记录会插入到文件中任何可用的位置, 通常到文件的末尾。由于此类型使用线性搜索, 因此搜索不如先前的变体有效, 但插入操作并不昂贵。
尽管你的文件组织有序, 但是如果文件的块大小和文件中每个记录的大小很大, 该怎么办?让我们在下一部分中对此进行探讨。
需要索引
你将通过学习使用索引以有效存储文件/信息的动机以及如何增强与这些文件/信息相关的其他操作的本章开始。
考虑你有一个表(关系), 该表由数据库中的多个记录组成。记录进一步分为1000个块。如图所示, 该组织如下所示:
从以上机构可以明显看出:
- 该顺序应用于记录的第一列(考虑到这是一个关系数据库系统, 在其中以表格形式组织数据)
- 将总数据划分为的块数-1000个块。
请记住, 每个记录也包含其他列, 但是对于此组织, 该顺序将应用于第一列, 并相应地划分块。现在, 如果你执行二进制搜索以搜索该组织或记录中的任何内容, 则总时间为-$ \ log_ {2} 1000 $, 等于10个时间单位。可以改善搜索时间吗?
当然可以
考虑到读书和没有索引页。你打开一个随机页面(或者在二元搜索的情况下, 你打开该书的中间页面), 并相应地左右旋转页面以转到所需的页面。这当然需要时间。是不是
但是, 如果书中包含索引页, 这无疑会使搜索更加有效。你可能仅通过查看索引就可以转到页面。你可以以相同的方式将索引应用于上述情况。
以下是如何在此处应用索引的摘要:
- 维护每个块的块指针以及用于先前组织的有序值。
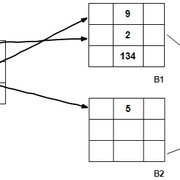
这将减少用于存储数据文件的块数。现在, 为了搜索特定记录, 你只需要搜索由较少块组成的这个新组织, 最终你将在更少的时间内获得记录(如果有的话)。让我们想象一下这件事。考虑到导致8个块的新索引记录的数量, 你将获得如下所示的组织:
对于较少的块数, 搜索时间将大大减少。假设你要搜索记录90。在这种新的索引方案中, 你将首先必须定位其各自的块指针(在这种情况下为3), 然后使用此信息可以一次性查找原始数据记录。
因此, 在这种情况下, 搜索时间将为$ \ log_ {2} 8 + 1 $ = 4个时间单位, 与之前的时间单位相比, 这要短得多。
上面的示例向你介绍了执行索引的需求。以下是有关索引的一些注意事项:
- 只能使用一个字段对原始数据记录进行排序。然后可以相应地为字段条目建立索引。仅当你尝试使用该字段进行搜索时, 你才可以缩短搜索时间。 (非常重要)
- 索引也是有序的。
- 索引记录包含两个字段(索引文件的结构)-
- 原始文件的密钥
- 指向原始数据记录中可用键的块的指针
- 二进制搜索用于搜索索引。
- 要使用索引条目访问记录, 平均块访问次数需要-
$ \ log_ {2} B_i + 1 $, 其中$ B_i $是索引记录中的块数 - 可以在关系的任何字段(主键, 候选键, 非键)上创建索引。
现在, 根据原始数据记录的顺序以及要在索引文件中维护的记录数, 可以有许多索引方案。在下一部分中, 你将研究最受欢迎的内容。
不同的索引策略
- 密集索引:如果为每个搜索关键字值创建一个索引条目, 则它是密集索引。考虑以下图表以直观地理解这一点。
- 稀疏索引:如果仅为某些记录创建索引条目, 则它是稀疏索引。这是一个以图形方式描述的图表。
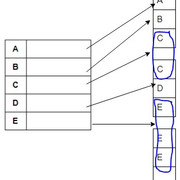
上图使两种索引方案都非常容易理解。你必须在此处提出的一个关键点是, 上面的稀疏索引示例是密集索引和稀疏索引的组合。这是因为对于每个唯一的搜索键值(1、2和3)都有一个索引, 但是对于每个数据记录, 都没有索引。
现在, 你将基于记录级别研究其他类型的索引方案。在单级索引中, 索引文件的数量只有一个。但是, 有时索引文件的大小太大, 以至于索引文件本身被索引了。在这种情况下, 它称为多级索引。让我们进一步研究。
这是基于平衡的其他索引策略的概述。
单级索引:
- 主索引
- 聚簇索引
- 二级索引
多级索引:
- B树
- B +树
你将研究属于单级索引的所有索引策略。在本教程的最后, 你将拥有一个链接, 以探索多级索引方案, 以备不时之需。现在让我们研究主索引。
主要索引:
主索引是有序文件, 其记录具有两个字段的固定长度:
- 第一个字段与数据文件的主键相同。
- 第二个字段是指向主键可用的数据块的指针。 – 资源
为每个块的第一条记录创建的索引称为块锚。在主索引中, 索引条目的数量=原始数据块的数量。使用主索引的平均块访问次数为:
$ \ log_ {2} B_i + 1 $, 其中$ B_i $是索引记录中的块数。
请参考下图, 以更清楚地了解这一点:
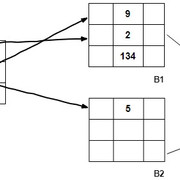
最右边的图是指分为几个块的原始数据记录。请注意, 包含数字1, 2, 3, …, 9的列是主键。最左边的数字是指索引条目, 其中每个条目包括:
- 每个数据块的第一个条目(块锚点)
- 第二项表示块指针。
花一点时间考虑一下这是什么类型的索引(稀疏或密集)。使用评论部分发布你的答案。
现在, 你将学习聚类索引。
聚类索引:
在数据文件上创建聚簇索引, 该文件的文件记录在非关键字段上物理排序, 该字段没有每个记录的不同值。该字段称为执行索引的聚类字段。因此, 名称-聚簇索引。
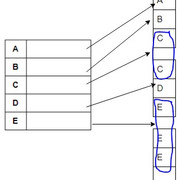
图总是使它更容易理解。如你所见, 原始数据记录是按非键属性排序的, 并且为非键属性的每个不同值创建了一个索引条目。使用此方案定位特定记录所需的平均块访问数为$ \ geq $ $ \ log_ {2} B_i + 1 $, 其中$ B_i $是索引记录中的块数。注意这里的$ \ geq $符号。
在聚簇索引中, 在找到存在特定键的块之后, 你也可以遍历其他块(从上图中可以明显看出)。
你可能想考虑这是什么类型的索引(稀疏或密集)。使用评论部分发布你的答案。让我们现在学习二级索引。
二级索引:
假设你的数据库中有一个名为Employee的表。该表具有以下属性:
- 员工ID
- 员工姓名
- employee_department
- 员工工资
employee_id是其主键。现在, 你已经基于employee_id在此表上创建了主索引。但是在开发应用程序时, 你发现大多数数据库查询都使用了employee_name属性。在这种情况下, 主要索引将无济于事, 并且对属于employee_name的所有值维护单独的索引将是一个好习惯。无论如何, 员工姓名都不会在数据库中以有序的方式出现。因此, 为它们建立索引无疑会加快涉及员工姓名的查询。
这是二级索引的经典示例。让我们尝试为二级索引构建合适的图像:
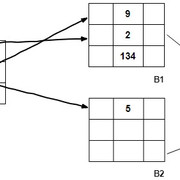
如果有的话, 请随时在评论部分中发布更好的表示。
现在, 你将看到如何在PostgreSQL中创建索引。如果你想了解srcmini的基础知识, 请参加PostgreSQL中的srcmini的Joining Data课程。
在PostgreSQL中创建索引
开始在PostgreSQL数据库中创建索引之前, 需要在表中存在一些数据。让我们创建一个名为Student的简单表, 该表由以下记录组成:
- 学生卡
- 学生姓名
- 学生年
你将student_id作为主键, 并且你将不允许学生姓名和学生年份为空。
以下将是对此的查询:
CREATE TABLE STUDENT(
student_id TEXT PRIMARY KEY, student_name TEXT NOT NULL, student_year TEXT NOT NULL
);
成功创建表后, 你将必须在表中插入一些合适的数据。为了方便起见, 你可以使用此.csv文件并将其导入到Student中。你可以使用以下查询将兼容的.csv文件导入PostgreSQL表:
COPY STUDENT FROM '/path/to/csv/Student.csv' WITH (FORMAT csv);
上面的查询假定要从中复制数据的.csv文件的名称为Student。
现在让我们看一下数据。运行select * from STUDENT;返回以下记录:
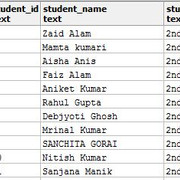
选择查询应返回总共86条记录。现在, 你可以创建索引了。你可以使用以下语法创建单列索引:
CREATE INDEX index_name
ON table_name (column_name);
让我们在student_id字段上创建一个索引(主索引)。
CREATE INDEX id_index
ON STUDENT (student_id);
也可以创建多列索引:
CREATE INDEX id_index
ON STUDENT (student_id, student_name);
你可以使用以下语法删除索引:
DROP INDEX index_name;
很难感觉到在像STUDENT这样的小表中索引正在做什么。但是, 如果表很大(考虑一个包含大大学的类似记录的数据库表), 则索引无疑将发挥至关重要的作用。
你做到了!
恭喜你成功。在本教程中, 你了解了索引, 索引的需求以及不同的索引方案。你还看到了如何在PostgreSQL中执行简单索引。
但是你没有在本教程中研究多级索引。如果你有兴趣探索以下资源, 可以参考以下资源:
- B树和B +树。它们在数据库中的作用
- B树和B +树
但是使用索引总是有帮助吗?好吧, 在某些情况下, 不建议使用索引。
资源
我希望本教程可以帮助你弄清索引的基础知识。在评论部分让我知道你的有趣发现。
评论前必须登录!
注册