 srcmini
srcmini本文概述
卷积神经网络是用于图像分类和分析的最强大的神经网络。它们的应用已经超越了许多限制, 并被证明是我们今天看到的许多支持深度学习的应用的关键要素。在非常高的水平上, CNN可以学习反馈给它们的图像的内部特征级别表示。这使它们如此强大。事实证明, CNN的这一显着特征不仅对诸如图像分类之类的任务有用, 而且对图像构建也很有用。诸如Deep Dream和Neural Style Transfer之类的应用程序基于CNN中的图层激活及其提取的功能来组成图像。
在本教程中, 你将研究神经样式转换的工作原理以及如何使用TensorFlow 2.0实现它。以下是文章的概述:
- 什么是神经样式转换?
- 内容和样式之间的隔离
- 内容功能和内容丢失
- 样式损失和克矩阵
- 结合两种损失以创建自定义损失函数
- 神经样式转换在行动
请注意, 为了跟随本教程, 你需要了解CNN的工作方式。如果你正在寻找可以快速回顾CNN的资源, 请尝试以下方法:
- srcmini的卷积神经网络图像处理课程
- CS231n:用于视觉识别的卷积神经网络
什么是神经样式转换?
对于计算机视觉和深度学习领域的新进入者来说, 术语”神经样式转换”可能有点让人难以接受。要理解该术语的每个组成部分, 请考虑以下两个图像:

在神经样式转移的上下文中, 左侧图像称为内容图像, 而右侧图像称为样式图像。你有兴趣使用另一张图片(右边的图片)样式化一张图片(在这种情况下, 左边的图片)。这就是构成术语”样式转换”的最后两个词的原因。为了执行该过程, 训练了神经网络(CNN)以优化自定义损失函数, 因此第一个词-神经。当使用神经样式传输融合以上两个图像时, 最终输出看起来像这样(右一个)-

你可能会问神经样式转换有什么用?想象一下, 你有一张由Vincent van Gogh最初绘制的绘图的图像。你想查看该工程图如何转换为你自己的工程图。这是神经样式转换找到其用途的应用程序之一。另一个示例是Prisma之类的几个照片滤镜应用程序, 可让你使用平滑的用户界面执行神经样式转换。
内容和样式之间的隔离
到目前为止, 你可能已经掌握了神经样式转换的想法是, 该过程就是将一个图像的内容与另一个图像的样式结合在一起。实际上, 这是100%正确的。在本节中, 让我们了解CNN上下文中内容和样式的实际含义。
CNN通常是几个卷积层和池化层的集合。卷积层负责从给定图像中提取高度复杂的特征, 而池化层则丢弃与图像分类问题无关的详细空间信息。这样的效果是, 它有助于CNN学习给定图像的内容, 而不是诸如颜色, 纹理等任何特定内容。随着我们深入到CNN, 功能的复杂性增加, 而更深的卷积层通常被称为内容表示。
样式的示例可以是任何特定于图像属性(例如纹理, 颜色等)的东西-例如在绘图中突出使用特定颜色。现在的问题是, 如何提取图像样式?这是通过计算卷积层之间的相关性来完成的。相关性可以衡量两个或多个变量的相似性/相关性?为了理解这一点, 请考虑由几个特征图组成的学习卷积层。对于每个要素图, 你可以测量其检测到的要素与同一图层中其他要素图的关联程度。这样可以估算出类似的情况-在第一个要素图中检测到的某种颜色是否类似于另一幅图中的颜色?要素地图上是否有任何共同的形状?这些特征/相似性定义图像的样式。测量卷积层中几个特征图的内容之间的相似性的过程有助于网络学习给定图像的多尺度表示, 该表示集中于纹理和颜色等空间特征。
要记住的一个重要点是在应用神经样式转换期间, 你还需要确保保留图像的内容以及所需的另一图像样式。你将在后面的部分中看到如何完成此操作。在下一部分中, 你将学习如何从图像(内容图像)中提取特征并计算内容损失。
量化内容图像并计算内容损失
神经样式转移算法由Gatys等人首先提出。在他们的2015年论文《艺术样式的神经算法》中。但是, 本教程参考了使用卷积神经网络进行图像样式传输的内容, 这是对前面提到的论文的延续。
根据论文《使用卷积神经网络进行图像样式传递》, 它采用了VGG-19 CNN架构, 分别从内容和样式图像中提取了内容和样式特征。为了获得内容特征, 使用(卷积层的)第四个块中的第二个卷积层。为了方便起见, 该论文的作者将其命名为conv4_2。获得内容功能后, 必须将其与目标图像进行比较以衡量内容损失。什么是目标图片?为什么在这里需要计算内容损失?让我们退后一步, 专注于这两个问题。
要将内容和样式功能组合到单个图像中, 你将需要从目标图像开始, 该目标图像可以是空白图像或内容图像的副本。现在, 要使用CNN有效地学习内容和样式功能, 你将需要一个自定义损失函数, 你将对其进行优化以从内容和样式图像构造出平滑的样式图像。此自定义损失函数本质上是两种不同损失的合并:
- 内容丢失, 这可以确保保留净内容量。
- 样式丢失, 用于处理转移到目标图像的样式数量。
既然你已经了解了以上问题, 那么让我们回到内容损失并对其进行定义。内容损失定义如下:
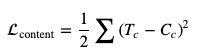
其中, $ T_c $表示目标图像, $ C_c $表示内容图像。因此, 此损失函数的作用是, 它使你可以度量内容和目标图像之间的距离。该网络的目标是尽量减少这种损失。在下一节中, 你将看到如何确定样式损失。
样式损失和克数矩阵
为了确定样式损失, 本文指示你从随后的图层中获取表示形式(本质上是数字), 并获取这些图层内的特征图的语法矩阵。
'conv1_1'
'conv2_1'
'conv3_1'
'conv4_1'
'conv5_1'
使用许多层来定义样式损失的优点是, 它允许学习图像中包含的样式的多尺度表示。 gram矩阵可帮助你确定单个卷积层内的要素地图上的要素有多相似。这进一步描绘了影响图像样式的有关图像的非本地化信息。在这种情况下, 按以下方式计算一个gram矩阵。
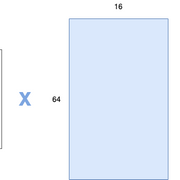
考虑卷积图像的尺寸为8x8x16, 主要表示它具有16个特征图。你现在有兴趣使用gram矩阵在这些要素图中找到要素之间的相似性。为此, 你将卷积图像的前两个维度展平, 然后将它们转换为一维矢量。在这种情况下, 如果将尺寸展平, 则一维矢量中将包含64个条目。在要素地图上重复此过程。因此, 你将获得尺寸为16×64的最终矩阵(例如矩阵A)。然后将该矩阵转置(变为64×16)并与矩阵A相乘。在这种情况下, gram矩阵的尺寸为16×16。语法矩阵中的特定值将表示特征图之间的相似性。从图形上看, 此过程类似于以下内容:
要计算目标图像和样式图像之间的样式损失, 请在每个卷积层的块处获取其克矩阵之间的均方距离。正式地, 可以定义如下:
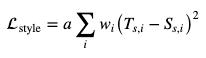
其中, T(s, i)是在方框i中计算的目标图像的语法矩阵, 而S(s, i)是在方框i中计算的样式图像的语法矩阵。使用wi, 你可以为不同的卷积块提供自定义权重, 以获得样式的详细表示。最后, $ a $是一个常量, 说明块内每一层的值。让我们将这两个损失放在一起, 以定义网络在神经样式转移过程中优化的总损失。
定义总损失
现在, 总损失只是自定义权重的附加问题-
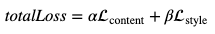
其中, $ \ alpha $表示内容权重, $ \ beta $表示样式权重。这有助于你在内容和转移到目标图像的样式量之间保持良好的平衡。在本文中可以看到$ \ alpha $和$ \ beta $不同组合的效果, 建议你检查一下。现在, 你已经将所有部分放在一起以实现神经样式转换。在下一部分中, 让我们开始吧。
神经样式转换在行动
对于实现部分, 你将使用TensorFlow 2.0。它具有许多非凡的补充, 并且是日期库中最全面的更新之一。如果你有兴趣学习其中的一些内容, 可以查看这篇文章。
TensorFlow的最新版本(在撰写本教程时)是2.0.0-beta0。如果尚未安装, 请按照此处指定的说明先安装它。你将从导入必要的包以及内容和样式图像开始。
# Packages
import tensorflow as tf
from tensorflow.keras.applications.vgg19 import preprocess_input
from tensorflow.keras.models import Model
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(7)
%matplotlib inline
print(tf.__version__)
2.0.0-beta0
# Load the content and style images
content = plt.imread('Content.jpeg')
style = plt.imread('Style.jpg')
# Display the images
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 10))
# Content and style images side-by-side
ax1.imshow(content)
ax1.set_title('Content Image')
ax2.imshow(style)
ax2.set_title('Style Image')
plt.show()

在下一步中, 你将编写一个辅助函数, 该函数将两个图像加载为数字数组(因为计算机只能理解数字), 并对其进行重塑以使其与模型兼容。
def load_image(image):
image = plt.imread(image)
img = tf.image.convert_image_dtype(image, tf.float32)
img = tf.image.resize(img, [400, 400])
# Shape -> (batch_size, h, w, d)
img = img[tf.newaxis, :]
return img
# Use load_image of content and style images
content = load_image('Content.jpeg')
style = load_image('Style.jpg')
# Verify the shapes
content.shape, style.shape
(TensorShape([1, 400, 400, 3]), TensorShape([1, 400, 400, 3]))
图像被重塑。现在, 你将加载预训练的VGG19模型以提取特征。当你将使用模型提取特征时, 将不需要模型的分类器部分。
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5
80142336/80134624 [==============================] - 5s 0us/step
作者已经指定了用于提取内容和样式特征的块名称。你刚加载的VGG19模型具有相同的命名约定。因此, 要利用这一优势, 你将首先打印网络中存在的所有层的名称。
# Print the layer names for convenience
for layer in vgg.layers:
print(layer.name)
input_1
block1_conv1
block1_conv2
block1_pool
block2_conv1
block2_conv2
block2_pool
block3_conv1
block3_conv2
block3_conv3
block3_conv4
block3_pool
block4_conv1
block4_conv2
block4_conv3
block4_conv4
block4_pool
block5_conv1
block5_conv2
block5_conv3
block5_conv4
block5_pool
但是, 你对以下获取样式功能感兴趣:
'conv1_1'
'conv2_1'
'conv3_1'
'conv4_1'
'conv5_1'
对于内容功能, 你将需要conv4_2。你将把它们相应地存储在变量中。
# Content layer
content_layers = ['block4_conv2']
# Style layer
style_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
现在创建一个将由指定图层组成的自定义VGG模型。这将帮助你在图像上向前移动并在此过程中提取必要的功能。
def mini_model(layer_names, model):
outputs = [model.get_layer(name).output for name in layer_names]
model = Model([vgg.input], outputs)
return model
在TensorFlow中定义语法矩阵非常容易, 你可以通过以下方式进行:
# Gram matrix
def gram_matrix(tensor):
temp = tensor
temp = tf.squeeze(temp)
fun = tf.reshape(temp, [temp.shape[2], temp.shape[0]*temp.shape[1]])
result = tf.matmul(temp, temp, transpose_b=True)
gram = tf.expand_dims(result, axis=0)
return gram
现在, 你将使用mini_model()函数定义一个自定义模型。这将用于从相应图像返回内容和样式特征。
class Custom_Style_Model(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(Custom_Style_Model, self).__init__()
self.vgg = mini_model(style_layers + content_layers, vgg)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
# Scale back the pixel values
inputs = inputs*255.0
# Preprocess them with respect to VGG19 stats
preprocessed_input = preprocess_input(inputs)
# Pass through the mini network
outputs = self.vgg(preprocessed_input)
# Segregate the style and content representations
style_outputs, content_outputs = (outputs[:self.num_style_layers], outputs[self.num_style_layers:])
# Calculate the gram matrix for each layer
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
# Assign the content representation and gram matrix in
# a layer by layer fashion in dicts
content_dict = {content_name:value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name:value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content':content_dict, 'style':style_dict}
现在, 你已经定义了自定义模型, 让我们在图像上使用它来相应地获取内容和样式特征-
# Note that the content and style images are loaded in
# content and style variables respectively
extractor = Custom_Style_Model(style_layers, content_layers)
style_targets = extractor(style)['style']
content_targets = extractor(content)['content']
在本文中, 优化是使用L-BFGS算法完成的, 但你也可以使用Adam。
opt = tf.optimizers.Adam(learning_rate=0.02)
现在让我们定义整体内容和样式权重, 以及每个样式表示的权重, 如前所述。请注意, 这些是超参数, 你应该使用它们。
# Custom weights for style and content updates
style_weight=100
content_weight=10
# Custom weights for different style layers
style_weights = {'block1_conv1': 1., 'block2_conv1': 0.8, 'block3_conv1': 0.5, 'block4_conv1': 0.3, 'block5_conv1': 0.1}
现在到了最关键的部分, 这使神经样式传递的过程变得更加有趣-损失函数。
# The loss function to optimize
def total_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([style_weights[name]*tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
# Normalize
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
# Normalize
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
现在, 你将编写另一个函数, 该函数将:
- 计算你刚刚定义的损失函数的梯度。
- 使用这些渐变来更新目标图像。
使用GradientTape, 你可以利用自动微分功能, 该功能可以根据函数的组成来计算函数的梯度。你还将使用tf.function装饰器加快操作速度。在此处了解更多信息。
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
# Extract the features
outputs = extractor(image)
# Calculate the loss
loss = total_loss(outputs)
# Determine the gradients of the loss function w.r.t the image pixels
grad = tape.gradient(loss, image)
# Update the pixels
opt.apply_gradients([(grad, image)])
# Clip the pixel values that fall outside the range of [0, 1]
image.assign(tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0))
你可以训练网络之前剩下的唯一步骤就是定义目标图像。对于目标图像, 你将仅使用内容图像。
target_image = tf.Variable(content)
你现在已经准备好训练网络。
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(target_image)
plt.imshow(np.squeeze(target_image.read_value(), 0))
plt.title("Train step: {}".format(step))
plt.show()
WARNING: Logging before flag parsing goes to stderr.
W0617 16:21:34.491543 140709216896896 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_grad.py:1205: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where










建议你使用内容和样式权重, 以观察目标图像的变化。
结束语
你在本教程中提到的论文没有提及进一步优化构造图像的质量。正如你可能在上述结果中观察到的那样, 在整体内容和所构造图像的样式之间的空间关系中需要一定程度的平滑度。为了解决这个问题, 引入了total_variantional_loss, 类似于使用正则化。从总体上讲, total_variational_loss惩罚了原始神经样式转换算法引入的高频伪像。如果你有兴趣实现本教程, 请查看本教程。以下是编写本教程的参考资源:
- 使用Python进行动手学习
- 神经样式转换
- 从Udacity进行样式转移的课程
- Adrian Rosebrock的计算机视觉深度学习(第二部分)
如果你想磨练你的深度学习技能, 则可能需要查看以下srcmini课程:
- Python深度学习
- 使用Keras在Python中进行高级深度学习
评论前必须登录!
注册