 srcmini
srcmini本文概述
以下课程将有助于完成此实例研究和分析:
- Python中的TensorFlow简介
- 使用Keras在Python中进行深度学习
想象一下, 你是一个在线新闻论坛的主持人, 你负责确定新闻文章的来源(发布者)。手动执行此操作可能是一项非常繁琐的任务, 因为你必须阅读新闻文章, 然后获取消息来源。那么, 如果你可以自动化该任务呢?因此, 在非常稀释的水平上, 问题陈述变成了, 我们可以根据给定的文章预测出版者的名字吗?
现在可以将该问题建模为文本分类问题。在本文的其余部分, 你将构建一个机器学习模型来解决这个问题。步骤的摘要如下所示:
- 收集资料
- 预处理数据集
- 准备好数据以供输入序列模型
- 建立, 训练和评估模型
系统设置
你将使用Google Cloud Platform(GCP)作为基础架构。从数据到用于构建模型的库, 配置此项目所需的系统很容易。你将首先分解一个Jupyter Lab实例, 该实例是GCP AI平台的一部分。为了能够在GCP的AI平台上剥离Jupyter Lab实例, 你将需要一个启用了计费功能的GCP项目。可以非常轻松地导航到AI平台上的Notebooks部分:
在”笔记本”上单击后, 将出现如下所示的仪表板:
你将为此项目使用TensorFlow 2.0, 因此请相应选择:
单击”使用1个NVIDIA Tesla K80″后, 将显示一个基本配置窗口。保持默认状态, 只需选中GPU驱动程序安装框, 然后单击CREATE。
获取实例将需要一些时间(约5分钟)。准备好实例后, 你只需单击OPEN JUPYTERLAB即可访问笔记本实例。
你还将在此项目中以及通过笔记本使用BigQuery。因此, 一旦获得笔记本实例, 就打开一个终端以安装BigQuery笔记本扩展:
pip3 install --upgrade google-cloud-bigquery
系统设置部分就是这样。
BigQuery是一个无服务器, 高度可扩展且经济高效的云数据仓库, 具有内存BI引擎和内置的机器学习功能。
我们从哪里获得数据?
数据并非总是可以随时用于你要解决的问题。幸运的是, 在这种情况下, 已经有一个数据集, 足以开始使用。
你将要使用的数据集已经可以作为BigQuery公共数据集(链接)使用。但是, 数据集需要在形状上与问题陈述保持一致。你稍后再来。
该数据集包含从2006年推出至今的Hacker News的所有故事和评论。每个故事都包含一个故事ID, 撰写该帖子的作者, 撰写该文章的时间以及该故事获得的分数。
为了在我的笔记本实例中正确获取数据, 你需要在笔记本环境中配置GCP项目:
# Set your Project ID
import os
PROJECT = 'your-project-name'
os.environ['PROJECT'] = PROJECT
将你的项目名称替换为你的GCP项目的名称。现在, 你可以运行查询来访问BigQuery数据集了:
%%bigquery --project $PROJECT data_preview
SELECT
url, title, score
FROM
`bigquery-public-data.hacker_news.stories`
WHERE
LENGTH(title) > 10
AND score > 10
AND LENGTH(url) > 0
LIMIT 10
让我们在这里分解几件事:
- %% bigquery-项目$ PROJECT data_preview:%% bigquery是一个魔术命令, 可让你从笔记本中运行类似查询的SQL(与BigQuery兼容)。 –project $ PROJECT用于指导BigQuery你正在使用哪个GCP项目。 data_preview是你要将查询结果保存到的Pandas DataFrame的名称(这不是很有用吗?)。
- hacker_news是BigQuey公开数据集的名称, stories是驻留在其中的表的名称。
- 仅三列:文章的url, 文章的标题和文章的分数。你将使用文章标题来确定其来源。
你选择仅包括文章标题和文章的相应URL的长度大于10的那些条目。查询返回了402 MB的数据。
这是DataFrame data_preview中的前五行:
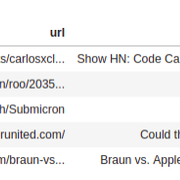
现在已为项目完成了数据收集部分。在这个阶段, 我们可以继续进行以下步骤:清洁和预处理!
开始数据整理
当前数据的问题是代替url, 你需要URL的来源。例如, https://github.com/Groundworkstech/Submicron应该显示为github。你还希望将url列重命名为源。但是在此之前, 我们已经弄清楚标题中的分布属于几个来源。
%%bigquery --project $PROJECT source_num_articles
SELECT
ARRAY_REVERSE(SPLIT(REGEXP_EXTRACT(url, '.*://(.[^/]+)/'), '.'))[OFFSET(1)] AS source, COUNT(title) AS num_articles
FROM
`bigquery-public-data.hacker_news.stories`
WHERE
REGEXP_CONTAINS(REGEXP_EXTRACT(url, '.*://(.[^/]+)/'), '.com$')
AND LENGTH(title) > 10
GROUP BY
source
ORDER BY num_articles DESC
预览source_num_articles数据框:
source_num_articles.head()
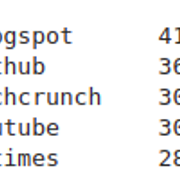
| 资源 | num_articles | |
|---|---|---|
| 0 | Blogspot | 41386 |
| 1 | github | 36525 |
| 2 | Techcrunch | 30891 |
| 3 | youtube | 30848 |
| 4 | 纽约时报 | 28787 |
BigQuery提供了一些功能, 如ARRAY_REVERSE(), REGEXP_EXTRACT()等, 用于完成有用的任务。通过上面的查询, 我们首先根据//和/分割URL, 然后从URL中提取域。
但是该项目需要不同的数据-一个数据集, 其中将包含文章及其来源。故事表除了上面显示的之外, 还包含许多文章来源。因此, 为了使它更轻巧, 让我们来研究以下五个:博客文章, github, techcrunch, youtube和nytimes。
%%bigquery --project $PROJECT full_data
SELECT source, LOWER(REGEXP_REPLACE(title, '[^a-zA-Z0-9 $.-]', ' ')) AS title FROM
(SELECT
ARRAY_REVERSE(SPLIT(REGEXP_EXTRACT(url, '.*://(.[^/]+)/'), '.'))[OFFSET(1)] AS source, title
FROM
`bigquery-public-data.hacker_news.stories`
WHERE
REGEXP_CONTAINS(REGEXP_EXTRACT(url, '.*://(.[^/]+)/'), '.com$')
AND LENGTH(title) > 10
)
WHERE (source = 'github' OR source = 'nytimes' OR
source = 'techcrunch' or source = 'blogspot' OR
source = 'youtube')
预览full_data DataFrame, 你将获得:
full_data.head()
| 资源 | 标题 | |
|---|---|---|
| 0 | github | 女权主义软件基金会抱怨… |
| 1 | github | 将sps即时公开为Web服务。 |
| 2 | github | 显示hn scrwl速记代码阅读和编写… |
| 3 | github | 现在, nodejs上的geoip模块是一个c插件 |
| 4 | github | 显示hn linuxexplorer |
数据理解对于机器学习建模正常工作和被理解至关重要。让我们花一些时间执行一些基本的EDA。
数据理解
你将通过研究数据集的维度来开始EDA的过程。在这种情况下, 如在预览中所见, 在上述步骤中准备的数据集具有168437行, 包括2列。
以下是文章的类分布:
幸运的是, 数据集中没有缺失值, 下面的细微调整可以帮助你了解:
# Missing value inspection
full_data.isna().sum()
source 0
title 0
dtype: int64
在处理像这样的文本数据时出现的一个常见问题是标题的长度如何分布?
幸运的是, Pandas提供了许多有用的功能来回答这样的问题。
full_data['title'].apply(len).describe()
count 168437.000000
mean 46.663174
std 17.080766
min 11.000000
25% 34.000000
50% 46.000000
75% 59.000000
max 138.000000
Name: title, dtype: float64
你的最小长度为11, 最大长度为138。我们稍后将再次讨论。
没有情节的EDA是不完整的!在这种情况下, 一个非常有用的图可以是计数与标题长度:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('ggplot')
%matplotlib inline
text_lens = full_data['title'].apply(len).values
plt.figure(figsize=(10, 8))
sns.set()
g = sns.distplot(text_lens, kde=False, hist_kws={'rwidth':1})
g.set_xlabel('Title length')
g.set_ylabel('Count')
plt.show()
/usr/local/lib/python3.5/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval

几乎是钟声, 不是吗?从图中可以明显看出, 标题长度<20和> 80的计数是倾斜的。因此, 在处理它们时可能要小心。让我们执行一些手动检查以找出:
- 超过最小标题长度(11)的标题有多少?
- 最大长度(138)有多少个书名?
让我们找出答案。
(text_lens <= 11).sum(), (text_lens == 138).sum()
(513, 1)
你应该分别获得513和1。现在, 你将从数据集中删除表示最大文章长度的条目, 因为它只是1:
full_data = full_data[text_lens < 138].reset_index(drop=True)
在此步骤中, 你要做的最后一件事是将数据集以80:10:10的比例分成训练/验证/测试集。
# 80% for train
train = full_data.sample(frac=0.8)
full_data.drop(train.index, axis=0, inplace=True)
# 10% for validation
valid = full_data.sample(frac=0.5)
full_data.drop(valid.index, axis=0, inplace=True)
# 10% for test
test = full_data
train.shape, valid.shape, test.shape
((134749, 2), (16844, 2), (16843, 2))
新数据维为:(((110070, 2), (13759, 2), (13759, 2)))。为了更确定类的分布, 现在你将在三个集合中进行验证:
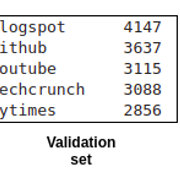
这三个集合的分布相对相同。让我们将这三组序列化为Pandas DataFrames。
train.to_csv('data/train.csv', index=False)
valid.to_csv('data/valid.csv', index-False)
test.to_csv('data/test.csv', index=False)
仍然需要大量的数据预处理-由于计算机只能理解数字, 因此你将相应地准备数据以流式传输到机器学习模型:
- 将类编码为一些数字(标签编码/单次编码)
- 从训练语料库-标记化中创建词汇表
- 数字化标题并将其填充为固定长度
- 针对像GloVe这样的预训练嵌入准备嵌入矩阵。
让我们继续进行。
附加数据预处理
首先, 你将在此处定义必要的常量:
# Label encode
CLASSES = {'blogspot': 0, 'github': 1, 'techcrunch': 2, 'nytimes': 3, 'youtube': 4}
# Maximum vocabulary size used for tokenization
TOP_K = 20000
# Sentences will be truncated/padded to this length
MAX_SEQUENCE_LENGTH = 50
现在, 你将定义一个小的辅助函数, 该函数将使用Pandas DataFrame并将
- 从DataFrame准备标题列表(需要进一步预处理)
- 从DataFrame中获取源, 将它们映射为整数并追加到NumPy数组
def return_data(df):
return list(df['title']), np.array(df['source'].map(CLASSES))
# Apply it to the three splits
train_text, train_labels = return_data(train)
valid_text, valid_labels = return_data(valid)
test_text, test_labels = return_data(test)
print(train_text[0], train_labels[0])
the davos question. what one thing must be done to make the world a better place in 2008 4
结果是预期的。
你将使用tensorflow.keras.preprocessing提供的text和sequence模块标记和填充标题。你将从标记化开始:
# TensorFlow imports
import tensorflow as tf
from tensorflow.keras.preprocessing import sequence, text
from tensorflow.keras import models
from tensorflow.keras.layers import Dense, Dropout, Embedding, Conv1D, MaxPooling1D, GlobalAveragePooling1D
# Create a vocabulary from training corpus
tokenizer = text.Tokenizer(num_words=TOP_K)
tokenizer.fit_on_texts(train_text)
你将使用GloVe嵌入将标题中的单词表示为密集表示。嵌入文件的大小超过650 MB, GCP小组已将其存储在Google存储桶中。这非常有用, 因为它可以让你以非常快的速度直接在笔记本中使用它。你将使用gsutil命令(在笔记本电脑中可用)来辅助此操作。
!gsutil cp gs://cloud-training-demos/courses/machine_learning/deepdive/09_sequence/text_classification/glove.6B.200d.txt glove.6B.200d.txt
你将需要一个辅助函数, 该函数将根据Glove嵌入映射标题中的单词。
def get_embedding_matrix(word_index, embedding_path, embedding_dim):
embedding_matrix_all = {}
with open(embedding_path) as f:
for line in f: # Every line contains word followed by the vector value
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embedding_matrix_all[word] = coefs
# Prepare embedding matrix with just the words in our word_index dictionary
num_words = min(len(word_index) + 1, TOP_K)
embedding_matrix = np.zeros((num_words, embedding_dim))
for word, i in word_index.items():
if i >= TOP_K:
continue
embedding_vector = embedding_matrix_all.get(word)
if embedding_vector is not None:
# Words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vector
return embedding_matrix
这就是将文本数据流传输到尚待构建的机器学习模型所需的全部。
构建Horcrux:顺序语言模型
让我们在建模过程的开始就指定几个超参数值。
# Specify the hyperparameters
filters=64
dropout_rate=0.2
embedding_dim=200
kernel_size=3
pool_size=3
word_index=tokenizer.word_index
embedding_path = 'glove.6B.200d.txt'
embedding_dim=200
你将使用基于卷积神经网络的模型, 该模型首先从卷积到馈送给它的嵌入开始。在顺序数据中, 局部性很重要, 而CNN可以让你有效地捕获数据。诀窍是在一维中执行所有基本的CNN操作(卷积, 池化)。
你将遵循典型的Keras范例-先实例化模型, 然后定义拓扑并相应地编译模型。
# Create model instance
model = models.Sequential()
num_features = min(len(word_index) + 1, TOP_K)
# Add embedding layer - GloVe embeddings
model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=MAX_SEQUENCE_LENGTH, weights=[get_embedding_matrix(word_index, embedding_path, embedding_dim)], trainable=True))
model.add(Dropout(rate=dropout_rate))
model.add(Conv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='he_normal', padding='same'))
model.add(MaxPooling1D(pool_size=pool_size))
model.add(Conv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='he_normal', padding='same'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(rate=dropout_rate))
model.add(Dense(len(CLASSES), activation='softmax'))
# Compile model with learning parameters.
optimizer = tf.keras.optimizers.Adam(lr=0.001)
model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['acc'])
架构看起来像这样:

此时还需要执行的另一步骤是将标题数字化并将其填充为固定长度。
# Preprocess the train, validation and test sets
# Tokenize and pad sentences
preproc_train = tokenizer.texts_to_sequences(train_text)
preproc_train = sequence.pad_sequences(preproc_train, maxlen=MAX_SEQUENCE_LENGTH)
preproc_valid = tokenizer.texts_to_sequences(valid_text)
preproc_valid = sequence.pad_sequences(preproc_valid, maxlen=MAX_SEQUENCE_LENGTH)
preproc_test = tokenizer.texts_to_sequences(test_text)
preproc_test = sequence.pad_sequences(preproc_test, maxlen=MAX_SEQUENCE_LENGTH)
最后, 你准备好开始培训过程了!
H = model.fit(preproc_train, train_labels, validation_data=(preproc_valid, valid_labels), batch_size=128, epochs=10, verbose=1)
这是培训日志的快照:
网络确实过拟合, 训练图也证实了这一点:

总体而言, 该模型产生的准确度约为66%, 考虑到小时的发展情况, 这还没有达到标准。但这是一个好的开始。现在, 让我们编写一个小函数来使用网络来预测各个样本:
# Helper function to test on single samples
def test_on_single_sample(text):
category = None
text_tokenized = tokenizer.texts_to_sequences(text)
text_tokenized = sequence.pad_sequences(text_tokenized, maxlen=50)
prediction = int(model.predict_classes(text_tokenized))
for key, value in CLASSES.items():
if value==prediction:
category=key
return category
相应地准备样品:
# Prepare the samples
github=['Invaders game in 512 bytes']
nytimes = ['Michael Bloomberg Promises $500M to Help End Coal']
techcrunch = ['Facebook plans June 18th cryptocurrency debut']
blogspot = ['Android Security: A walk-through of SELinux']
最后, 在上述示例中测试test_on_single_sample():
for sample in [github, nytimes, techcrunch, blogspot]:
print(test_on_single_sample(sample))
github
techcrunch
techcrunch
blogspot
就是这个项目。在下一部分中, 你将找到我对该项目的未来发展方向的评论, 然后是此项目使用的一些参考。
未来的方向和参考
就像在计算机视觉领域一样, 我们期望能够理解领域的模型对于某些转换(例如旋转和平移)具有鲁棒性。在序列域中, 重要的是模型要对模式长度的变化具有鲁棒性。请记住, 这是我不久将尝试的清单:
- 尝试其他序列模型
- 一些超参数调整
- 从零开始学习嵌入
- 尝试不同的嵌入, 例如通用句子编码器, nnlm-128等
在拥有一个不错的模型(准确性至少达到80%)之后, 我计划将该模型用作REST API, 并将其部署在AppEngine上。
以下是对该项目非常有用的参考:
- Google的文字分类指南
- Jason Brownlee(机器学习精通)的时间序列预测深度学习
- FrançoisChollet的Python深度学习
- 时间序列和自然语言处理的序列模型, 这是由Google Cloud团队设计和开发的课程(通过Coursera提供)
这是本文的结尾。我写这篇文章是为了向你介绍我通常针对机器学习问题采用的方法。当然, 还有更多内容, 但是我上面显示的步骤对我来说是最重要的步骤。感谢你抽出宝贵的时间阅读本文, 下次再见。
评论前必须登录!
注册