 srcmini
srcmini本文概述
在当今的互联网和在线服务领域, 数据正以惊人的速度和数量生成。通常, 数据分析师, 工程师和科学家正在处理关系或表格数据。这些表格数据列具有数字或分类数据。生成的数据具有多种结构, 例如文本, 图像, 音频和视频。诸如文章, 网站文本, 博客文章, 社交媒体文章之类的在线活动正在生成非结构化的文本数据。公司和企业需要分析文本数据以了解客户的活动, 意见和反馈, 以成功开展业务。为了与大文本数据竞争, 文本分析的发展速度比以往任何时候都要快。
文本分析在当今的在线世界中有许多应用程序。通过分析Twitter上的推文, 我们可以发现趋势新闻和人们对特定事件的反应。亚马逊可以了解用户的反馈或对特定产品的评论。 BookMyShow可以发现人们对电影的看法。 YouTube还可以分析和理解视频中人们的观点。
在本教程中, 你将涵盖以下主题:
- 文字分析和NLP
- 比较文本分析, NLP和文本挖掘
- 使用NLTK的文本分析操作
- 代币化
- 停用词
- 词法归一化, 例如词干和词法分解
- POS标签
- 情绪分析
- 文字分类
- 使用文本分类执行情感分析
文字分析和NLP
文本通信是最流行的日常转换形式之一。我们在日常工作中聊天, 发送消息, 发布推文, 分享状态, 发送电子邮件, 撰写博客, 分享意见和反馈。所有这些活动都在生成大量文本, 这些文本本质上是非结构化的。在在线市场和社交媒体领域, 分析大量数据, 理解人们的意见至关重要。
NLP使计算机能够以自然方式与人互动。它可以帮助计算机理解人类语言并从中获得意义。 NLP适用于从语音识别, 语言翻译, 文档分类到信息提取的若干问题。分析电影评论是在电影评论上演示一个简单的NLP词袋模型的经典示例之一。
比较文本分析, NLP和文本挖掘
文本挖掘也称为文本分析。文本挖掘是探索大量文本数据并查找模式的过程。文本挖掘处理文本本身, 而NLP处理基础元数据。查找单词的频率计数, 句子的长度, 特定单词的存在/不存在被称为文本挖掘。自然语言处理是文本挖掘的组成部分之一。 NLP有助于识别情绪, 在句子中找到实体以及博客/文章的类别。文本挖掘是用于文本分析的预处理数据。在文本分析中, 统计和机器学习算法用于对信息进行分类。
使用NLTK的文本分析操作
NLTK是一个功能强大的Python软件包, 提供了一组多种自然语言算法。它是免费的, 开源的, 易于使用的, 庞大的社区并且有据可查。 NLTK由最常用的算法组成, 例如标记化, 词性标记, 词干, 情感分析, 主题细分和命名实体识别。 NLTK帮助计算机分析, 预处理和理解书面文本。
!pip install nltk
Requirement already satisfied: nltk in /home/northout/anaconda2/lib/python2.7/site-packages
Requirement already satisfied: six in /home/northout/anaconda2/lib/python2.7/site-packages (from nltk)
[33mYou are using pip version 9.0.1, however version 10.0.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.[0m
#Loading NLTK
import nltk
代币化
标记化是文本分析的第一步。将文本段落分解为较小的块(例如单词或句子)的过程称为标记化。令牌是为句子或段落构建模块的单个实体。
句子标记化
句子标记器将文本段落分解为句子。
from nltk.tokenize import sent_tokenize
text="""Hello Mr. Smith, how are you doing today? The weather is great, and city is awesome.
The sky is pinkish-blue. You shouldn't eat cardboard"""
tokenized_text=sent_tokenize(text)
print(tokenized_text)
['Hello Mr. Smith, how are you doing today?', 'The weather is great, and city is awesome.', 'The sky is pinkish-blue.', "You shouldn't eat cardboard"]
在这里, 给定的文本被标记为句子。
词标记化
Word分词器将文本段落分解为单词。
from nltk.tokenize import word_tokenize
tokenized_word=word_tokenize(text)
print(tokenized_word)
['Hello', 'Mr.', 'Smith', ', ', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ', ', 'and', 'city', 'is', 'awesome', '.', 'The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard']
频率分布
from nltk.probability import FreqDist
fdist = FreqDist(tokenized_word)
print(fdist)
<FreqDist with 25 samples and 30 outcomes>
fdist.most_common(2)
[('is', 3), (', ', 2)]
# Frequency Distribution Plot
import matplotlib.pyplot as plt
fdist.plot(30, cumulative=False)
plt.show()

停用词
停用词在文本中被视为噪音。文本可能包含停用词, 例如is, am, are, this, a, an, the等。
在用于删除停用词的NLTK中, 你需要创建停用词列表并从这些单词中过滤出标记列表。
from nltk.corpus import stopwords
stop_words=set(stopwords.words("english"))
print(stop_words)
{'their', 'then', 'not', 'ma', 'here', 'other', 'won', 'up', 'weren', 'being', 'we', 'those', 'an', 'them', 'which', 'him', 'so', 'yourselves', 'what', 'own', 'has', 'should', 'above', 'in', 'myself', 'against', 'that', 'before', 't', 'just', 'into', 'about', 'most', 'd', 'where', 'our', 'or', 'such', 'ours', 'of', 'doesn', 'further', 'needn', 'now', 'some', 'too', 'hasn', 'more', 'the', 'yours', 'her', 'below', 'same', 'how', 'very', 'is', 'did', 'you', 'his', 'when', 'few', 'does', 'down', 'yourself', 'i', 'do', 'both', 'shan', 'have', 'itself', 'shouldn', 'through', 'themselves', 'o', 'didn', 've', 'm', 'off', 'out', 'but', 'and', 'doing', 'any', 'nor', 'over', 'had', 'because', 'himself', 'theirs', 'me', 'by', 'she', 'whom', 'hers', 're', 'hadn', 'who', 'he', 'my', 'if', 'will', 'are', 'why', 'from', 'am', 'with', 'been', 'its', 'ourselves', 'ain', 'couldn', 'a', 'aren', 'under', 'll', 'on', 'y', 'can', 'they', 'than', 'after', 'wouldn', 'each', 'once', 'mightn', 'for', 'this', 'these', 's', 'only', 'haven', 'having', 'all', 'don', 'it', 'there', 'until', 'again', 'to', 'while', 'be', 'no', 'during', 'herself', 'as', 'mustn', 'between', 'was', 'at', 'your', 'were', 'isn', 'wasn'}
删除停用词
filtered_sent=[]
for w in tokenized_sent:
if w not in stop_words:
filtered_sent.append(w)
print("Tokenized Sentence:", tokenized_sent)
print("Filterd Sentence:", filtered_sent)
Tokenized Sentence: ['Hello', 'Mr.', 'Smith', ', ', 'how', 'are', 'you', 'doing', 'today', '?']
Filterd Sentence: ['Hello', 'Mr.', 'Smith', ', ', 'today', '?']
词汇规范化
词典规范化考虑了文本中的另一种噪声。例如, “连接”, “连接”, “连接”词简化为通用词”连接”。它将单词的派生相关形式简化为公共词根。
抽干
词干提取是语言规范化的过程, 可将词缩减为词根词或将衍生词缀切掉。例如, “连接”, “连接”, “连接”词简化为通用词”连接”。
# Stemming
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
ps = PorterStemmer()
stemmed_words=[]
for w in filtered_sent:
stemmed_words.append(ps.stem(w))
print("Filtered Sentence:", filtered_sent)
print("Stemmed Sentence:", stemmed_words)
Filtered Sentence: ['Hello', 'Mr.', 'Smith', ', ', 'today', '?']
Stemmed Sentence: ['hello', 'mr.', 'smith', ', ', 'today', '?']
合法化
词法化将单词还原为基本单词, 这是语言上正确的引理。它通过词汇和词法分析来转换词根。合法化通常比阻止更为复杂。 Stemmer在不了解上下文的情况下处理单个单词。例如, 单词”更好”的引理是”好”。由于需要字典查找, 因此会错过该内容。
#Lexicon Normalization
#performing stemming and Lemmatization
from nltk.stem.wordnet import WordNetLemmatizer
lem = WordNetLemmatizer()
from nltk.stem.porter import PorterStemmer
stem = PorterStemmer()
word = "flying"
print("Lemmatized Word:", lem.lemmatize(word, "v"))
print("Stemmed Word:", stem.stem(word))
Lemmatized Word: fly
Stemmed Word: fli
POS标签
词性(POS)标记的主要目标是识别给定单词的语法组。根据上下文, 它是名词, 代词, 修饰语, 动词, ADVERBS等。 POS标签在句子中查找关系, 并为单词分配一个相应的标签。
sent = "Albert Einstein was born in Ulm, Germany in 1879."
tokens=nltk.word_tokenize(sent)
print(tokens)
['Albert', 'Einstein', 'was', 'born', 'in', 'Ulm', ', ', 'Germany', 'in', '1879', '.']
nltk.pos_tag(tokens)
[('Albert', 'NNP'), ('Einstein', 'NNP'), ('was', 'VBD'), ('born', 'VBN'), ('in', 'IN'), ('Ulm', 'NNP'), (', ', ', '), ('Germany', 'NNP'), ('in', 'IN'), ('1879', 'CD'), ('.', '.')]
POS标签:阿尔伯特/ NNP爱因斯坦/ NNP是/ VBD出生的/ VBN在/ IN乌尔姆/ NNP, /, 德国/ NNP在/ IN 1879 / CD ./。
情绪分析
如今, 公司想了解, 他们的最新产品出了什么问题?哪些用户和公众对最新功能有何看法?你可以使用情感分析以合理的准确性量化此类信息。
量化用户的内容, 想法, 信念和观点被称为情感分析。用户的在线帖子, 博客, 推文, 产品反馈可帮助业务人员吸引目标受众并创新产品和服务。情绪分析有助于更好, 更准确地了解人们。它不仅限于市场营销, 还可以用于政治, 研究和安全领域。
人际交流不仅限于文字, 还不只是文字。情感是单词, 语气和写作风格的组合。作为数据分析师, 更重要的是了解我们的观点, 这真正意味着什么?

主要有两种进行情感分析的方法。
- 基于词汇的:计算给定文本中正词和负词的数量, 较大的数字将是文本的情感。
- 基于机器学习的方法:开发分类模型, 使用预先标记的正面, 负面和中性数据集进行训练。
在本教程中, 你将使用第二种方法(基于机器学习的方法)。这是你通过一个示例学习情绪和文本分类的方式。
文字分类
文本分类是文本挖掘的重要任务之一。这是一种有监督的方法。标识给定文本的类别或类别, 例如博客, 书籍, 网页, 新闻文章和推文。它在当今的计算机世界中具有各种应用程序, 例如垃圾邮件检测, CRM服务中的任务分类, 电子零售商网站上的产品分类, 搜索引擎网站内容分类, 客户反馈情绪等。在下一部分中, 你将将学习如何在python中进行文本分类。
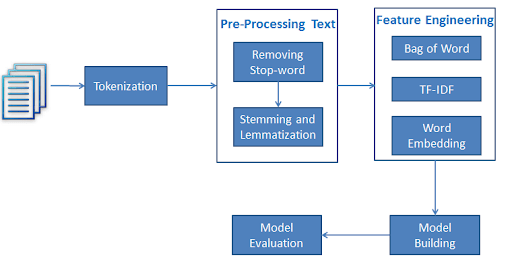
使用文本分类执行情感分析
# Import pandas
import pandas as pd
加载数据中
到目前为止, 你已经了解了使用NLTK进行数据预处理的方法。现在, 你将学习文本分类。你将使用scikit-learn执行多数值朴素贝叶斯分类。
在模型的构建部分中, 你可以使用Kaggle上可用的”电影, 评论的情感分析”数据集。数据集是一个制表符分隔的文件。数据集具有四列PhraseId, SentenceId, Phrase和Sentiment。
该数据有5个情感标签:
0-负面1-负面2-中立3-正面4-正面
在这里, 你可以建立一个模型来对品种类型进行分类。该数据集在Kaggle上可用。你可以从以下链接下载它:https://www.kaggle.com/c/sentiment-analysis-on-movie-reviews/data
data=pd.read_csv('train.tsv', sep='\t')
data.head()
| 短语编号 | SentenceId | 短语 | 情绪 | |
|---|---|---|---|---|
| 0 | 1 | 1 | 一系列的谚语展示了格言… | 1 |
| 1 | 2 | 1 | 一系列的谚语展示了格言… | 2 |
| 2 | 3 | 1 | 一系列 | 2 |
| 3 | 4 | 1 | 一个 | 2 |
| 4 | 5 | 1 | 系列 | 2 |
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 156060 entries, 0 to 156059
Data columns (total 4 columns):
PhraseId 156060 non-null int64
SentenceId 156060 non-null int64
Phrase 156060 non-null object
Sentiment 156060 non-null int64
dtypes: int64(3), object(1)
memory usage: 4.8+ MB
data.Sentiment.value_counts()
2 79582
3 32927
1 27273
4 9206
0 7072
Name: Sentiment, dtype: int64
Sentiment_count=data.groupby('Sentiment').count()
plt.bar(Sentiment_count.index.values, Sentiment_count['Phrase'])
plt.xlabel('Review Sentiments')
plt.ylabel('Number of Review')
plt.show()

使用词袋生成特征
在”文本分类问题”中, 我们有一组文本及其各自的标签。但是我们不能直接在模型中使用文本。你需要将这些文本转换为一些数字或数字向量。
词袋模型(BoW)是从文本中提取特征的最简单方法。 BoW将文本转换为文档中单词出现的矩阵。该模型关注给定单词是否出现在文档中。
示例:有三个文档:
Doc 1:我爱狗。 Doc 2:我讨厌狗和编织物。 Doc 3:编织是我的爱好和激情。
现在, 你可以通过计算给定文档中单词的出现来创建文档和单词的矩阵。该矩阵称为文档术语矩阵(DTM)。
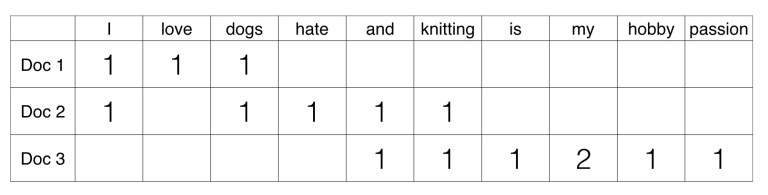
该矩阵使用单个单词。它可以是两个或两个以上单词的组合, 称为双字母组或三字母组模型, 而一般的方法称为n元语法模型。
你可以使用scikit-learn的CountVectorizer生成文档术语矩阵。
from sklearn.feature_extraction.text import CountVectorizer
from nltk.tokenize import RegexpTokenizer
#tokenizer to remove unwanted elements from out data like symbols and numbers
token = RegexpTokenizer(r'[a-zA-Z0-9]+')
cv = CountVectorizer(lowercase=True, stop_words='english', ngram_range = (1, 1), tokenizer = token.tokenize)
text_counts= cv.fit_transform(data['Phrase'])
拆分火车和测试仪
为了了解模型的性能, 将数据集分为训练集和测试集是一个很好的策略。
让我们使用函数train_test_split()拆分数据集。你基本上需要传递3个参数功能, 目标和test_set大小。此外, 你可以使用random_state随机选择记录。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
text_counts, data['Sentiment'], test_size=0.3, random_state=1)
模型建立与评估
让我们使用TF-IDF构建文本分类模型。
首先, 导入MultinomialNB模块, 并使用MultinomialNB()函数创建一个天真的Bayes分类器对象。
然后, 使用fit()将模型拟合到训练集上, 并使用predict()对测试集执行预测。
from sklearn.naive_bayes import MultinomialNB
#Import scikit-learn metrics module for accuracy calculation
from sklearn import metrics
# Model Generation Using Multinomial Naive Bayes
clf = MultinomialNB().fit(X_train, y_train)
predicted= clf.predict(X_test)
print("MultinomialNB Accuracy:", metrics.accuracy_score(y_test, predicted))
MultinomialNB Accuracy: 0.604916912299
好吧, 使用CountVector(或BoW)得出的分类率为60.49%, 这被认为不是很好的准确性。我们需要改善这一点。
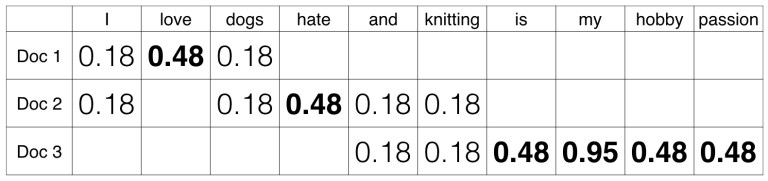
使用TF-IDF生成特征
在术语频率(TF)中, 你只需计算每个文档中出现的单词数。此术语频率的主要问题是它将赋予较长的文档更多的权重。术语频率基本上是BoW模型的输出。
IDF(反向文档频率)衡量给定单词在整个文档中提供的信息量。 IDF是包含单词的文档数量与文档总数的对数比例反比。
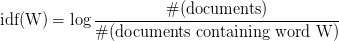
TF-IDF(术语频率-逆文档频率)对文档术语矩阵进行归一化。它是TF和IDF的产品。在一个文档中具有高tf-idf的单词, 它在大多数情况下发生在给定文档中, 而在其他文档中则必须不存在。因此, 这些词必须是签名词。
from sklearn.feature_extraction.text import TfidfVectorizer
tf=TfidfVectorizer()
text_tf= tf.fit_transform(data['Phrase'])
拆分训练和测试集(TF-IDF)
让我们使用函数train_test_split()拆分数据集。你基本上需要传递3个参数功能, 目标和test_set大小。此外, 你可以使用random_state随机选择记录。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
text_tf, data['Sentiment'], test_size=0.3, random_state=123)
模型建立与评估(TF-IDF)
让我们使用TF-IDF构建文本分类模型。
首先, 导入MultinomialNB模块, 并使用MultinomialNB()函数创建Multinomial Naive Bayes分类器对象。
然后, 使用fit()将模型拟合到训练集上, 并使用predict()对测试集执行预测。
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
# Model Generation Using Multinomial Naive Bayes
clf = MultinomialNB().fit(X_train, y_train)
predicted= clf.predict(X_test)
print("MultinomialNB Accuracy:", metrics.accuracy_score(y_test, predicted))
MultinomialNB Accuracy: 0.586526549618
好吧, 使用TF-IDF功能获得的分类率为58.65%, 这被认为不是很好的准确性。我们需要通过使用其他一些预处理或特征工程来提高准确性。让我们在注释框中建议一些提高准确性的方法。
总结
恭喜, 你已完成本教程的结尾!
在本教程中, 你学习了什么是文本分析, NLP和文本挖掘, 使用NLTK的文本分析操作的基础知识, 例如令牌化, 规范化, 词干, 词法化和POS标记。使用scikit-learn进行情感分析和文本分类是什么?
我期待听到任何反馈或问题。你可以通过发表评论来提出问题, 我会尽力回答。
如果你有兴趣了解有关Python的更多信息, 请参加srcmini的Python自然语言处理基础知识课程。
评论前必须登录!
注册