 srcmini
srcmini接上一节Core Foundation编程:Core Foundation编程概念全解
为了管理Core Foundation内存,使用了分配器allocator、引用计数机制和由函数名建议的对象所有权策略。本主题涵盖了创建Create、复制Copy、保留Retain和释放Release对象的相关技术。
内存管理是有效使用Core Foundation的基础。本文档对于所有使用Core Foundation的开发人员来说都是必读的。
本文内容的组织
下面的概念和任务讨论内建的支持Core Foundation提供的管理内存分配和对象的释放:
- 所有权的策略
- Core Foundation对象生命周期管理
- 复制函数Copy
- 分配器alloctor
如果你需要自定义你的分配器alloctor,然后阅读:
- 在创建函数中使用分配器
- 使用分配器上下文
- 创建自定义的分配器
要了解更多关于字节排序和交换见:
- 字节次序
- 字节交换
分配器alloctor
Core Foundation抽象的操作系统服务之一是内存分配,它使用分配器进行内存分配和释放。
分配器是不透明的对象,它为你分配和释放内存。你从不需要为Core Foundation对象直接分配、重新分配或释放内存——你也很少需要这样做。将分配器传递到创建对象的函数中;这些函数的名称中嵌入了“Create”,例如CFStringCreateWithPascalString。创建函数使用分配器为它们创建的对象分配内存。
分配程序通过其生命周期与对象关联。如果需要重新分配内存,则对象将为此使用分配器,而当对象需要重新分配时,则将分配器用于对象的重新分配。分配器还用于创建最初创建的对象所需的任何对象。有些函数还允许你为特殊目的传递分配器,比如释放临时缓冲区的内存。
Core Foundation允许你创建自己的自定义分配器。Core Foundation还提供了一个系统分配器,并最初将这个分配器设置为当前线程的默认分配器。(每个线程有一个默认的分配器。)你可以在代码中的任何时候将自定义分配器设置为线程的默认分配器。然而,系统分配器是一个优秀的通用分配器,它应该足以满足几乎所有的环境。在特殊情况下,定制分配器可能是必要的,例如在Mac OS 9上的某些情况下,或者在性能有问题时作为批量分配器。除了这些罕见的情况外,你既不应该使用自定义分配器,也不应该将它们设置为默认分配器,特别是对于库。
有关分配器的更多信息,特别是有关创建自定义分配器的信息,请参见创建自定义分配器。
所有权的策略
使用Core Foundation的应用程序不断地访问、创建和处理对象。为了确保不泄漏内存,Core Foundation定义了获取和创建对象的规则。
基本原理
在尝试理解Core Foundation应用程序中的内存管理时,最好不要从内存管理本身出发,而是从对象所有权出发。一个对象可以有一个或多个所有者;它使用retain count记录所有者的数量。如果一个对象没有所有者(如果其retain count下降到零),则释放它。Core Foundation为对象的所有权和处置定义了以下规则。
- 如果你创建了一个对象(直接创建或通过复制另一个对象—请参阅创建规则),则你拥有它。
- 如果你从其他地方得到一个对象,你就不拥有它。如果你想防止它被处理,你必须添加你自己作为一个所有者(使用CFRetain)。
- 如果你是一个对象的所有者,你必须放弃所有权时,你已经完成使用它(使用CFRelease)。
命名约定
使用Core Foundation有许多方法可以获得对对象的引用。与Core Foundation所有权策略相一致,你需要知道你是否拥有一个由函数返回的对象,以便你知道在内存管理方面应该采取什么操作。Core Foundation为其函数建立了命名约定,允许你确定是否拥有函数返回的对象。简而言之,如果函数名包含“Creat”或“Copy”两个字,则对象归你所有。如果函数名包含单词“Get”,则不拥有该对象。这些规则在Create规则和Get规则中有更详细的说明。
要点:Cocoa为内存管理定义了一组类似的命名约定(参见高级内存管理编程指南)。Core Foundation的命名约定,特别是“create”这个词的使用,只适用于返回Core Foundation对象的C函数。Objective-C方法的命名约定由Cocoa约定控制,不管该方法返回的是Core Foundation还是Cocoa对象。
创建规则
Core Foundation函数有名称,表明当你拥有一个返回的对象:
- 在名称中嵌入“Create”的对象创建函数;
- 在名称中嵌入“Copy”的对象复制函数。
如果你拥有一个对象,当你完成它时,放弃所有权(使用CFRelease)是你的责任。
考虑以下示例。第一个示例显示了两个与CFTimeZone关联的create函数和一个与CFBundle关联的create函数。
CFTimeZoneRef CFTimeZoneCreateWithTimeIntervalFromGMT (CFAllocatorRef allocator, CFTimeInterval ti);
CFDictionaryRef CFTimeZoneCopyAbbreviationDictionary (void);
CFBundleRef CFBundleCreate (CFAllocatorRef allocator, CFURLRef bundleURL);第一个函数的名称中包含单词“Create”,它创建一个新的CFTimeZone对象。你拥有这个对象,放弃所有权是你的责任。第二个函数在其名称中包含单词“Copy”,并创建一个时区对象属性的副本。(注意,这与获取属性本身不同—请参阅Get规则。)同样,你拥有这个对象,放弃所有权是你的责任。第三个函数CFBundleCreate在其名称中包含“Create”一词,但是文档声明它可能返回一个现有的CFBundle。不过,不管是否创建了新对象,你都拥有这个对象。如果返回一个现有对象,则其retain count将增加,因此你有责任放弃所有权。
下一个示例可能看起来更复杂,但它仍然遵循相同的简单规则。
/* from CFBag.h */
CF_EXPORT CFBagRef CFBagCreate(CFAllocatorRef allocator, const void **values, CFIndex numValues, const CFBagCallBacks *callBacks);
CF_EXPORT CFMutableBagRef CFBagCreateMutableCopy(CFAllocatorRef allocator, CFIndex capacity, CFBagRef bag);CFBag函数CFBagCreateMutableCopy的名称中有“创建”和“复制”两个词。它是一个创建函数,因为函数名包含单词“Create”。还要注意,第一个参数的类型是cfallocatorref——这是一个进一步的提示。该函数中的“Copy”暗示该函数接受CFBagRef参数并生成该对象的副本。它还引用源集合的元素对象发生的变化:它们被复制到新创建的包中。函数名的第二个“Copy”和“NoCopy”子字符串表示如何处理某些源对象拥有的对象——即它们是否被复制。
Get的规则
如果从除创建或复制函数以外的任何Core Foundation函数(例如Get函数)接收对象,则不拥有该对象,并且不能确定对象的生命周期。如果你想确保在使用对象时不会处理这样的对象,你必须声明所有权(使用CFRetain函数)。当你完成后,你有责任放弃所有权。
考虑CFAttributedStringGetString函数,它返回带属性字符串的后端字符串。
CFStringRef CFAttributedStringGetString (CFAttributedStringRef aStr);如果带属性的字符串被释放,它将放弃后台字符串的所有权。如果带属性字符串是后备字符串的唯一所有者,那么后备字符串现在没有所有者,它自己被释放。如果你需要在处理带属性字符串之后访问备份字符串,你必须声明所有权(使用CFRetain)或复制它。然后必须在完成之后放弃所有权(使用CFRelease),否则会造成内存泄漏。
实例变量和传递参数
基本规则的一个推论是,当你将一个对象(作为函数参数)传递给另一个对象时,如果需要维护该对象,则应该期望接收方获得所传递对象的所有权。
要理解这一点,请将你自己置于接收对象的实现者的位置。当函数将对象作为参数接收时,接收者最初并不拥有该对象。因此,该对象可以在任何时候释放,除非接收方拥有if(使用CFRetain)的所有权。当接收方处理完对象时(因为它被替换为一个新值,或者因为接收方本身被释放),接收方负责放弃所有权(使用CFRelease)。
所有权的例子
为了防止运行时错误和内存泄漏,你应该确保在接收、传递或返回Core Foundation对象的地方一致地应用Core Foundation所有权策略。要理解为什么有必要成为未创建对象的所有者,请考虑以下示例。假设你从另一个对象获取一个值。如果值的“包含”对象随后被释放,它将放弃“包含”对象的所有权。如果包含的对象是值的唯一所有者,那么该值没有所有者,并且它也被释放。现在你有了一个对已释放对象的引用,如果你试图使用它,你的应用程序将崩溃。
下面的代码片段演示了三种常见的情况:Set访问器函数、Get访问器函数,以及在满足特定条件之前保持核心Foundation对象的函数。首先Set函数:
static CFStringRef title = NULL;
void SetTitle(CFStringRef newTitle) {
CFStringRef temp = title;
title = CFStringCreateCopy(kCFAllocatorDefault , newTitle);
CFRelease(temp);
}上面的示例使用一个静态CFStringRef变量来保存保留的CFString对象。你可以使用其他方法来存储它,但是你必须将它放在接收函数之外的某个地方。在复制新标题并释放旧标题之前,函数将当前标题分配给局部变量。它在复制之后释放,以防传入的CFString对象与当前持有的对象相同。
请注意,在上面的示例中,对象是复制的,而不是简单地保留。(回忆一下,从所有权的角度来看,这些都是等价的——参见基本原理。)这样做的原因是title属性可能被认为是一个属性。它不应该被改变,除非通过访问器方法。尽管参数的类型是CFStringRef,但可能会传入对CFMutableString对象的引用,这将允许在外部更改该值。因此,你复制对象,以便在你持有它时它不会被更改。如果对象是可变的或可能是可变的,你应该复制该对象,并且需要你自己的惟一版本。如果对象被认为是关系,那么应该保留它。
对应的Get函数更简单:
CFStringRef GetTitle() {
return title;
}通过简单地返回一个对象,你就返回了对它的弱引用。换句话说,指针值被复制到接收者的变量,但是引用计数没有改变。当返回集合中的元素时,也会发生相同的事情。
下面的函数保留从集合中检索到的对象,直到不再需要它,然后释放它。对象被认为是不可变的。
static CFStringRef title = NULL;
void MyFunction(CFDictionary dict, Boolean aFlag) {
if (!title && !aFlag) {
title = (CFStringRef)CFDictionaryGetValue(dict, CFSTR(“title”));
title = CFRetain(title);
}
/* Do something with title here. */
if (aFlag) {
CFRelease(title);
}
}下面的示例显示如何将number对象传递给数组。数组的回调指定保留添加到集合中的对象(集合拥有这些对象),因此可以在将这些对象添加到数组后释放它们。
float myFloat = 10.523987;
CFNumberRef myNumber = CFNumberCreate(kCFAllocatorDefault,
kCFNumberFloatType, &myFloat);
CFMutableArrayRef myArray = CFArrayCreateMutable(kCFAllocatorDefault, 2, &kCFTypeArrayCallBacks);
CFArrayAppendValue(myArray, myNumber);
CFRelease(myNumber);
// code continues...请注意,如果(a)你释放了数组,并且(b)你在释放数组后继续使用number变量,那么这里存在一个潜在的陷阱:
CFRelease(myArray);
CFNumberRef otherNumber = // ... ;
CFComparisonResult comparison = CFNumberCompare(myNumber, otherNumber, NULL);除非你保留了数字或数组,或者将其传递给维护其所有权的其他对象,否则比较函数中的代码将失败。如果没有其他对象拥有这个数组或这个数字,那么当数组被释放时,它也被释放,因此它释放它的内容。在这种情况下,这也会导致数字的释放,因此比较函数将对释放的对象进行操作,从而导致崩溃。
Core Foundation对象生命周期管理
Core Foundation对象的生命周期是由它的引用计数决定的,引用计数是希望对象持久存在的客户机数量的内部计数。在Core Foundation中创建或复制对象时,其引用计数设置为1。后续客户端可以通过调用CFRetain来声明对象的所有权,这会增加引用计数。稍后,当你不再使用该对象时,你将调用CFRelease。当引用计数达到0时,对象的分配程序释放对象的内存。
保留对象引用
若要增加Core Foundation对象的引用计数,请将引用作为CFRetain函数的参数传递给该对象:
/* myString is a CFStringRef received from elsewhere */
myString = (CFStringRef)CFRetain(myString);
释放对象引用
若要减少Core Foundation对象的引用计数,请将引用作为CFRelease函数的参数传递给该对象:
CFRelease(myString);重要提示:你永远不应该直接释放Core Foundation对象(例如,通过在其上调用free)。当你完成一个对象时,调用CFRelease函数,Core Foundation将正确地处理它。
复制对象引用
复制对象时,无论原始对象的引用计数如何,结果对象的引用计数都为1。有关复制对象的更多信息,请参见复制函数。
确定对象的保留计数
如果你想知道一个Core Foundation对象的当前引用计数,传递一个对象的引用作为CFGetRetainCount函数的参数:
CFIndex count = CFGetRetainCount(myString);但是,请注意,除了在调试中,通常不需要确定Core Foundation对象的引用计数。如果你需要知道对象的retain count,请检查是否正确地遵守了所有权策略规则(请参阅所有权策略)。
复制函数
通常,在使用=操作符将一个变量的值赋给另一个变量时,会执行标准的复制操作(也可以称为简单赋值)。例如,表达式myInt2 = myInt1导致将myInt1使用的内存中的整数内容复制到myInt2使用的内存中。复制操作之后,内存的两个独立区域包含相同的值。但是,如果你试图以这种方式复制Core Foundation对象,请注意你不会复制对象本身,只会复制对对象的引用。
例如,新加入Core Foundation的人可能认为,要复制CFString对象,可以使用表达式myCFString2 = myCFString1。同样,这个表达式实际上并不复制字符串数据。因为myCFString1和myCFString2都必须具有CFStringRef类型,所以该表达式只将引用复制到对象。复制操作之后,你有两个对CFString的引用副本。这种类型的复制非常快,因为只有引用是复制的,但重要的是要记住,以这种方式复制可变对象是危险的。与使用全局变量的程序一样,如果应用程序的某个部分使用引用的副本更改了对象,则程序的其他部分(具有该引用的副本)无法知道数据已更改。
如果你想复制一个对象,你必须使用Core Foundation专门为此目的提供的函数之一。继续使用CFString示例,你将使用CFStringCreateCopy创建一个全新的CFString对象,该对象包含与原始对象相同的数据。具有“CreateCopy”函数的Core Foundation类型还提供了“CreateMutableCopy”变量,该变量返回一个可以修改的对象的副本。
浅拷贝
复制复合对象(比如可以包含其他对象的集合对象)时也必须小心。正如你所期望的那样,使用=操作符在这些对象上执行副本会导致对象引用的重复。与CFString和CFData等简单对象相比,为CFArray和CFSet等复合对象提供的“CreateCopy”函数实际上执行的是浅拷贝。对于这些对象,浅拷贝意味着创建一个新的集合对象,但是原始集合的内容不是复制的——只有对象引用被复制到新的容器中。这种类型的复制非常有用,例如,如果你有一个不可变的数组,并且希望对其重新排序。在这种情况下,你不希望复制所有包含的对象,因为不需要更改它们—为什么要使用额外的内存呢?你只想要更改所包含的对象集。这里的风险与复制具有简单类型的对象引用的风险相同。
深拷贝
当你想要创建一个全新的复合对象时,必须执行深度复制。深度复制复制复合对象及其所有包含对象的内容。当前版本的Core Foundation包含了一个功能,可以对属性列表进行深度复制(参见CFPropertyListCreateDeepCopy)。如果你想创建其他结构的深度副本,你可以自己执行深度副本,方法是递归降序到复合对象中,并逐个复制其所有内容。在实现这个功能时要小心,因为复合对象可以是递归的——它们可以直接或间接地包含对它们自身的引用——这可能会导致递归循环。
字节次序
微处理器体系结构通常使用两种不同的方法在内存中存储多字节数字数据的单个字节。这种差异称为“字节顺序”或“端部性质”。“大多数时候,你的电脑的尾端格式可以被安全地忽略,但在某些情况下,它变得至关重要。OS X提供了多种函数来将一种字节序的数据转换成另一种字节序。
Intel x86处理器存储的是一个双字节整数,最不重要的字节放在前面,最重要的字节放在后面。这称为小端字节排序。其他CPU,例如PowerPC CPU,存储的是一个双字节整数,其中最重要的字节放在前面,最不重要的字节放在后面。这称为大端字节排序。大多数情况下,你的电脑的尾端格式是可以安全忽略的,但在某些情况下,它变得至关重要。例如,如果你试图从与你的端部性质不同的计算机上创建的文件中读取数据,字节顺序的差异可能会产生错误的结果。从网络读取数据时也会出现同样的问题。
术语:大端big-endian和小端little-endian这两个术语来自于乔纳森·斯威夫特18世纪的讽刺作品《格列佛游记》。不来夫斯古帝国的臣民分为两派:一派从大的一端开始吃鸡蛋,另一派从小的一端开始吃鸡蛋。
为了给出一个具体的例子来讨论端点格式问题,考虑一个简单的C结构,它定义了两个4字节的整数,如清单1所示。
清单1示例数据结构
struct {
UInt32 int1;
UInt32 int2;
} aStruct;假设清单2中所示的代码用于初始化清单1中所示的结构。
清单2初始化示例结构
ExampleStruct aStruct;
aStruct.int1 = 0x01020304;
aStruct.int2 = 0x05060708;考虑图1中的关系图,它显示了大端处理器或内存系统如何组织示例数据。在big-endian系统中,物理内存是按照每个字节的地址从最重要的字节增加到最不重要的字节来组织的。
图1 big-endian格式的示例数据
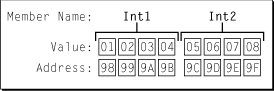
请注意,字段存储在左侧的重要字节较多,右侧的重要字节较少。这意味着地址字段Int1的最有效字节的地址是0x98,而地址0x9B对应的是Int1的最低有效字节。
图2中的关系图显示了little-endian系统如何组织数据。
图2 little-endian格式的示例数据
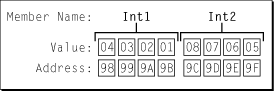
注意,每个字段的最低地址现在对应的是最低有效字节,而不是最高有效字节。如果要在小端系统上打印Int1的值,你将看到,尽管存储的字节顺序不同,但它仍然被正确地解释为十进制值16909060。
现在假设清单2所示的代码初始化的示例数据值是在little-endian系统上生成并保存到磁盘上的。假设数据按字节地址顺序写入磁盘。当big-endian系统从磁盘读取数据时,数据将再次被放置在内存中,如图2所示。问题是数据仍然是按小端字节顺序排列的,即使它是在一个大端字节系统中解释的。这种差异导致值的计算不正确。在本例中,Int1字段的十进制值应该是16909060,但是由于字节顺序不正确,其值应该是67305985。这种现象称为字节交换,当使用另一种尾数格式的系统读取一种尾数格式的数据时发生这种现象。
不幸的是,这是一个在一般情况下无法解决的问题。原因是交换的方式取决于数据的格式。字符串通常不被交换,长单词被交换4个字节,单词被交换2个字节。因此,需要交换数据的任何程序都必须知道数据类型、源数据的顺序和主机的顺序。
CFByteOrder.h中的函数允许你在两个字节和四个字节的整数以及浮点值上执行字节交换。适当地使用这些函数可以帮助你确保你的程序操作的数据的顺序是正确的。有关使用这些函数的详细信息,请参阅“字节交换”一节。注意Core Foundation的字节交换功能只能在OS X上使用。
在创建函数中使用分配器
每个Core Foundation不透明类型都有一个或多个创建函数,这些函数创建并返回以特定方式初始化的该类型的对象。所有创建函数的第一个参数都是对分配器对象(CFAllocatorRef)的引用。一些函数还可能有一些分配器参数,用于专门的分配和重新分配。
你有几个选项为分配器引用参数:
- 可以传递常量kCFAllocatorSystemDefault;这指定了通用系统分配器(它是初始默认分配器)。
- 可以传递NULL来指定当前的默认分配器(可能是自定义分配器或通用系统分配器)。这与传递kCFAllocatorDefault相同。
- 你可以传递常量kCFAllocatorNull,该常量指示没有分配的分配器—尝试使用它是一个错误。一些创建函数具有用于重新分配或释放后备存储的特殊分配器的参数;通过为参数指定kCFAllocatorNull,可以防止自动重新分配或重新分配。
- 你可以使用CFGetAllocator函数获得另一个Core Foundation对象使用的分配器的引用,并将该引用传递进来。这种技术允许你通过使用相同的分配器来分配相关对象,从而将它们放到内存“区域”中。
- 可以将引用传递给自定义分配器(请参阅创建自定义分配器)。
如果要使用自定义分配器,并且希望将其设置为默认分配器,建议首先使用CFAllocatorGetDefault函数获取对当前默认分配器的引用,并将其存储在本地变量中。使用完自定义分配器后,使用CFAllocatorSetDefault函数将存储的分配器重置为默认分配器。
使用分配器上下文
Core Foundation中的每个分配器都有一个上下文。上下文是定义对象操作环境的结构,通常由函数指针组成。分配器的上下文由CFAllocatorContext结构定义。除了函数指针之外,该结构还包含版本号和用户定义数据的字段
清单1是CFAllocatorContext结构
typedef struct {
CFIndex version;
void * info;
const void *(*retain)(const void *info);
void (*release)(const void *info);
CFStringRef (*copyDescription)(const void *info);
void * (*allocate)(CFIndex size, CFOptionFlags hint, void *info);
void * (*reallocate)(void *ptr, CFIndex newsize, CFOptionFlags hint, void *info);
void (*deallocate)(void *ptr, void *info);
CFIndex (*preferredSize)(CFIndex size, CFOptionFlags hint, void *info);
} CFAllocatorContext;info字段包含分配程序的任何特殊定义的数据。例如,分配器可以使用info字段来跟踪未完成的分配。
重要提示:对于当前版本,不要将version字段的值设置为0以外的任何值。
如果在分配器上下文中有一些用户定义的数据(info字段),那么使用CFAllocatorGetContext函数来获得分配器的CFAllocatorContext结构。然后根据需要评估或处理数据。下面的代码提供了一个例子:
清单2获取分配器上下文和用户定义的数据
static int numOutstandingAllocations(CFAllocatorRef alloc) {
CFAllocatorContext context;
context.version = 0;
CFAllocatorGetContext(alloc, &context);
return (*(int *)(context.info));
}其他Core Foundation函数调用在分配器上下文中定义的与内存相关的回调,并获取或返回指向内存块的无类型指针(void *):
CFAllocatorAllocate,分配一块内存。
CFAllocatorReallocate重新分配内存块。
CFAllocatorDeallocate分配一个内存块。
CFAllocatorGetPreferredSizeForSize给出给定请求可能分配的内存大小。
创建自定义的分配器
要创建自定义分配器,首先声明并初始化一个CFAllocatorContext类型的结构。将版本字段初始化为0,并将任何需要的数据(如控制信息)分配给info字段。这个结构的其他字段是下面实现分配器回调时描述的函数指针。
一旦为CFAllocatorContext结构的字段分配了适当的值,就可以调用CFAllocatorCreate函数来创建分配器对象。这个函数的第二个参数是指向结构的指针。此函数的第一个参数标识用于为新对象分配内存的分配器。如果你希望在CFAllocateContext结构中为此使用分配回调,请为第一个参数指定kCFAllocatorUseContext常量。如果希望使用默认分配器,请在此参数中指定NULL。
清单1创建自定义分配器
static CFAllocatorRef myAllocator(void) {
static CFAllocatorRef allocator = NULL;
if (!allocator) {
CFAllocatorContext context =
{0, NULL, NULL, (void *)free, NULL,
myAlloc, myRealloc, myDealloc, NULL};
context.info = malloc(sizeof(int));
allocator = CFAllocatorCreate(NULL, &context);
}
return allocator;
}
分配器实现回调函数
CFAllocatorContext结构有七个定义回调函数的字段。如果创建自定义分配器,则必须至少实现分配函数。分配器回调应该是线程安全的,如果回调调用其他函数,它们也应该是可重入的。
retain、release和copy-description回调都将CFAllocatorContext结构的info字段作为它们的单个参数。该字段的类型为void *,指向为分配器定义的任何数据,例如包含控制信息的结构。
保留回调:
const void *(*retain)(const void *info);
在info中保留为分配器上下文定义的数据。这可能只有在数据是Core Foundation对象时才有意义。你可以将此函数指针设置为空。
释放回调:
void (*release)(const void *info);释放(或释放)为分配器上下文定义的数据。你可以将这个函数指针设置为NULL,但是这样做可能会导致内存泄漏。
复制描述回调:
CFStringRef (*copyDescription)(const void *info);返回对CFString的引用,该引用描述了你的分配器,特别是用户定义数据的某些特征。你可以将这个函数指针设置为NULL,在这种情况下Core Foundation将提供一个基本的描述。
配置回调:
void * (*allocate)(CFIndex size, CFOptionFlags hint, void *info);分配至少大小为字节的内存块,并返回指向该块开始的指针。提示参数是一个位字段,你目前不应该使用它。size参数应该总是大于0。如果不是,或者出现分配问题,则返回NULL。此回调可能不为空。
重新分配回调:
void * (*reallocate)(void *ptr, CFIndex newsize, CFOptionFlags hint, void *info);将ptr指向的内存块大小更改为newsize指定的大小,并返回指向较大内存块的指针。在任何重新分配失败时返回NULL,保持旧的内存块不变。注意,ptr参数永远不会为空,newsize总是大于0——除非满足这两个条件,否则不使用此回调。
保持旧内存块的内容不变,直到新大小或旧大小中较小的那个。如果ptr参数不是先前由分配器分配的内存块,则结果是未定义的;程序可能会异常终止。提示参数是一个位字段,你目前不应该使用它。如果将此回调设置为NULL,则CFAllocatorReallocate函数在尝试使用此分配器时,在大多数情况下都会返回NULL。
释放回调:
void (*deallocate)(void *ptr, void *info);使ptr指向的内存块可以供分配器后续重用,但不能供程序继续使用。ptr参数不能为空,如果ptr参数不是先前由分配器分配的内存块,则结果未定义;程序可能会异常终止。你可以将这个回调设置为NULL,在这种情况下,CFAllocatorDeallocate函数没有作用。
首选大小回调:
CFIndex (*preferredSize)(CFIndex size, CFOptionFlags hint, void *info);返回实际大小的分配器可能分配给定请求的内存块大小大小。提示参数是一个位字段,你目前不应该使用它。
字节交换
如果需要找出主机字节顺序,可以使用函数CFByteOrderGetCurrent。可能的返回值是CFByteOrderUnknown、CFByteOrderLittleEndian和CFByteOrderBigEndian。
字节交换整数
Core Foundation为字节交换提供了三个优化的原语函数——CFSwapInt16、CFSwapInt32和CFSwapInt64。所有其他交换函数都使用这些原语来完成它们的工作。通常,你不需要直接使用这些原语。
虽然原语交换函数是无条件交换的,但是高级交换函数的定义方式是,当不需要字节交换时(换句话说,当源和主机字节顺序相同时),它们什么也不做。对于整数类型,这些函数采用CFSwapXXXBigToHost和CFSwapXXXLittleToHost、CFSwapXXXHostToBig和CFSwapXXXHostToLittle的形式,其中XXX是Int32这样的数据类型。例如,如果你在一台小端端计算机上,从一个数据按网络字节顺序(big-endian)的网络读取一个16位整数值,那么你将使用函数CFSwapInt16BigToHost。清单1演示了这个过程。
清单1交换16位整数
SInt16 bigEndian16;
SInt16 swapped16;
// Swap a 16 bit value read from network.
swapped16 = CFSwapInt16BigToHost(bigEndian16);节字节排序介绍了一个简单C结构的示例,该结构被创建并保存到一个小端机的磁盘上,然后从一个大端机的磁盘上读取数据。为了纠正这种情况,必须交换每个字段中的字节。清单2中的代码演示了如何使用Core Foundation的字节交换函数来实现这一点。
清单2是C结构中的字节交换字段
// Byte swap the values if necessary.
aStruct.int1 = CFSwapInt32LittleToHost(aStruct.int1)
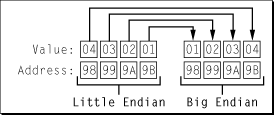
aStruct.int2 = CFSwapInt32LittleToHost(aStruct.int2)假设采用big-endian架构,清单2中使用的函数将交换每个字段中的字节。图1显示了字节交换对字段aStruct.int1的影响。注意,字节交换代码在小端机器上运行时什么也不做。编译器应该优化代码并保持数据不变。
图1四字节小端到大端交换
字节交换浮点值
即使在单一平台上,浮点值也可以有许多不同的表示形式。除非你非常小心,否则试图在平台边界之间传递浮点值会导致无休止的麻烦。为了帮助你处理浮点数,Core Foundation除了整数交换函数外,还定义了一组函数和两种特殊的数据类型。这些函数允许你对32位和64位浮点值进行编码,以便以后可以对它们进行解码,并在必要时交换字节。清单3展示了如何编码64位浮点数,清单4展示了如何解码它。
清单3对浮点值进行了编码
Float64 myFloat64;
CFSwappedFloat64 swappedFloat;
// Encode the floating-point value.
swappedFloat = CFConvertFloat64HostToSwapped(myFloat64);清单4对浮点值进行解码
Float64 myFloat64;
CFSwappedFloat64 swappedFloat;
// Decode the floating-point value.
myFloat64 = CFConvertFloat64SwappedToHost(swappedFloat);数据类型CFSwappedFloat32和CFSwappedFloat64在规范表示中包含浮点值。CFSwappedFloat本身不是一个浮点数,不应该直接作为一个浮点数使用。但是,你可以将一个进程发送到另一个进程,将其保存到磁盘,或者通过网络发送。因为格式是通过转换函数转换成规范格式的,所以不需要显式的交换API。如果需要,在格式转换期间会为你处理字节交换。
评论前必须登录!
注册