 srcmini
srcmini下面列出了最常见的DataStage面试问题和答案。
1)什么是IBM DataStage?
DataStage是功能最强大的ETL工具之一。它具有用于数据集成的图形化可视化功能。它从源提取, 转换并将数据加载到目标。
DataStage是用于设计, 开发, 运行, 编译和管理应用程序的一组集成工具。它可以从一个或多个数据源中提取数据, 实现数据的多部分转换, 并使用结果数据加载一个或多个目标文件或数据库。
2)描述DataStage的体系结构?
DataStage遵循客户端-服务器模型。对于不同版本的DataStage, 它具有不同类型的客户端-服务器体系结构。
DataStage体系结构包含以下组件。
- 专案
- 工作
- 阶段
- 伺服器
- 客户端组件
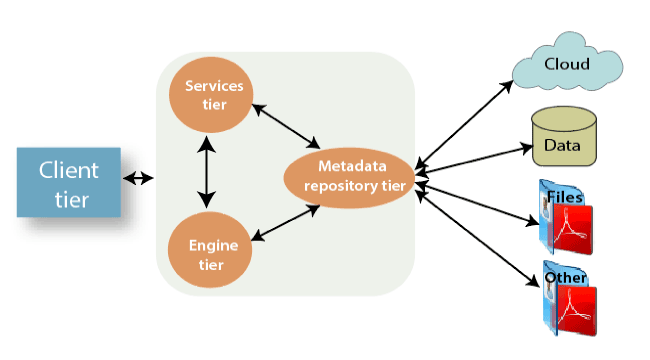
3)解释DataStage并行扩展器(PX)或企业版(EE)?
DataStage PX是IBM数据集成工具。它是数据仓库行业中使用最广泛的提取, 转换和加载(ETL)工具之一。该工具从各种来源收集信息, 以根据业务需求执行转换并将数据加载到相应的数据仓库中。
DataStage PX也称为DataStage企业版。
4)描述DataStage的主要功能?
DataStage的主要功能如下。
- DataStage提供了分区和并行处理技术, 这些技术使DataStage作业可以更快地处理大量数据。
- 它具有企业级网络。
- 它是IBM InfoSphere Information Server的数据集成组件。
- 这是一个基于GUI的工具。
- 在DataStage中, 我们需要拖放DataStage对象, 也可以将其转换为DataStage代码。
- DataStage用于执行各种ETL操作(提取, 转换, 加载)
- 它同时提供与不同来源和多个目标的连接
5)DataStage有哪些先决条件?
对于DataStage, 必须进行以下设置。
- InfoSphere
- DataStage Server 9.1.2或更高版本
- Microsoft Visual Studio .NET 2010 Express Edition C ++
- Oracle客户端(完整客户端, 不是即时客户端)(如果连接到Oracle数据库)
- DB2客户端(如果连接到DB2数据库)
6)如果文件具有相同的元数据, 如何使用单个DataStage作业读取多个文件?
- 搜索文件的元数据是否不同或相同, 然后在顺序阶段指定文件名。
- 在元数据的属性中按顺序附加该元数据。
- 选择”读取方法”作为”特定文件”, 然后通过从”要添加的可用属性”中选择”文件”属性来添加所有文件。
它看起来像:
File= /home/myFile1.txt
File= /home/myFile2.txt
File= /home/myFile3.txt
Read Method= Specific file(s) fcec7)解释IBM InfoSphere Information Server并突出其主要功能?
IBM InfoSphere Information Server是领先的数据集成平台, 其中包含使你能够理解, 过滤, 监视, 转换和交付数据的一组产品。可扩展的解决方案具有大规模并行处理功能, 可帮助你管理海量数据。它可帮助你将可靠的信息转发到你的关键业务目标, 例如大数据和分析, 数据仓库现代化以及主数据管理。
IBM InfoSphere Information Server的功能
- IBM InfoSphere可以连接多个源系统, 并可以写入各种目标系统。它充当数据集成的单个平台。
- 它基于集中层。套装的所有模块都可以共享套件的基准架构。
- 它具有用于统一存储库, 集成元数据服务以及共享并行引擎的一些附加层。
- 它具有用于分析, 监视, 清理, 转换和传递数据的工具。
- 它具有极高的并行处理能力, 可提供高速处理。
8)什么是IBM DataStage Flow Designer?
IBM DataStage Flow Designer允许你在DataStage中创建, 编辑, 装入和运行作业。 DFD是DataStage的基于Web的瘦客户端版本。它是DataStage的基于Web的UI, 而不是DataStage Designer, 后者是基于Window的胖客户端。
9)如何从命令行运行DataStage作业?
要运行DataStage作业, 请使用命令” dsjob”命令, 如下所示。
'dsjob -run -jobstatus projectname jobname10)与” dsjob”相关的其他一些替代命令是什么?
许多替代的可选命令可以与dsjob命令一起使用以执行任何特定任务。这些命令以以下格式使用。
$dsjob -run alternative command下面列出了dsjob命令的常用替代选项。
停止:用于停止正在运行的作业
Lprojects:用于列出项目
ljobs:用于列出项目中的作业
lparams:用于列出作业中的参数
paraminfo:返回参数信息
Linkinfo:返回链接信息
Logdetail:用于显示详细信息, 例如event_id, 时间和消息
Lognewest:用于显示最新的日志ID。
日志:用于添加短信进行日志记录。
Logsum:用于显示日志。
lstages:用于列出作业中存在的阶段。
Llinks:用于列出链接。
Projectinfo:返回项目信息(主机名和项目名称)
Jobinfo:返回作业信息(作业状态, 作业运行时间, 结束时间等)
Stageinfo:它返回阶段名称, 阶段类型, 输入行等)
报告:用于显示包含生成时间, 开始时间, 经过时间, 状态等的报告。
Jobid:用于提供Job ID信息。
11)什么是DataStage工具的质量阶段?
质量阶段有助于整合来自多个来源的不同类型的数据。
它也被称为完整性阶段。
12)在DataStage中杀死工作的过程是什么?
要取消工作, 你必须销毁特定的处理ID。
13)什么是DS设计器?
DataStage Designer用于设计作业。它还开发了工作区域并为其添加了各种链接。
14)DataStage的阶段是什么?
阶段是InfoSphere DataStage中的基本结构块。它提供了丰富, 独特的功能集, 可以执行高级或直接的数据集成任务。阶段保留并表示将对数据执行的处理步骤。
15)什么是DataStage中的运算符?
并行作业阶段由操作员完成。一个阶段可能属于一个操作员或多个操作员。运算符的数量取决于你设置的属性。在编译期间, InfoSphere DataStage会估算你的工作设计, 有时还会优化操作员。
16)解释DataStage与DataSources之间的连接性吗?
IBM InfoSphere Information Server支持连接器并启用作业, 以在InfoSphere Information Server和数据源之间进行数据传输。
IBM InfoSphere DataStage和QualityStage作业可以访问来自企业应用程序和数据源的数据, 例如:
- 关系数据库
- 大型机数据库
- 企业资源计划(ERP)或客户关系管理(CRM)数据库
- 在线分析处理(OLAP)或绩效管理数据库
- 业务和分析应用程序
17)描述流连接器?
流连接器允许在流和DataStage之间进行集成。 InfoSphere Stream连接器用于将数据从DataStage作业发送到Stream作业, 反之亦然。
InfoSphere Streams可以与将数据加载到数据仓库中并行地执行接近实时的分析处理。或者, InfoSphere Streams作业执行RTAP处理。经过RTAP处理后, 它将数据转发到InfoSphere DataStage以转换, 丰富和存储详细信息以用于存档。
18)在DataStage的Transformer阶段, HoursFromTime()函数有什么用?
HoursFromTime函数用于返回时间的小时部分。它的输入是时间, 输出是小时(int8)。
示例:如果myexample1.time包含时间22:30:00, 则以下两个函数等效, 并返回整数值22。
HoursFromTime(myexample1.time)
HoursFromTime("22:30:00")19)Informatica和DataStage有什么区别?
DataStage和Informatica都是强大的ETL工具。两种工具以几乎相同的方式完成几乎相同的工作。在这两种工具中, 性能, 可维护性和学习曲线都是相似且可比的。以下是这两种工具之间的一些区别。
| Parameter | DataStage | Informatica |
|---|---|---|
| DataStage的管道分区使用多个分区。 | Informatica提供了作为动态分区的分区。 | |
| DataStage提供3个GUI IBM DataStage Designer作业序列设计器(工作流程设计)Director(用于监视) | Informatica提供4个GUI Informatica PowerDesigner存储库管理器工作流设计器工作流管理器。 | |
| 在到达DataStage Server之前, 需要进行数据加密。 | Informatica允许在PowerCenter Designer中进行”数据屏蔽转换”作为单独的转换。 | |
| 通过使用函数(Oconv和IConv)和例程, DataStage成为强大的转换引擎。它提供了大约40个数据转换阶段/对象。几乎所有的转换都可以在DataStage中执行。 | Informatica允许进行大约30次必要的转换以处理传入的数据。 | |
| 通过使用容器(本地和共享), 我们可以在DataStage中实现作业的可重用性。要重新使用作业序列, 你将必须进行复制, 编译并运行。 | 它提供了通过Mapplet和Worklets进行重用的访问, 以重用映射和工作流。可重用性提高了性能。 |
20)我们如何将服务器作业转换为并行作业?
我们可以使用Link Collector和IPC Collector将服务器作业转换为并行作业。
21)信息服务器体系结构中有哪些不同层?
信息服务器体系结构的不同层如下。
- 统一的用户界面
- 共同服务
- 统一并行处理
- 统一元数据
- 通用连接
22)如果你想在不同的工作中使用同一段代码, 你将如何实现?
DataStage具有称为共享容器的功能, 该功能允许为不同的工作共享同一段代码。共享容器是为了可重用。共享容器由阶段和链接的可重用作业元素组成。与DataStage作业不同, 我们可以在其中调用共享容器。
23)DataStage有多少种排序方法可用?
DataStage中有两种类型的排序方法可用于并行作业。
- 链接排序
- 独立排序阶段
24)描述链接排序?
链接排序比其他排序支持较少的选项。在DataStage作业中, 维护很容易, 因为DataStage作业画布中只有几个阶段。
除非在”排序阶段”上需要特定选项, 否则将使用链接排序。通常, “排序”阶段用于为部分排序指定”排序键”模式。
输入/分区阶段选项上提供了”按链接排序”选项。如果使用自动分区方法, 则无法指定键控分区。
25)哪些命令用于导入和导出DataStage作业?
对于给定的操作, 我们使用以下命令。
对于导入:我们使用dsimport.exe命令
对于导出, 我们使用dsexport.exe命令
26)描述DataStage中的例程吗?征集各种类型的例程。
例行程序是DS管理器定义的一组任务。它通过变压器阶段运行。
有三种例程
- 并行例程
- 大型机例程
- 服务器例程
27)DataStage中有哪些不同类型的作业?
DataStage有两种类型的作业
- 服务器作业:这些作业按顺序运行
- 并行作业:这些作业以并行方式执行
28)陈述Operational DataStage和数据仓库之间的区别?
可以将Operational DataStage视为用户处理和实时分析的演示区域。因此, 可操作的DataStage是一个临时存储库。数据仓库用于满足持久数据存储需求, 并可以存储整个业务的完整数据。
29)异常活动在DataStage中的重要性是什么?
异常活动之所以重要, 是因为在作业执行期间, 异常活动会处理所有不熟悉的错误活动。
30)什么是”致命错误/ RDBMS代码3996″错误?
在Teradata 13到14升级期间测试DataStage 8.5中的作业时, 会发生此错误。
这是因为用户试图将较长的字符串分配给较短的字符串目标, 有时是因为RANGE_N函数中一个或多个范围边界的长度是长度大于测试值的字符串文字。
| 工作/人力资源面试问题 |
| jQuery面试问题 |
| Java OOP面试问题 |
| JSP面试问题 |
| 休眠面试问题 |
| SQL面试题 |
| Android面试题 |
| MySQL面试问题 |
多个分区
用户界面
数据加密
转换_
可重用性
面试技巧
JavaScript面试问题
Java基础面试问题
Servlet面试问题
春季面试问题
PL / SQL面试问题
Oracle面试问题
SQL Server面试问题
评论前必须登录!
注册