 srcmini
srcmini本文概述
- 应用函数作为循环的替代方法
- 内容
- apply()族类
- 如何在R中使用apply()
- lapply()函数
- sapply()函数
- rep()函数
- mapply()函数
- 与apply()相关的函数
- 集合的一个例子
- 向量化是循环和应用函数的替代选择?
应用函数作为循环的替代方法
这篇文章将向你展示如何使用R apply()函数, 它的变体(例如mapply()以及一些apply()的亲戚)应用于不同的数据结构。当然, 并不是所有的变体都可以讨论, 但是在可能的情况下, 将通过几个更强大的示例向你介绍如何协同使用这些功能。
同样, 你可能会发现查看R教程的本章很有用, 以更好地理解列表, 向量, 数组和数据框, 尽管你并不一定要完成本教程才能关注本文。
内容
- apply()族类
- apply()函数
- lapply()函数
- sapply()函数
- rep()函数
- mapply()函数
- 与apply()相关的函数
- Sweep()函数
- Aggregate()函数
- 集合的一个例子
- 向量化是循环和应用函数的替代选择?
apply()族类
apply()系列属于R基本包, 并填充有以重复方式处理矩阵, 数组, 列表和数据帧中的数据切片的函数。这些函数允许以多种方式交叉数据, 并避免显式使用循环结构。它们作用于输入列表, 矩阵或数组, 并应用具有一个或几个可选参数的命名函数。
调用的函数可以是:
- 聚合函数, 例如均值或总和(返回数字或标量);
- 其他转换或子集功能;和
- 其他向量化函数, 可产生更复杂的结构, 如列表, 向量, 矩阵和数组。
apply()函数构成了更复杂的组合的基础, 并有助于以很少的代码行执行操作。更具体地说, 该族由apply(), lapply(), sapply(), vapply(), mapply(), rapply()和tapply()函数组成。
但是我们应该如何以及何时使用这些?
好吧, 这取决于你要操作的数据的结构以及所需的输出格式。
如何在R中使用apply()
让我们从家族的教父开始, apply()在数组上运行。为简单起见, 本教程将自身限制为2D数组, 也称为矩阵。
R基本手册告诉你它的名称如下:apply(X, MARGIN, FUN, …)
哪里:
- 如果数组的维数为2, 则X为数组或矩阵。
- MARGIN是定义函数应用方式的变量:当MARGIN = 1时, 它适用于行, 而MARGIN = 2时, 则适用于列。注意, 当你使用构造MARGIN = c(1, 2)时, 它适用于行和列;和
- FUN, 这是你要应用于数据的功能。它可以是任何R函数, 包括用户定义函数(UDF)。
现在, 初学者可能难以想象发生的事情, 因此可以使用图片和一些代码来帮助你解决问题。
让我们构造一个5 x 6的矩阵, 并假设你想对每一列的值求和。
你可以这样写:
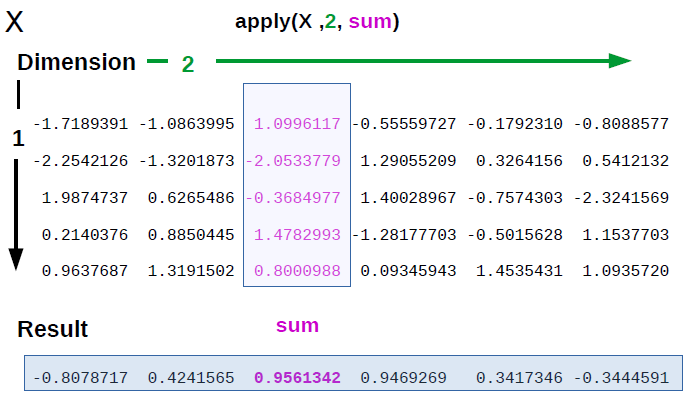
请记住, 在R中, 当你从上到下穿过矩阵时(沿着垂直线1(指定尺寸或边距1)), 矩阵可以看作是线向量的集合, 或者可以看作列向量的列表, 跨越沿着尺寸或边距从左到右的矩阵2。
这意味着你刚刚输入的指令(如图1所示)转换为:将函数”求和”沿边距2(按列)应用于矩阵X, 对每列的值求和。
请注意, 为避免图片混乱, 仅突出显示其中一列。
你最终得到一个包含每一列值之和的线向量。
如果沿矩阵的线求和, 也将给出上述代码的输出(线向量)。这就是R显示结果的方式。
请注意以下几点:在大多数情况下, R可以返回一个值, 即使未指定后者, 或更准确地说, 该函数的返回值尚未分配给变量。 R只是返回最后一个求值的对象。但是, 实际上, 当你要检查返回值并且需要对这些返回值进行进一步操作时, 最好将给定函数的结果显式分配给变量。
lapply()函数
你想将给定函数应用于列表的每个元素, 并获得一个列表作为结果。当执行?lapply时, 你会看到语法类似于apply()函数。
区别在于:
- 它可以用于其他对象, 例如数据帧, 列表或向量。和
- 返回的输出是一个列表(说明函数名称中的” l”), 该列表具有与传递给它的对象相同数量的元素。
要查看其工作原理, 请创建一些矩阵并从每个给定列中提取。
当对不同数据帧进行比较或汇总时, 这是对真实数据执行的非常常见的操作。
我们的玩具示例, 如图2所示, 可以编码为:

该操作如图2的左侧所示。
同样, 从指定目标对象列表Mylist开始。你使用标准的R选择运算符[, 然后省略第一个参数(因此将其转换为” any”, 这就是为什么看到两个逗号的原因)。
接下来, 你指定第二个参数, 即2:我们的保证金是” column”。因此, 你可以从列表中的所有矩阵中提取第二列。
上面代码的一些注释:
- [表示法是选择运算符。请记住, 例如, 要提取B第三行的所有元素, 需要:B [3, ];
- [[]]表示我们正在处理列表的事实:[[2]]表示列表的第二个元素。 R给出的输出也显示了这一点;
- 输出是一个包含与输入中的元素一样多的元素的列表。和
- 请注意, 你还可以为每个矩阵提取单个元素, 如下所示:lapply(MyList, ” [“, 1, 2)
在图2的右侧, 你可以看到另一种提取:这次你省略了第一个参数, 并且从每个矩阵中获得了第一行。
自己尝试!从列表中的每个矩阵中选择第二列:
sapply()函数
sapply()函数的工作方式与lapply()相似, 但是它试图将输出简化为可能的最基本的数据结构。实际上, sapply()是lapply()的”包装器”函数。
一个例子可能有助于理解这一点:假设你想像上一个例子一样重复单个元素的提取操作, 但是现在为每个矩阵采用第二行的第一个元素(索引2和1)。
应用lapply()函数会给我们一个列表, 除非你将simple = FALSE作为参数传递给sapply()。然后, 将返回一个列表。在下面的代码块中查看其工作方式:
相反, 像unlist()这样的函数可以告诉lappy()给你一个向量!
无论如何, 为避免混淆, 最好以”本机格式”使用这些功能, 除非绝对必要, 否则请避免进行转换。
rep()函数
rep()通常与apply()函数一起使用。将其应用于向量或因子x时, 该函数将其值复制指定的次数。
让我们将上面通过lapply()生成的向量之一用于MyList。
但是, 这一次, 你仅从列表MyList的每个元素中选择第一行和第一列的元素(并且使用sapply()获取向量):
你会看到上面的代码将c的值复制c的次数为c(3, 1, 2):多次, 一次, 第二次, 第三次:
方便吗?
mapply()函数
mapply()函数代表”多变量”应用。其目的是能够将参数向量化为通常不接受向量作为参数的函数。
简而言之, mapply()将函数应用于多个列表或多个向量参数。
让我们看一个mapply()示例, 其中创建一个4 x 4矩阵, 并重复调用rep()函数:
但是你会发现有一种更有效的方法来绑定rep()函数的结果, 而不是使用c():绑定mapply()时, 可以对rep()函数的操作进行矢量化处理。
与apply()相关的函数
同样, 结构化函数有时会与apply()系列的元素结合使用:本教程仅概述其中一些。
Sweep()函数
函数sweep()可能是最接近apply()系列的函数。当你要对所选的MARGIN元素复制不同的操作时(在此仅限于矩阵形式), 可以使用它。
典型情况是在群集中发生的, 你可能需要重复生成标准化和居中或”标准化”的数据。
这是什么意思?
假设一组数据中有许多数据点。首先, 你要找到数据的中心(“质心”), 并查看该数据相对于该中心的分散程度。两个基本量将为你提供此信息:平均值和标准偏差。
假设你的数据点是数据矩阵中的列向量, 让我们使用本文开头创建的矩阵B, 但现在你将其称为dataPoints。
你首先借助apply()函数之一找到每列的均值以及离散度或标准差。然后, 将所有点相对于它们的中心移动。这意味着你首先发现的平均值将用于相对于其标准偏差对数据进行归一化:
你只需调用一次sweep()便产生了中心点。该函数需要以下元素:
- 输入数组, 在这种情况下是矩阵;
- MARGIN, 2表示列;
- 汇总统计(此处是指);和
- 要应用的功能。使用算术运算符”-“进行减法。
这意味着:”获取数据集MyPoints的列的元素, 并从每个元素中减去均值dataPoints_means”。
现在, 再次调用sweep()将刚找到的所有值除以它们自己的标准偏差。此步骤称为”规范化”。再次, 选择MARGIN = 2, 然后提供标准差的向量dataPoints_sdev作为操作数。接下来, 你传递”除以”运算符” /”。
你对R的要求如下:”获取刚创建的新对象的列的元素dataPoints_Trans1, 然后将它们(” /”)除以它们的标准偏差dataPoints_sdev。
当然, 你可以更快速, 更简明地获得相同的结果(在R!中经常如此), 而无需使用不同的名称, 只需一行代码包含对sweep()的嵌套调用即可:
从统计上讲, 你刚刚创建了一个相关矩阵, 并且标准化数据是基于几个更高级的数据处理程序(例如, 通过PCA进行的维数减少, 信号分析等)的基础。
Aggregate()函数
此函数包含在stats包中, 你可以像这样使用它:aggregate(x, by, FUN, …, simple = TRUE)。
换句话说, 它的作用类似于apply()函数:指定对象, 函数并说出是否要简化, 就像使用sapply()函数一样。关键的区别是使用by子句, 该子句设置了我们要用来执行聚合的变量或数据框字段。
下一节将向你展示其工作原理。
集合的一个例子
考虑一个名为Mydf的玩具数据集, 其中包含有关产品销售以及变量DepPC列的某些值重复的数据。
此变量对地理位置上的数据进行分类, 例如邮政编码的一部分(此处的数字对应于法兰西岛的部门, 即巴黎所在的地区)。
你要在销售列中进行一些统计。这些是DProgr, 按时间顺序递增的渐进数字, 产品的销售量(数量Qty)以及一个逻辑变量Delivered, 该逻辑变量逻辑上告诉我们产品是否已交付(T)(F) )。
首先, 除了显示全部内容外, 你还可以做很多非常简单的事情, 只需输入其名称即可显示数据集(这里只有120条记录, 但是可以想象一下, 对于一个具有数千行的真实文件!)。
让我们探索数据:
请注意, 如果要查看数据框包含的行数和列数, 还可以调用nrow(Mydf)和ncol(Mydf)。
可以对数据进行许多其他查询。
例如, 在这里, 你有兴趣了解产品在哪个部门中卖得最好的地方。这就是为什么你应该按部门对数据进行重新分组, 并借助aggregate()函数汇总每个部门DepPC的销售额(数量)的原因:
因此, aggregate()告诉R你希望对属于同一部门的所有数量求和。
请注意, R没有将和分配给变量” x”, 因为你没有另外说明。
输出原样是可读性良好的, 但是对于更多部门而言, 其可读性可能较低。在这些情况下, 你可以求助于某些图形输出:你可以使用R的图形输出系统之一和aggregate()函数来绘制结果:
这给了我们每个部门的销售。
你可能会问同样的问题, 但只针对已交付的货物。为此, 你首先要使用现在熟悉的子集运算符” [“对要传送的数据为真(T)进行子集化。
请注意, 在这里你将结果分配给新变量Y, 这是一个新数据框, 它继承了父数据框Mydf的相同列名。你这样做是为了避免在绘图调用中重复聚合指令以提高可读性:
因此, 你可以像使用aggregate()一样以向量化的方式对数据提出不同的问题, 并且通常将其与便捷的绘图系统(例如ggplot2)结合使用, 从而获得了第一手资料。
请注意, 要做到这一点, 你只需要很少的代码行。
向量化是循环和应用函数的替代选择?
你已经在同一主题上看到了一些变体, 即”以重复的方式作用于一组结构化的数据”。从这个意义上讲, 这些功能不仅可以看作是循环的替代, 而且可以看作是做事的矢量化形式。
从广义上讲, 这里是”向量化”, 我们不会进入这样的辩论, 即是否确实对了apply()函数以及其中的哪个函数进行了向量化(例如, 请参见此处的讨论)。
实际上, 为了选择要使用的apply()函数, 你需要考虑以下因素:
- 输入的数据类型:这是你将要作用的对象(向量, 矩阵, 数组…, 列表, 数据框或它们的组合)
- 你打算做什么:你要传递的FUN函数
- 该数据的子集:行, 列还是全部?
- 你想从函数中获取什么类型的数据?因为你可能要对其执行进一步的操作(你是否要一个新对象, 还是要直接转换输入对象?)
这些是你可能会询问相关功能的非常普遍的问题, 我们已经考虑了其中的aggregate(), by(), sweep()等。
但是还有更多!现在不要停止探索!
作为本教程的后续, 请考虑阅读srcmini的R教程或中级R课程的介绍。
评论前必须登录!
注册