 srcmini
srcmini如果你想全面了解Python中的Web抓取, 请参加srcmini的Web Scraping with Python课程。
在本教程中, 你将学习如何使用Scrapy, 这是一个Python框架, 可以使用它处理大量数据!你将通过为电子商务网站AliExpress.com构建网络抓取工具来学习Scrapy。让我们开始报废吧!
- Scrapy概述
- Scrapy Vs. BeautifulSoup
- Scrapy的安装
- Scrapy shell
- 创建一个项目并创建一个自定义蜘蛛
基本的HTML和CSS知识将帮助你更轻松, 更快速地理解本教程。阅读本文以获得有关HTML和CSS的新知识。
Scrapy概述
资源
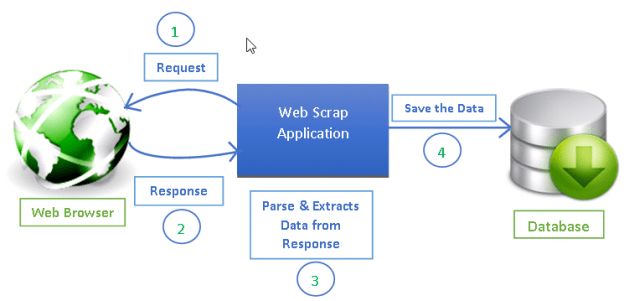
Web抓取已成为从Web提取信息以进行决策和分析的有效方法。它已成为数据科学工具包的重要组成部分。数据科学家应该知道如何从网页上收集数据并以不同格式存储该数据以进行进一步分析。
你可以在Internet上看到的任何网页都进行爬网以获取信息, 并且可以提取网页上可见的任何内容[2]。每个网页都有其自己的结构和Web元素, 因此, 你需要根据要提取的网页编写Web搜寻器/蜘蛛。
Scrapy提供了一个强大的框架来提取数据, 处理数据然后保存。
Scrapy使用蜘蛛, 蜘蛛是独立的爬虫, 并提供了一组说明[1]。在Scrapy中, 通过允许开发人员重用其代码, 可以更轻松地构建和扩展大型爬网项目。
Scrapy Vs. BeautifulSoup
在本节中, 你将概述一种最流行的Web抓取工具, 称为BeautifulSoup, 并将其与Scrapy进行比较。
Scrapy是用于Web抓取的Python框架, 可为开发人员提供完整的软件包, 而无需担心维护代码。
Beautiful Soup也被广泛用于网页抓取。这是一个Python包, 用于解析HTML和XML文档并从中提取数据。它适用于Python 2.6+和Python 3。
简而言之, 这是它们之间的一些区别:
| Scrapy | BeautifulSoup |
|---|---|
| Functionality | — |
| Scrapy是下载网页, 处理网页并将其保存在文件和数据库中的完整软件包。 | BeautifulSoup本质上是一个HTML和XML解析器, 并且需要其他库(例如请求, urlib2)来打开URL并存储结果[6] |
| 学习曲线 | — |
| Scrapy是进行网页抓取的强大平台, 并提供了多种方式来抓取网页。它需要更多的时间来学习和理解Scrapy的工作原理, 但是一旦学习, 将简化Web爬网程序的创建过程, 并且仅需一行命令即可运行它们。成为Scrapy的专家可能需要一些练习和时间来学习所有功能。 | 对于编程新手来说, BeautifulSoup相对容易理解, 并且可以立即完成较小的任务 |
| 速度和负载 | — |
| Scrapy可以轻松完成大型工作。它可以在不超过一分钟的时间内对一组URL进行爬网, 具体取决于该组的大小, 并且它使用Twister进行异步处理(非阻塞)以实现并发性, 因此可以非常平滑地进行抓取。 | BeautifulSoup用于高效地进行简单的刮削作业。如果不使用多处理, 它的速度比Scrapy慢。 |
| 扩展功能 | — |
| Scrapy提供了Item管道, 使你可以在Spider中编写可以处理数据的功能, 例如验证数据, 删除数据以及将数据保存到数据库。它提供了蜘蛛合约来测试你的蜘蛛, 并允许你创建通用和深层爬虫。它允许你管理许多变量, 例如重试, 重定向等。 | 如果项目不需要太多逻辑, BeautifulSoup可以很好地完成工作, 但是如果你需要大量定制(例如代理, 管理cookie和数据管道), 那么Scrapy是最佳选择。 |
信息:同步意味着你必须等待一个任务完成才能开始新任务, 而异步意味着你可以在上一个任务完成之前转移到另一个任务
这是一个有趣的srcmini BeautifulSoup教程, 需要学习。
Scrapy的安装

安装了Python 3.0(及更高版本)后, 如果你使用的是蟒蛇皮, 则可以使用conda来安装scrapy。在anaconda提示符中输入以下命令:
conda安装-c conda-forge scrapy
要安装anaconda, 请查看这些适用于Mac和Windows的srcmini教程。
另外, 你可以使用Python Package Installer pip。适用于Linux, Mac和Windows:
点安装scrapy
Scrapy shell
Scrapy还提供了一个名为Scrapy Shell的网络爬网外壳, 开发人员可以使用它来测试对网站行为的假设。让我们在速卖通电子商务网站上浏览平板电脑网页。你可以使用Scrapy shell查看网页返回的组件以及如何根据需要使用它们。
打开命令行并输入以下命令:
Scrapy shell
如果使用anaconda, 则也可以在anaconda提示符下编写以上命令。你在命令行或anaconda提示符下的输出将如下所示:

你必须使用Scrapy Shell中的fetch命令在网页上运行搜寻器。爬虫或蜘蛛会通过网页下载其文本和元数据。
获取(https://www.aliexpress.com/category/200216607/tablets.html)
注意:请始终将URL括在引号中, 单引号和双引号均适用
输出将如下所示:

搜寻器返回一个响应, 可以通过在shell上使用view(response)命令来查看该响应:
查看(响应)
并且该网页将在默认浏览器中打开。

你可以在Scrapy shell中使用以下命令来查看原始HTML脚本:
打印(response.text)

你将看到生成网页的脚本。该内容与你左键单击网页上的任何空白区域并单击”查看源”或”查看页面源”的内容相同。由于你只需要整个脚本中的相关信息, 因此使用浏览器开发人员工具将检查所需的元素。让我们采取以下要素:
- 平板电脑名称
- 平板电脑价格
- 订单数
- 店铺名称
右键单击所需的元素, 然后单击检查, 如下所示:

浏览器的开发人员工具将帮助你进行网络抓取。你可以看到它是带有类产品的<a>标记, 并且文本包含该产品的名称:

使用CSS选择器进行提取
你可以使用元素属性或类之类的css选择器来提取此内容。在Scrapy shell中编写以下内容以提取产品名称:
response.css(“。product :: text”)。extract_first()
输出将是:

extract_first()提取满足CSS选择器的第一个元素。如果要提取所有产品名称, 请使用extract():
response.css(“。product :: text”)。extract()

以下代码将提取产品的价格范围:
response.css(“。value :: text”)。extract()

同样, 你可以尝试使用多个订单和商店名称。
使用XPath进行提取
XPath是一种查询语言, 用于选择XML文档中的节点[7]。你可以使用XPath浏览XML文档。在后台, Scrapy使用Xpath导航到HTML文档项目。你在上面使用的CSS选择器也可以转换为XPath, 但是在许多情况下, CSS非常易于使用。但是你应该知道Scrapy中的XPath是如何工作的。
转到Scrapy Shell, 以与以前相同的方式编写fetch。试用以下代码片段[3]:
response.xpath(‘/ html’)。extract()
这将显示<html>标记下的所有代码。 /表示节点的直接子级。如果要在html标记下获取<div>标记, 请编写[3]:
response.xpath(‘/ html // div’)。extract()
对于XPath, 你必须学习理解/和//的用法, 以了解如何在子节点和后代节点之间导航。这是有关XPath节点的有用教程, 并提供了一些示例供你试用。
如果要获取所有<div>标记, 可以通过向下钻取来完成, 而无需使用/ html [3]:
response.xpath(” // div”)。extract()
你可以使用属性及其值进一步过滤从其开始并到达所需节点的节点。以下是使用类及其值的语法。
response.xpath(” // div [@ class =’quote’] / span [@ class =’text’]”)。extract()
response.xpath(” // div [@ class =’quote’] / span [@ class =’text’] / text()”)。extract()
使用text()提取节点内的所有文本
考虑以下HTML代码:

你想在<a>标记内获取文本, 该标记是<div>的子节点, 具有子类site-notice-container容器, 你可以按照以下步骤进行操作:
response.xpath(‘// div [@ class =” site-notice-container container”] / a [@ class =” notice-close”] / text()’)。extract()

创建一个Scrapy项目和Custom Spider
Web抓取可用于制作可用于比较数据的聚合器。例如, 你想购买一台平板电脑, 并且想要一起比较产品和价格, 则可以抓取所需的页面并将其存储在excel文件中。在这里, 你将刮掉aliexpress.com以获得平板电脑信息。
现在, 你将为同一页面创建一个自定义蜘蛛。首先, 你需要创建一个Scrapy项目, 其中将存储你的代码和结果。在命令行或anaconda提示符中输入以下命令。
scrapy startproject全球速卖通

这将在默认的python或anaconda安装中创建一个隐藏文件夹。 aliexpress将是文件夹的名称。你可以给任何名字。你可以直接通过资源管理器查看文件夹内容。以下是文件夹的结构:

| 文件夹 | 目的 |
|---|---|
| scrapy.cfg | 部署配置文件 |
| aliexpress/ | Project的Python模块, 你将从此处导入代码 |
| __init.py__ | 初始化文件 |
| items.py | 项目项目文件 |
| pipelines.py | 项目管道文件 |
| settings.py | 项目设置文件 |
| spiders/ | 一个目录, 你稍后将在其中放置蜘蛛 |
| __init.py__ | 初始化文件 |
创建项目后, 将切换到新创建的目录并编写以下命令:
[scrapy genspider aliexpress_tablets](https://www.aliexpress.com/category/200216607/tablets.html)

如上所述, 这会在蜘蛛目录中创建一个名为aliexpress_tablets.py的模板文件。该文件中的代码如下:
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html']
def parse(self, response):
pass
在上面的代码中, 你可以看到名称, allowed_domains, sstart_urls和解析函数。
- 名称:名称是蜘蛛的名称。适当的名称将帮助你跟踪所制造的所有蜘蛛。名称必须唯一, 因为在使用抓取爬网name_of_spider时, 它将用于运行蜘蛛。
- allowed_domains(可选):可选的python列表, 包含允许爬网的域。不在此列表中的URL请求将不会被爬网。这应该只包括网站的域名(例如:aliexpress.com), 而不应该包括在start_urls中指定的整个URL, 否则你将得到警告。
- start_urls:这要求提到的URL。当未指定特定的URL时, 蜘蛛将开始从其爬网的URL列表[4]。因此, 下载的第一页将是此处列出的页面。随后的请求将根据起始URL [4]中包含的数据连续生成。
- parse(self, response):成功爬网URL时将调用此函数。它也称为回调函数。由于爬网而返回的响应(在Scrapy shell中使用)在此函数中传递, 然后在其中编写提取代码!
信息:你可以在Scrapy Spider的parse()函数内使用BeautifulSoup来解析html文档。
注意:你可以使用css选择器中的response.css()通过css选择器提取数据, 如在scrapy shell部分中所述, 也可以使用XPath(XML)来访问子元素。你将在pass()函数中编辑的代码中看到response.xpath()的示例。
你将对aliexpress_tablet.py文件进行更改。我在start_urls中添加了另一个URL。你可以将提取逻辑添加到pass()函数, 如下所示:
# -*- coding: utf-8 -*-
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html', 'https://www.aliexpress.com/category/200216607/tablets/2.html?site=glo&g=y&tag=']
def parse(self, response):
print("procesing:"+response.url)
#Extract data using css selectors
product_name=response.css('.product::text').extract()
price_range=response.css('.value::text').extract()
#Extract data using xpath
orders=response.xpath("//em[@title='Total Orders']/text()").extract()
company_name=response.xpath("//a[@class='store $p4pLog']/text()").extract()
row_data=zip(product_name, price_range, orders, company_name)
#Making extracted data row wise
for item in row_data:
#create a dictionary to store the scraped info
scraped_info = {
#key:value
'page':response.url, 'product_name' : item[0], #item[0] means product in the list and so on, index tells what value to assign
'price_range' : item[1], 'orders' : item[2], 'company_name' : item[3], }
#yield or give the scraped info to scrapy
yield scraped_info
信息:zip()接受n个可迭代对象, 并返回一个元组列表。元组的ith元素是使用每个可迭代对象中的ith元素创建的。 [8]
每当你定义生成器函数时, 都会使用yield关键字。生成器函数与普通函数类似, 除了它使用yield关键字而不是return之外。每当调用方函数需要一个值并且包含yield的函数将保留其本地状态并在将值产生给调用方函数后从中断处继续执行时, 都会使用yield关键字。在这里yield将生成的字典交给Scrapy, 它将对其进行处理和保存!
现在你可以运行蜘蛛了:
抓痒的爬行aliexpress_tablets
你将在命令行中看到如下所示的长输出:


汇出资料
你将需要将数据以CSV或JSON形式显示, 以便你可以进一步使用该数据进行分析。本教程的这一部分将指导你如何保存此数据的CSV和JSON文件。
要保存CSV文件, 请从项目目录中打开settings.py并添加以下行:
FEED_FORMAT="csv"
FEED_URI="aliexpress.csv"
保存settings.py后, 请在项目目录中重新运行抓取抓取aliexpress_tablets。

CSV文件如下所示:

注意:每次你运行Spider时, 它都会附加文件。
- FEED_FORMAT [5]:设置你要存储数据的格式。支持的格式有:
+ JSON + CSV + JSON行+ XML - FEED_URI [5]:这给出了文件的位置。你可以将文件存储在本地文件存储中, 也可以存储在FTP上。
Scrapy的Feed导出还可以在文件名中添加时间戳记和Spider名称, 或者你可以使用它们来标识要存储的目录。
- %(time)s:创建提要时被时间戳替换[5]
- %(name)s:被蜘蛛名[5]取代
例如:
- 每个蜘蛛使用一个目录存储在FTP中[5]:
ftp:// user:password@ftp.example.com/scraping/feeds/%(name)s /%(time)s.json
你在settings.py中进行的Feed更改将应用于项目中的所有蜘蛛。你还可以为特定蜘蛛设置自定义设置, 该设置将覆盖settings.py文件中的设置。
# -*- coding: utf-8 -*-
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html', 'https://www.aliexpress.com/category/200216607/tablets/2.html?site=glo&g=y&tag=']
custom_settings={ 'FEED_URI': "aliexpress_%(time)s.json", 'FEED_FORMAT': 'json'}
def parse(self, response):
print("procesing:"+response.url)
#Extract data using css selectors
product_name=response.css('.product::text').extract()
price_range=response.css('.value::text').extract()
#Extract data using xpath
orders=response.xpath("//em[@title='Total Orders']/text()").extract()
company_name=response.xpath("//a[@class='store $p4pLog']/text()").extract()
row_data=zip(product_name, price_range, orders, company_name)
#Making extracted data row wise
for item in row_data:
#create a dictionary to store the scraped info
scraped_info = {
#key:value
'page':response.url, 'product_name' : item[0], #item[0] means product in the list and so on, index tells what value to assign
'price_range' : item[1], 'orders' : item[2], 'company_name' : item[3], }
#yield or give the scraped info to Scrapy
yield scraped_info
response.url返回从中生成响应的页面的URL。使用scrapy crawl aliexpress_tablets运行搜寻器后, 你可以查看json文件:

追踪连结
你一定已经注意到, start_urls中有两个链接。第二个链接是相同平板电脑搜索结果的第2页。添加所有链接将变得不切实际。搜寻器应能够自己在所有页面中进行搜寻, 并且start_urls中仅应提及起点。
如果页面中有后续页面, 你将在页面末尾看到一个用于该页面的导航器, 以允许在页面之间来回移动。如果你已经在本教程中实现了, 你将看到如下所示:

这是你将看到的代码:

如你所见, 在你当前所在的页面下, 有一个<span>标记, 其类为.ui-pagination-active class, 并且所有这些<a>标记下均具有指向下一页的链接。每次你都必须在该<span>标记之后获取<a>标记。这里有一些CSS!在这种情况下, 你必须获得同级节点而不是子节点, 因此必须创建一个css选择器, 该选择器告诉爬虫使用.ui-pagination-active类在<span>标记之后找到<a>标记。
记得!每个网页都有其自己的结构。你将不得不对如何获得所需元素的结构进行一些研究。在用代码编写它们之前, 请务必在Scrapy Shell上尝试使用response.css(SELECTOR)。
如下修改你的aliexpress_tablets.py:
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html']
custom_settings={ 'FEED_URI': "aliexpress_%(time)s.csv", 'FEED_FORMAT': 'csv'}
def parse(self, response):
print("procesing:"+response.url)
#Extract data using css selectors
product_name=response.css('.product::text').extract()
price_range=response.css('.value::text').extract()
#Extract data using xpath
orders=response.xpath("//em[@title='Total Orders']/text()").extract()
company_name=response.xpath("//a[@class='store $p4pLog']/text()").extract()
row_data=zip(product_name, price_range, orders, company_name)
#Making extracted data row wise
for item in row_data:
#create a dictionary to store the scraped info
scraped_info = {
#key:value
'page':response.url, 'product_name' : item[0], #item[0] means product in the list and so on, index tells what value to assign
'price_range' : item[1], 'orders' : item[2], 'company_name' : item[3], }
#yield or give the scraped info to scrapy
yield scraped_info
NEXT_PAGE_SELECTOR = '.ui-pagination-active + a::attr(href)'
next_page = response.css(NEXT_PAGE_SELECTOR).extract_first()
if next_page:
yield scrapy.Request(
response.urljoin(next_page), callback=self.parse)
在上面的代码中:
- 你首先使用next_page = response.css(NEXT_PAGE_SELECTOR).extract_first()提取了下一页的链接, 然后, 如果变量next_page获得链接并且不为空, 则将输入if正文。
- response.urljoin(next_page):parse()方法将使用此方法构建新的URL并提供新的请求, 该请求稍后将发送至回调。 [9]
- 收到新的URL后, 它将抓取该链接, 执行for正文, 然后再次查找下一页。这将继续, 直到没有下一页链接。
在这里, 你可能想坐下来, 尽情享受蜘蛛抓取所有页面的乐趣。上面的蜘蛛将从所有后续页面中提取。那将是很多刮!!但是你的蜘蛛会做到的!在下面你可以看到文件大小已达到1.1MB。

Scrapy为你做到了!
在本教程中, 你了解了Scrapy, 它与BeautifulSoup, Scrapy Shell的比较以及如何在Scrapy中编写自己的蜘蛛。从创建项目文件和文件夹到处理重复的URL, Scrapy可以为你处理所有繁重的编码工作, 它可以帮助你在几分钟内完成繁重的Web抓取工作, 并为你提供所有常用数据格式的支持, 你可以在其他程序中进一步输入这些格式。本教程肯定会帮助你了解Scrapy及其框架以及如何使用它。要成为Scrapy的大师, 你需要了解它提供的所有奇妙功能, 但是本教程使你能够高效地抓取网页组。
有关进一步的阅读, 你可以参考官方的Scrapy文档。
另外, 不要忘记查看srcmini的Python Web Scraping课程。
评论前必须登录!
注册