 srcmini
srcmini你是否曾经想比较过引用同一事物的字符串, 但是它们的书写方式略有不同, 是否有错别字或拼写错误?在从拼写检查软件到缺少公用密钥的映射数据库的各种情况下, 你可能会遇到此问题(请尝试通过公司名称联接两个表, 并且两个表中的表显示方式不同)。
对于本教程, 我将专注于一个案例研究, 其中解决了上述数据库问题。但是, 在开始之前, 展示如何模糊匹配字符串将是有益的。通常, 在Python中比较字符串时, 你可以执行以下操作:
Str1 = "Apple Inc."
Str2 = "Apple Inc."
Result = Str1 == Str2
print(Result)
True
在这种情况下, 变量Result将输出True, 因为字符串是完全匹配的(100%相似), 但是看看如果Str2的大小写发生变化会发生什么:
Str1 = "Apple Inc."
Str2 = "apple Inc."
Result = Str1 == Str2
print(Result)
False
这次我们得到了False, 即使字符串在人眼中看起来完全一样。但是, 这个问题非常容易解决, 因为我们可以将两个字符串都强制转换为小写:
Str1 = "Apple Inc."
Str2 = "apple Inc."
Result = Str1.lower() == Str2.lower()
print(Result)
True
然而, 一旦角色消失, 这种幸福就结束了。例如:
Str1 = "Apple Inc."
Str2 = "apple Inc"
Result = Str1.lower() == Str2.lower()
print(Result)
False
有时上述情况有时会出现在基于人工数据输入创建的数据库中, 在这些情况下, 我们需要功能更强大的工具来比较字符串。这些工具之一称为Levenshtein距离。
莱文施泰因距离
Levenshtein距离是衡量两个单词序列相隔的量度。换句话说, 它测量将一个单词序列转换为另一个单词序列所需的最少编辑次数。这些编辑可以是插入, 删除或替换。该度量标准以弗拉基米尔·莱文施泰因(Vladimir Levenshtein)的名字命名, 他最初于1965年考虑该度量。
两个字符串$ a $和$ b $之间的Levenshtein距离的形式定义如下:
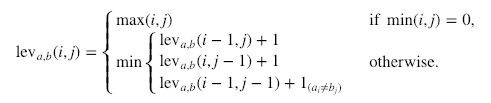
其中$ 1 _ {((a_i \ neq b_j)} $表示$ a = b $时为0, 否则为1。重要的是要注意, 以上最小值中的行按该顺序对应于删除, 插入和替换。
还可以基于莱文施泰因距离来计算莱文施泰因相似度比。可以使用以下公式完成此操作:
$$ \ frac {(| a | + | b |)-{lev} _ {a, b}(i, j)} {| a | + | b |} $$
其中$ | a | $和$ | b | $分别是序列$ a $和序列$ b $的长度。
在下面, 你可以看到如何使用Python函数从头开始实现这样的公式:
import numpy as np
def levenshtein_ratio_and_distance(s, t, ratio_calc = False):
""" levenshtein_ratio_and_distance:
Calculates levenshtein distance between two strings.
If ratio_calc = True, the function computes the
levenshtein distance ratio of similarity between two strings
For all i and j, distance[i, j] will contain the Levenshtein
distance between the first i characters of s and the
first j characters of t
"""
# Initialize matrix of zeros
rows = len(s)+1
cols = len(t)+1
distance = np.zeros((rows, cols), dtype = int)
# Populate matrix of zeros with the indeces of each character of both strings
for i in range(1, rows):
for k in range(1, cols):
distance[i][0] = i
distance[0][k] = k
# Iterate over the matrix to compute the cost of deletions, insertions and/or substitutions
for col in range(1, cols):
for row in range(1, rows):
if s[row-1] == t[col-1]:
cost = 0 # If the characters are the same in the two strings in a given position [i, j] then the cost is 0
else:
# In order to align the results with those of the Python Levenshtein package, if we choose to calculate the ratio
# the cost of a substitution is 2. If we calculate just distance, then the cost of a substitution is 1.
if ratio_calc == True:
cost = 2
else:
cost = 1
distance[row][col] = min(distance[row-1][col] + 1, # Cost of deletions
distance[row][col-1] + 1, # Cost of insertions
distance[row-1][col-1] + cost) # Cost of substitutions
if ratio_calc == True:
# Computation of the Levenshtein Distance Ratio
Ratio = ((len(s)+len(t)) - distance[row][col]) / (len(s)+len(t))
return Ratio
else:
# print(distance) # Uncomment if you want to see the matrix showing how the algorithm computes the cost of deletions, # insertions and/or substitutions
# This is the minimum number of edits needed to convert string a to string b
return "The strings are {} edits away".format(distance[row][col])
如果我们将此功能应用于前面的示例, 在这里我们尝试比较” Apple Inc.”。到”苹果公司”, 我们将看到这两个strinsg非常相似, 因为Levenshtein距离非常小。
Str1 = "Apple Inc."
Str2 = "apple Inc"
Distance = levenshtein_ratio_and_distance(Str1, Str2)
print(Distance)
Ratio = levenshtein_ratio_and_distance(Str1, Str2, ratio_calc = True)
print(Ratio)
The strings are 2 edits away
0.8421052631578947
如你所见, 该函数发现了两个字符串之间的2个差异。这些是大写/小写a和第一个字符串末尾的句号(句号), 以及相似率84%, 这是很高的。在继续之前, 我想强调一个重要的概念。如果在计算距离之前进行非常简单的字符串预处理, 则会看到以下内容:
Str1 = "Apple Inc."
Str2 = "apple Inc"
Distance = levenshtein_ratio_and_distance(Str1.lower(), Str2.lower())
print(Distance)
Ratio = levenshtein_ratio_and_distance(Str1.lower(), Str2.lower(), ratio_calc = True)
print(Ratio)
The strings are 1 edits away
0.9473684210526315
如此一来, 只需在比较之前将字符串转换为小写字母, 并将相似率降至几乎95%, 即可将距离减少1。这强调了在执行计算之前字符串预处理的相关性。例如, 如果你基于90%的相似度阈值选择一个字符串是否与另一个相似, 则选择” Apple Inc.”。和没有预处理的”苹果公司”将被标记为不相似。
即使上面的示例是实现函数来计算Levenshtein距离的有效方法, 但在Python中, 也存在Levenshtein包形式的更简单的替代方法。 Levenshtein软件包包含两个功能, 它们与上述用户定义的功能相同。一个例子如下所示。
import Levenshtein as lev
Str1 = "Apple Inc."
Str2 = "apple Inc"
Distance = lev.distance(Str1.lower(), Str2.lower()), print(Distance)
Ratio = lev.ratio(Str1.lower(), Str2.lower())
print(Ratio)
(1, )
0.9473684210526315
注意:你可能已经注意到, 在上面的用户定义函数中, 有一条注释提到, 当计算相似率时, 替换的成本为2而不是1。这是因为lev.ratio()分配了替换的费用(将替换考虑为必须同时进行删除和插入)。但是, 重要的是要注意, 替换在lev.distance()中的成本为1。因此, 如果你尝试手动验证函数的输出, 请记住这一点, 这一点很重要。
该软件包的名称可能很有趣, 但是当两个字符串之间相似的标准Levenshtein距离比不足时, 它可能是你最好的朋友。到目前为止, 我一直在使用” Apple Inc.”的示例和”苹果公司”相对简单。毕竟, 如果将两个字符串都转换为小写, 则只有一个句号/句号差。但是, 拼写错误时会发生什么?当某事物的拼写差异很大但又指的是同一事物时, 会发生什么?那就是FuzzyWuzzy软件包出现的地方, 因为它具有允许我们的模糊匹配脚本处理这类情况的功能。
让我们开始简单。像Levenshtein软件包一样, FuzzyWuzzy具有一个比率函数, 该比率函数可计算两个序列之间的标准Levenshtein距离相似比率。你可以在下面看到一个示例:
from fuzzywuzzy import fuzz
Str1 = "Apple Inc."
Str2 = "apple Inc"
Ratio = fuzz.ratio(Str1.lower(), Str2.lower())
print(Ratio)
95
相似的比率与上述其他示例相同。但是, fuzzywuzzy具有更强大的功能, 可让我们处理更复杂的情况, 例如子字符串匹配。这是一个例子:
Str1 = "Los Angeles Lakers"
Str2 = "Lakers"
Ratio = fuzz.ratio(Str1.lower(), Str2.lower())
Partial_Ratio = fuzz.partial_ratio(Str1.lower(), Str2.lower())
print(Ratio)
print(Partial_Ratio)
50
100
fuzz.partial_ratio()能够检测到两个字符串都引用了湖人队。因此, 它产生100%的相似性。它的工作方式是使用”最佳局部”逻辑。换句话说, 如果短字符串的长度为$ k $, 而较长的字符串的长度为$ m $, 则该算法将查找长度最匹配的$ k $子字符串的分数。
但是, 这种方法并非万无一失。当字符串比较相同但顺序不同时会发生什么?对我们来说幸运的是, fuzzywuzzy有一个解决方案。你可以看到以下示例:
Str1 = "united states v. nixon"
Str2 = "Nixon v. United States"
Ratio = fuzz.ratio(Str1.lower(), Str2.lower())
Partial_Ratio = fuzz.partial_ratio(Str1.lower(), Str2.lower())
Token_Sort_Ratio = fuzz.token_sort_ratio(Str1, Str2)
print(Ratio)
print(Partial_Ratio)
print(Token_Sort_Ratio)
59
74
100
fuzz.token函数相对于ratio和partial_ratio具有重要的优势。它们标记字符串并通过将它们转换为小写并消除标点符号进行预处理。在fuzz.token_sort_ratio()的情况下, 字符串标记按字母顺序排序, 然后结合在一起。之后, 应用简单的fuzz.ratio()来获得相似度百分比。这允许将本示例中的案件(例如法院案件)标记为相同。
但是, 如果这两个字符串的长度相差很大, 会发生什么?那就是fuzz.token_set_ratio()传入的地方。这是一个示例:
Str1 = "The supreme court case of Nixon vs The United States"
Str2 = "Nixon v. United States"
Ratio = fuzz.ratio(Str1.lower(), Str2.lower())
Partial_Ratio = fuzz.partial_ratio(Str1.lower(), Str2.lower())
Token_Sort_Ratio = fuzz.token_sort_ratio(Str1, Str2)
Token_Set_Ratio = fuzz.token_set_ratio(Str1, Str2)
print(Ratio)
print(Partial_Ratio)
print(Token_Sort_Ratio)
print(Token_Set_Ratio)
57
77
58
95
95%的相似之处是魔术吗?不, 这只是引擎盖下的字符串预处理。特别是, fuzz.token_set_ratio()比fuzz.token_sort_ratio()采取了更灵活的方法。 token_set_ratio不仅执行字符串化标记, 排序然后将令牌重新粘贴在一起的功能, 还执行set操作, 该操作取出通用令牌(交集), 然后在以下新字符串之间进行fuzz.ratio()的成对比较:
- s1 = Sorted_tokens_in_intersection
- s2 = Sorted_tokens_in_intersection + sorted_rest_of_str1_tokens
- s3 = Sorted_tokens_in_intersection + sorted_rest_of_str2_tokens
这些比较背后的逻辑是, 由于Sorted_tokens_in_intersection始终相同, 因此随着这些单词构成原始字符串的较大块或其余标记彼此更接近, 分数将趋于上升。
最后, fuzzywuzzy程序包具有一个名为process的模块, 该模块使你可以从字符串向量中计算出具有最高相似度的字符串。你可以在下面查看其工作原理:
from fuzzywuzzy import process
str2Match = "apple inc"
strOptions = ["Apple Inc.", "apple park", "apple incorporated", "iphone"]
Ratios = process.extract(str2Match, strOptions)
print(Ratios)
# You can also select the string with the highest matching percentage
highest = process.extractOne(str2Match, strOptions)
print(highest)
[('Apple Inc.', 100), ('apple incorporated', 90), ('apple park', 67), ('iphone', 30)]
('Apple Inc.', 100)
在本教程中, 你学习了如何近似匹配字符串并确定它们的相似程度。此处提供的示例可能很简单, 但足以说明如何处理计算机认为字符串不匹配的各种情况。我基于一种情况使用本教程, 在这种情况下, 我必须使用模糊字符串匹配将手动输入的公司名称映射到雇主的Salesforce CRM中的帐户名(” Apple Inc.”到” apple inc”实际上是其中之一)。映射)。但是, 这种技术的用处还没有结束。在诸如拼写检查或生物信息学之类的领域中有一些应用可以匹配DNA序列, 因此, 模糊匹配肯定还有更多用途。
我希望你已经完全喜欢本教程, 并且已经从中学习到了。保持学习;天空才是极限!
如果你想了解有关Python函数的更多信息, 请参加srcmini的Python数据科学工具箱(第1部分)课程。
评论前必须登录!
注册