 srcmini
srcmini本文概述
- 为什么要学习SQL进行数据科学学习?
- SQL处理和查询执行
- 编写SQL查询
- 基于集合与过程的查询方法
- 从查询到执行计划
- 查询优化
- 时间复杂度与大O
- 估计查询计划的时间复杂度
- SQL调优
- 使SQL更进一步
在数据科学行业中, 结构化查询语言(SQL)是必不可少的技能, 通常来说, 学习此技能相对简单。但是, 大多数人都忘记了SQL不仅仅是写查询, 这只是迈出的第一步。确保查询性能良好或适合你所处的环境是另一回事。
因此, 本SQL教程将向你简要介绍评估查询的一些步骤:
- 首先, 我们将简要概述学习SQL对数据科学工作的重要性;
- 接下来, 你将首先了解有关SQL查询处理和执行方式的更多信息, 以便充分了解编写定性查询的重要性:更具体地说, 你将看到查询已被解析, 重写, 优化和最终评估;
- 考虑到这一点, 你不仅会研究初学者编写查询时使用的一些查询反模式, 而且还将了解有关这些可能的错误的替代方法和解决方案的更多信息;你还将了解有关基于集合的查询和基于过程的查询方法的更多信息。
- 你还将看到这些反模式源于性能问题, 除了”手动”方法可以改进SQL查询之外, 你还可以通过使用其他一些工具以更结构化, 更深入的方式分析查询帮助你查看查询计划;和,
- 在执行查询之前, 你将简要地介绍时间复杂度和大的O表示法, 以了解执行计划的时间复杂度。最后,
- 你将简要了解如何进一步优化查询。

你对SQL课程感兴趣吗?参加srcmini的SQL数据科学入门课程!
为什么要学习SQL进行数据科学学习?
SQL尚未灭亡:无论你要申请数据分析师, 数据工程师, 数据科学家还是任何其他职位, SQL都是你在数据科学行业的职位描述中最需要的技能之一。在2016年O’Reilly数据科学薪酬调查中, 有70%的受访者证实了这一点, 他们表示他们在专业环境中使用SQL。更重要的是, 在这项调查中, SQL在R(57%)和Python(54%)编程语言之上脱颖而出。
你了解一下:在数据科学行业中寻求工作时, SQL是必不可少的技能。
对于1970年代初开发的语言来说还不错吧?
但是, 为什么它是如此频繁地使用呢?为什么它已经存在了这么长时间, 为什么还没死呢?
原因有几个:第一个原因是公司通常将数据存储在关系数据库管理系统(RDBMS)或关系数据流管理系统(RDSMS)中, 并且你需要SQL来访问该数据。 SQL是数据的通用语言:它使你能够与几乎任何数据库进行交互, 甚至可以在本地构建自己的数据库!
好像还不够, 请记住, 有很多SQL实现在供应商之间是不兼容的, 并且不一定遵循标准。因此, 了解标准SQL是你在(数据科学)行业中寻找出路的要求。
最重要的是, 可以肯定地说, SQL也已被较新的技术所采用, 例如Hive(一种类似于SQL的查询语言界面, 用于查询和管理大型数据集)或Spark SQL(可用于执行SQL查询)。再次, 你在此处找到的SQL将与你可能已经学习的标准有所不同, 但是学习过程将容易得多。
如果你确实想进行比较, 可以将其视为学习线性代数:通过将所有精力放在这一主题上, 你将知道也可以使用它来掌握机器学习!
简而言之, 这就是为什么你应该学习以下查询语言的原因:
- 即使是新手, 也很容易学习。学习曲线非常简单且循序渐进, 因此你将立即编写查询。
- 它遵循”一次学习, 随处使用”的原则, 因此, 这是你宝贵的时间!
- 它是编程语言的绝佳补充;在某些情况下, 编写查询甚至比编写代码更可取, 因为它性能更高!
- …
你还在等什么? 🙂
SQL处理和查询执行
为了提高SQL查询的性能, 你首先必须知道在按快捷方式运行查询时内部会发生什么。
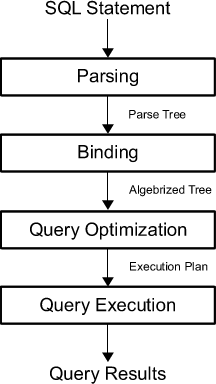
首先, 查询被解析为”解析树”;分析查询以查看其是否满足语法和语义要求。解析器创建输入查询的内部表示。然后, 此输出将传递到重写引擎。
然后, 优化器的任务是为给定查询找到最佳执行或查询计划。执行计划准确定义了每个操作使用哪种算法, 以及如何协调操作的执行。
为了确实找到最佳的执行计划, 优化器会枚举所有可能的执行计划, 确定每个计划的质量或成本, 获取有关当前数据库状态的信息, 然后选择最佳的执行计划作为最终执行计划。由于查询优化器可能不完善, 因此数据库用户和管理员有时需要手动检查和调整由优化器产生的计划, 以获得更好的性能。
现在你可能想知道什么被认为是”良好的查询计划”。
正如你已经读过的, 计划成本的质量起着相当重要的作用。更具体地说, 诸如评估计划所需的磁盘I / O数量, 计划的CPU成本以及数据库客户端可以观察到的总响应时间以及总执行时间之类的内容至关重要。这就是时间复杂性的概念。稍后你将详细了解。
接下来, 执行所选的查询计划, 并由系统的执行引擎对其进行评估, 然后返回查询结果。
编写SQL查询
从上一节可能还不清楚的是, 垃圾进, 垃圾出(GIGO)原理自然会在查询处理和执行中浮出水面:制定查询的人还掌握了SQL查询性能的关键。如果优化器收到格式不正确的查询, 则只能执行尽可能多的工作……
这意味着你在编写查询时可以做一些事情。正如你在简介中已经看到的那样, 责任是双重的:它不仅涉及编写符合特定标准的查询, 而且还涉及收集有关性能问题可能在查询中潜伏的想法。
理想的出发点是考虑查询中可能出现问题的”点”。通常, 新手可以使用四个子句和关键字来预测性能问题:
- WHERE子句;
- 任何INNER JOIN或LEFT JOIN关键字;和,
- HAVING子句;
当然, 这种方法既简单又幼稚, 但是对于初学者来说, 这些子句和语句是出色的指针, 可以肯定地说, 当你刚入门时, 这些地方就是发生错误的地方, 而且具有讽刺意味的是, 这些地方他们也很难发现。
但是, 你还应该意识到性能是需要上下文才能变得有意义的事情:仅考虑这些子句和关键字是不好的, 这并不是你考虑SQL性能时要走的路。查询中包含WHERE或HAVING子句并不一定意味着它是一个错误的查询…
请看以下部分, 以了解有关反模式和构建查询的其他方法的更多信息。这些提示和技巧仅供参考。实际需要如何以及是否需要重写查询取决于数据量, 数据库以及执行查询所需的次数等。这完全取决于你的查询目标, 并且对你要查询的数据库有一些先验知识至关重要!
1.仅检索你需要的数据
在编写SQL查询时, “数据越多越好”并不是你必须遵循的思维方式:不仅冒着因获取超出实际需求而掩盖洞见的风险, 而且还会提高性能你的查询可能会提取太多数据, 这可能会给你带来麻烦。
这就是为什么通常最好注意SELECT语句, DISTINCT子句和LIKE运算符。
SELECT语句
在编写查询时已经可以检查的第一件事是SELECT语句是否尽可能紧凑。你的目标是从SELECT中删除不必要的列。这样, 你可以强制自己仅提取满足查询目标的数据。
如果你已将具有EXISTS的子查询相关联, 则应尝试在该子查询的SELECT语句中使用常量, 而不要选择实际列的值。仅在检查存在性时特别方便。
请记住, 相关子查询是使用外部查询中的值的子查询。请注意, 即使在这种情况下NULL可以作为”常量”使用, 也很令人困惑!
考虑以下示例, 以了解使用常量的含义:
SELECT driverslicensenr, name
FROM Drivers
WHERE EXISTS
(SELECT '1'
FROM Fines
WHERE fines.driverslicensenr = drivers.driverslicensenr); 提示:知道相关的子查询并不总是一个好主意, 这很方便。你始终可以考虑摆脱它们, 例如, 使用INNER JOIN重写它们:
SELECT driverslicensenr, name
FROM drivers
INNER JOIN fines ON fines.driverslicensenr = drivers.driverslicensenr; DISTINCT子句
SELECT DISTINCT语句仅用于返回不同的(不同的)值。 DISTINCT是你应尽力避免的子句。正如你在其他示例中所读到的那样, 仅当将此子句添加到查询中时, 执行时间才会增加。因此, 考虑是否真的需要进行DISTINCT操作以获得想要的结果始终是一个好主意。
LIKE运算符
在查询中使用LIKE运算符时, 如果模式以%或_开头, 则不使用索引。这将防止数据库使用索引(如果存在)。当然, 从另一个角度来看, 你也可以辩称, 这种类型的查询可能会敞开大门, 以检索太多不一定满足你的查询目标的记录。
再次, 你对存储在数据库中的数据的了解可以帮助你制定一种模式, 该模式将正确过滤所有数据, 以仅查找对你的查询真正重要的行。
2.限制你的结果
当你无法避免过滤掉SELECT语句时, 可以考虑以其他方式限制结果。这就是LIMIT子句和数据类型转换之类的方法。
TOP, LIMIT和ROWNUM子句
你可以在查询中添加LIMIT或TOP子句, 以设置结果集的最大行数。这里有些例子:
SELECT TOP 3 *
FROM Drivers;请注意, 例如, 如果通过SELECT TOP 50 PERCENT *更改查询的第一行, 则可以进一步指定PERCENT。
SELECT driverslicensenr, name
FROM Drivers
LIMIT 2;此外, 你还可以添加ROWNUM子句, 这等效于在查询中使用LIMIT:
SELECT *
FROM Drivers
WHERE driverslicensenr = 123456 AND ROWNUM <= 3;数据类型转换
你应该始终使用最有效的(即最小的)数据类型。当你提供庞大的数据类型时, 始终存在风险, 而较小的数据类型将足够。
但是, 将数据类型转换添加到查询时, 只会增加执行时间。
另一种选择是尽可能避免数据类型转换。在此还请注意, 并非总是可以从查询中删除或省略数据类型转换, 但是你一定要谨慎地将其包括在内, 并且在这样做时, 请在运行查询之前测试添加的效果。
3.不要让查询变得比需要的复杂
数据类型转换将带你进入下一个要点:你不应过度设计查询。尝试使它们简单有效。这似乎太简单或愚蠢, 甚至不能作为提示, 主要是因为查询可能变得复杂。
但是, 你将在下一部分提到的示例中看到, 你可以轻松地开始使简单查询变得比其复杂。
或运算符
当你在查询中使用OR运算符时, 很可能你没有使用索引。
请记住, 索引是一种数据结构, 可以提高数据库表中数据检索的速度, 但是这样做是有代价的:会有更多的写入操作, 并且需要更多的存储空间来维护索引数据结构。索引用于快速定位或查找数据, 而不必每次访问数据库表时都搜索数据库中的每一行。可以通过使用数据库表中的一个或多个列来创建索引。
如果你不使用数据库包含的索引, 则查询将不可避免地花费更长的时间来运行。这就是为什么最好在查询中寻找使用OR运算符的替代方法;
考虑以下查询:
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr = 123456
OR driverslicensenr = 678910
OR driverslicensenr = 345678;你可以将运算符替换为:
- 有IN的条件;要么
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr IN (123456, 678910, 345678);- 两个带有UNION的SELECT语句。
提示:在这里, 你需要注意不要不必要地使用UNION操作, 因为你会多次浏览同一张表。同时, 你必须意识到, 在查询中使用UNION时, 执行时间将增加。 UNION操作的替代方法是:以所有条件都放在一条SELECT指令中的方式重新构造查询, 或者使用OUTER JOIN代替UNION。
提示:请记住, 即使使用OR(以及以下各节将提到的其他运算符)可能未使用索引, 也不总是首选索引查找!
NOT运算符
当查询中包含NOT运算符时, 很可能未使用索引, 就像使用OR运算符一样。这将不可避免地减慢你的查询速度。如果你不知道这是什么意思, 请考虑以下查询:
SELECT driverslicensenr, name
FROM Drivers
WHERE NOT (year > 1980);此查询的运行速度肯定会比你预期的要慢, 这主要是因为它的编写比可能要复杂得多:在这种情况下, 最好寻找替代方法。考虑用比较运算符(例如>, <>或!>)代替NOT;上面的示例确实可以重写并变成类似以下内容:
SELECT driverslicensenr, name
FROM Drivers
WHERE year <= 1980;看起来已经整洁了, 不是吗?
AND运算符
AND运算符是另一种不使用索引的运算符, 如果以过于复杂和低效的方式使用它会降低查询速度, 例如以下示例:
SELECT driverslicensenr, name
FROM Drivers
WHERE year >= 1960 AND year <= 1980;最好重写此查询并使用BETWEEN运算符:
SELECT driverslicensenr, name
FROM Drivers
WHERE year BETWEEN 1960 AND 1980;ANY和ALL运算符
另外, 你应该注意ANY和ALL运算符, 因为将这些运算符包含在查询中将不会使用索引。聚合函数(如MIN或MAX)在这里会派上用场。
提示:在使用建议的替代方法的情况下, 你应该意识到一个事实, 即许多行上的所有聚合函数(例如SUM, AVG, MIN, MAX)都可能导致长时间运行的查询。在这种情况下, 你可以尝试减少处理或预计算这些值的行数。你会再次发现, 重要的是要了解你的环境, 查询目标……在决定要使用的查询时!
隔离条件中的列
同样, 在计算或标量函数中使用了列的情况下, 也不会使用索引。一种可能的解决方案是简单地隔离特定的列, 以使其不再成为计算或函数的一部分。考虑以下示例:
SELECT driverslicensenr, name
FROM Drivers
WHERE year + 10 = 1980;看起来很时髦吧?而是尝试重新考虑计算并将查询重写为如下所示:
SELECT driverslicensenr, name
FROM Drivers
WHERE year = 1970;4.没有蛮力
这最后一个提示意味着你不应该过多限制查询, 因为它会影响其性能。对于联接和HAVING子句尤其如此。
加入
- 表的顺序
当联接两个表时, 考虑联接中表的顺序可能很重要。如果你发现一个表比另一个表大得多, 则可能需要重写查询, 以便将最大的表放置在联接的最后。
- 连接的冗余条件
当你向联接中添加太多条件时, 你必须让SQL选择特定的路径。不过, 可能这条路并不总是性能更高。
Having子句
HAVING子句最初是添加到SQL的, 因为WHERE关键字不能与聚合函数一起使用。 HAVING通常与GROUP BY子句一起使用, 以将返回的行的组限制为仅满足某些条件的行。但是, 如果你在查询中使用此子句, 则不会使用索引, 因为索引-你已经知道-可能会导致查询实际上并不能很好地执行。
如果你正在寻找替代方法, 请考虑使用WHERE子句。考虑以下查询:
SELECT state, COUNT(*)
FROM Drivers
WHERE state IN ('GA', 'TX')
GROUP BY state
ORDER BY state
SELECT state, COUNT(*)
FROM Drivers
GROUP BY state
HAVING state IN ('GA', 'TX')
ORDER BY state第一个查询使用WHERE子句限制需要求和的行数, 而第二个查询对表中的所有行求和, 然后使用HAVING丢弃其计算出的总和。在这种情况下, 使用WHERE子句的替代方法显然是更好的选择, 因为你不会浪费任何资源。
你会看到, 这与限制结果集无关, 而与限制查询中记录的中间数目有关。
请注意, 这两个子句之间的区别在于WHERE子句在单个行上引入了条件, 而HAVING子句在单个结果(如MIN, MAX, SUM, …是由多行产生的。
你会发现, 评估质量, 查询的编写和重写并不是一件容易的事, 要考虑到它们需要尽可能地提高性能。当你编写要在专业环境中的数据库上运行的查询时, 避免使用反模式并考虑使用替代方法也是责任之一。
此列表只是一些反模式和技巧的一小部分概述, 有望对初学者有所帮助;如果你想了解更多高级开发人员认为最常见的反模式, 请查看此讨论。
基于集合与过程的查询方法
上述反模式中隐含的一个事实是, 它们实际上归结为基于集合的方法与基于程序的方法建立查询的差异。
过程查询方法是一种与编程非常相似的方法:你告诉系统做什么和如何做。
这样的一个示例是联接中的冗余条件, 或者你滥用HAVING子句的情况(如上述示例), 其中你通过执行一个函数然后调用另一个函数来查询数据库, 或者使用包含循环, 条件的逻辑, 用户定义的函数(UDF), 游标……以获取最终结果。通过这种方法, 你经常会发现自己先询问数据的一个子集, 然后再从数据中请求另一个子集, 依此类推。
毫不奇怪, 这种方法通常称为”逐步”或”逐行”查询。
另一种方法是基于集合的方法, 你只需指定要执行的操作即可。你的角色包括指定要从查询中获取的结果集的条件或要求。如何检索数据, 你将保留确定查询实现的内部机制:让数据库引擎确定执行查询的最佳算法或处理逻辑。
由于SQL是基于集合的, 因此这种方法将比过程方法更加有效, 这不足为奇, 这也解释了为什么在某些情况下SQL可以比代码更快地工作。
提示基于集合的查询方法也是数据科学行业中大多数顶级雇主都会要求你掌握的一种方法!你通常需要在这两种类型的方法之间切换。
请注意, 如果发现自己遇到了过程查询, 则应考虑重写或重构它。
从查询到执行计划
知道反模式并不是一成不变的, 并且随着你作为SQL开发人员的成长而发展, 并且在考虑替代方案时要考虑很多因素, 这也就意味着避免查询反模式和重写查询会非常困难。任务。任何帮助都可以派上用场, 这就是为什么采用一些结构更优化的方法来优化查询的原因所在。
还要注意, 上一节中提到的某些反模式源自于性能问题, 例如AND, OR和NOT运算符以及它们缺乏索引用法。关于性能的思考不仅需要一种更加结构化的方法, 而且还需要一种更深入的方法。
无论如何, 这种结构化且深入的方法将主要基于查询计划, 如你所记得, 这是查询的结果, 该查询首先被解析为”解析树”, 并精确定义了用于什么算法每个操作以及如何协调操作执行。
查询优化
正如你在简介中所阅读的那样, 可能是你需要检查和调整由优化器手动生成的计划。在这种情况下, 你将需要通过查看查询计划来再次分析查询。
要掌握该计划, 你将需要使用数据库管理系统提供给你的工具。你可能会使用的一些工具如下:
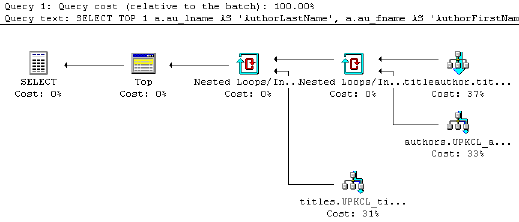
- 一些软件包具有一些工具, 这些工具将生成查询计划的图形表示。看一下这个例子:
- 其他工具将能够为你提供查询计划的文字描述。一个示例是Oracle中的EXPLAIN PLAN语句, 但是指令的名称根据你使用的RDBMS而有所不同。在其他地方, 你可能会发现EXPLAIN(MySQL, PostgreSQL)或EXPLAIN QUERY PLAN(SQLite)。
请注意, 如果你使用的是PostgreSQL, 则可以在EXPLAIN和EXPLAIN之间进行区别, 在EXPLAIN中, 你仅获得描述, 说明计划者打算如何在不运行查询的情况下执行查询, 而EXPLAIN ANALYZE实际上执行查询并返回到你可以对预期查询计划与实际查询计划进行分析。一般而言, 真正的执行计划是你实际运行查询的计划, 而估计的执行计划可以算出不执行查询将执行的操作。尽管从逻辑上讲是等效的, 但实际的执行计划更为有用, 因为它包含有关执行查询时实际发生的情况的更多详细信息和统计信息。
在本节的其余部分, 你将了解有关EXPLAIN和ANALYZE的更多信息, 以及如何使用这两个信息来了解有关你的查询计划和查询的可能性能的更多信息。为此, 你将从一些示例开始, 其中将使用两个表:one_million和half_million。
你可以在EXPLAIN的帮助下检索表one_million的当前信息。确保将其放在查询的最上方, 并且在运行查询时, 它会带给你查询计划:
EXPLAIN
SELECT *
FROM one_million;
QUERY PLAN
____________________________________________________
Seq Scan on one_million
(cost=0.00..18584.82 rows=1025082 width=36)
(1 row)在这种情况下, 你看到查询的成本为0.00..18584.82, 行数为1025082。则列数的宽度为36。
另外, 你还可以借助ANALYZE更新统计信息。
ANALYZE one_million;
EXPLAIN
SELECT *
FROM one_million;
QUERY PLAN
____________________________________________________
Seq Scan on one_million
(cost=0.00..18334.00 rows=1000000 width=37)
(1 row)除了EXPLAIN和ANALYZE, 你还可以借助EXPLAIN ANALYZE检索实际的执行时间:
EXPLAIN ANALYZE
SELECT *
FROM one_million;
QUERY PLAN
___________________________________________________________
Seq Scan on one_million
(cost=0.00..18334.00 rows=1000000 width=37)
(actual time=0.015..1207.019 rows=1000000 loops=1)
Total runtime: 2320.146 ms
(2 rows)在这里使用EXPLAIN ANALYZE的缺点显然是查询实际上是在执行的, 因此要小心!
到目前为止, 你所看到的所有算法都是Seq扫描(顺序扫描)或全表扫描:这是在数据库上进行的扫描, 其中, 被扫描表的每一行都是按顺序(序列)读取的, 并检查找到的列是否满足条件。关于性能, 顺序扫描绝对不是最佳的执行计划, 因为你仍在进行全表扫描。但是, 当表不能容纳到内存中时, 这还算不错:即使磁盘速度较慢, 顺序读取也可以很快进行。
稍后当你谈论索引扫描时, 你将看到更多有关此内容的信息。
但是, 还有其他一些算法。例如, 以下查询联接计划:
EXPLAIN ANALYZE
SELECT *
FROM one_million JOIN half_million
ON (one_million.counter=half_million.counter);
QUERY PLAN
_________________________________________________________________
Hash Join (cost=15417.00..68831.00 rows=500000 width=42)
(actual time=1241.471..5912.553 rows=500000 loops=1)
Hash Cond: (one_million.counter = half_million.counter)
-> Seq Scan on one_million
(cost=0.00..18334.00 rows=1000000 width=37)
(actual time=0.007..1254.027 rows=1000000 loops=1)
-> Hash (cost=7213.00..7213.00 rows=500000 width=5)
(actual time=1241.251..1241.251 rows=500000 loops=1)
Buckets: 4096 Batches: 16 Memory Usage: 770kB
-> Seq Scan on half_million
(cost=0.00..7213.00 rows=500000 width=5)
(actual time=0.008..601.128 rows=500000 loops=1)
Total runtime: 6468.337 ms你会看到查询优化器在这里选择了哈希联接!请记住此操作, 因为你将需要此操作来估计查询的时间复杂度。现在, 请注意, half_million.counter上没有索引, 你可以在下一个示例中添加该索引:
CREATE INDEX ON half_million(counter);
EXPLAIN ANALYZE
SELECT *
FROM one_million JOIN half_million
ON (one_million.counter=half_million.counter);
QUERY PLAN
________________________________________________________________
Merge Join (cost=4.12..37650.65 rows=500000 width=42)
(actual time=0.033..3272.940 rows=500000 loops=1)
Merge Cond: (one_million.counter = half_million.counter)
-> Index Scan using one_million_counter_idx on one_million
(cost=0.00..32129.34 rows=1000000 width=37)
(actual time=0.011..694.466 rows=500001 loops=1)
-> Index Scan using half_million_counter_idx on half_million
(cost=0.00..14120.29 rows=500000 width=5)
(actual time=0.010..683.674 rows=500000 loops=1)
Total runtime: 3833.310 ms
(5 rows)你会看到, 通过创建索引, 查询优化器现在决定在发生索引扫描的地方进行合并联接。
注意索引扫描和全表扫描或顺序扫描之间的区别:前者也称为”表扫描”, 它扫描数据或索引页以找到适当的记录, 而后者则扫描表的每一行。
你会看到总的运行时间有所减少, 性能应该会有所改善, 但是有两次索引扫描, 这使得内存在这里将变得更加重要, 尤其是在表不适合内存的情况下。在这种情况下, 你首先必须进行全索引扫描, 这是快速的顺序读取并且没有问题, 但是随后你需要进行大量随机读取才能按索引值获取行。这些随机读取通常比顺序读取要慢几个数量级。在这种情况下, 全表扫描确实比全索引扫描快。
提示:如果你想了解更多有关EXPLAIN的信息或更详细地查看示例, 请考虑阅读Guillaume Lelarge撰写的《 Understanding Explain》一书。
时间复杂度与大O
现在, 你已经简短地检查了查询计划, 你可以在计算复杂性理论的帮助下开始更深入地研究并以更正式的术语来考虑性能。在理论计算机科学领域, 该领域着重于根据计算问题的难度对计算问题进行分类;这些计算问题可以是算法, 也可以是查询。
但是, 对于查询, 你不一定要根据其难度对它们进行分类, 而要根据运行它并获得一些结果所需的时间进行分类。这明确地称为时间复杂度, 要表达或衡量这种类型的复杂度, 可以使用大O表示法。
使用大O表示法, 你可以根据输入随心所欲地变大, 相对于输入的增长速度来表示运行时。大号O表示法不包括系数和低阶项, 因此你可以专注于查询运行时间的重要部分:其增长率。当用下降系数和低阶项这样表示时, 时间复杂度被称为渐近描述。这意味着输入大小将变为无穷大。
用数据库语言来说, 复杂度衡量的是查询随着数据表(因此数据库)的大小增加而运行的时间。
请注意, 数据库的大小不仅会随着表中存储更多数据而增加, 而且仅仅是数据库中存在索引这一事实也对数据库的大小起作用。
估计查询计划的时间复杂度
如前所述, 执行计划除其他外定义了每个操作使用的算法, 这使得每个查询的执行时间都可以逻辑地表示为查询计划中涉及的表大小的函数。作为复杂度函数。换句话说, 你可以使用大O表示法和执行计划来估计查询的复杂性和性能。
在以下小节中, 你将获得关于四种类型的时间复杂度的一般概念, 并看到一些示例, 这些示例说明了查询的时间复杂度如何根据运行环境的不同而变化。
提示:索引是这里故事的一部分!
但是请注意, 要考虑的各种数据库有不同类型的索引, 不同的执行计划和不同的实现, 因此下面列出的时间复杂度非常普遍, 并且会根据你的特定设置而有所不同。
O(1):恒定时间
如果算法需要相同的时间量, 则无论输入大小如何, 都可以说算法以恒定时间运行。当你谈论查询时, 无论表大小如何, 它都需要相同的时间, 它将以固定的时间运行。
这类查询并非真正常见, 但是这里有一个这样的例子:
SELECT TOP 1 t.*
FROM t时间复杂度是恒定的, 因为你从表中选择了任意一行。因此, 时间的长度应与表的大小无关。
线性时间:O(n)
如果算法的时间执行与输入大小成正比, 则称该算法以线性时间运行, 即时间随着输入大小的增加而线性增长。对于数据库, 这意味着时间执行将与表大小直接成比例:随着表中行数的增加, 查询时间也将增加。
一个示例是在未索引列上带有WHERE子句的查询:将需要全表扫描或Seq扫描, 这将导致时间复杂度为O(n)。这意味着需要读取每一行以找到具有正确ID的行。你根本没有限制, 因此即使第一行符合条件, 也需要读取每一行。
还考虑下面的查询示例, 如果i_id上没有索引, 则查询的复杂度为O(n):
SELECT i_id
FROM item;- 前一个还表示其他查询, 例如COUNT(*)FROM TABLE之类的计数查询;时间复杂度为O(n), 因为除非存储表的总行数, 否则将需要进行全表扫描。那么, 复杂度将更像O(1)。
与线性执行时间紧密相关的是其中包含联接的执行计划的执行时间。这里有些例子:
- 哈希联接的预期复杂度为O(M + N)。用于两个表的内部联接的经典哈希联接算法首先准备较小表的哈希表。哈希表条目由join属性及其行组成。通过将哈希函数应用于join属性来访问哈希表。一旦构建了哈希表, 就可以扫描较大的表, 并通过在哈希表中查找来找到较小表中的相关行。
- 合并联接通常具有O(M + N)的复杂度, 但它在很大程度上取决于联接列上的索引, 并且在没有索引的情况下, 取决于行是否根据联接中使用的键进行排序:
- 如果两个表均根据联接中使用的键排序, 则查询的时间复杂度为O(M + N)。
- 如果两个表在连接的列上都有索引, 则该索引已经按顺序维护了这些列, 因此无需排序。复杂度将为O(M + N)。
- 如果两个表都没有在连接的列上有索引, 则两个表都必须首先出现, 这样复杂度才更像O(M log M + N log N)。
- 如果只有一个表在连接的列上有索引, 则只有一个没有索引的表才需要在合并步骤发生之前进行排序, 以使复杂度看起来像O(M + N log N )。
- 对于嵌套联接, 复杂度通常为O(MN)。当一个或两个表都非常小时(例如, 小于10条记录), 这种连接非常有效, 这在评估查询时非常常见, 因为写入某些子查询只返回一行。
请记住:嵌套联接是将一个表中的每个记录与另一个表中的每个记录进行比较的联接。
对数时间:O(log(n))
如果算法的时间执行与输入大小的对数成正比, 则称该算法以对数时间运行。对于查询, 这意味着如果执行时间与数据库大小的对数成正比, 它们将运行。
对于执行索引扫描或聚集索引扫描的查询计划, 此对数时间复杂度是正确的。聚集索引是一个索引, 其中索引的叶级别包含表的实际数据行。聚簇很像任何其他索引:它在一个或多个列上定义。这些构成索引键。然后, 聚类键是聚簇索引的键列。基本上, 聚集索引扫描就是RDBMS读取聚集索引中从上至下的一行或多行的操作。
考虑以下查询示例, 其中在i_id上有一个索引, 通常会导致O(log(n))的复杂性:
SELECT i_stock
FROM item
WHERE i_id = N; 注意, 没有索引, 时间复杂度将为O(n)。
二次时间:O(n ^ 2)
如果算法的时间执行与输入大小的平方成正比, 则称该算法以二次时间运行。再次, 对于数据库, 这意味着查询的执行时间与数据库大小的平方成正比。
以下是一个具有二次时间复杂度的查询的可能示例:
SELECT *
FROM item, author
WHERE item.i_a_id=author.a_id 根据连接属性的索引信息, 最小复杂度为O(n log(n)), 但是最大复杂度为O(n ^ 2)。
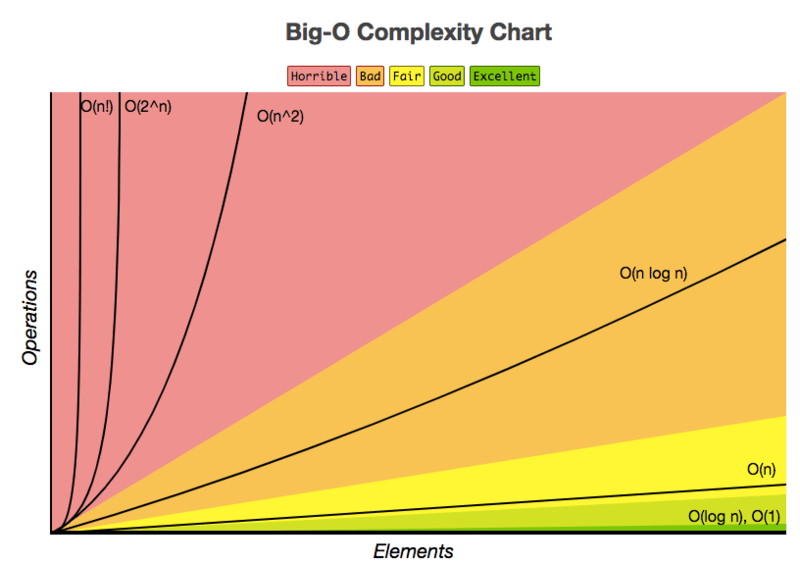
总而言之, 你还可以查看以下备忘单, 根据其时间复杂度以及它们的执行情况来估算查询的性能:
SQL调优
考虑到查询计划和时间复杂性, 你可以考虑进一步调整SQL查询。你可以首先特别注意以下几点:
- 用索引扫描替换不必要的大表全表扫描;
- 确保你正在应用最佳的表连接顺序;
- 确保最佳使用索引;和
- 缓存小表全表扫描。
使SQL更进一步
恭喜!你已经到了本博文的结尾, 这只是让你了解了SQL查询性能。希望你对反模式, 查询优化器以及可用于查看, 估计和解释查询计划的复杂性的工具有更多的了解。但是, 还有更多发现!如果你想了解更多信息, 请考虑阅读R. Ramakrishnan和J. Gehrke撰写的” Database Management Systems”一书。
最后, 我不想让你从StackOverflow用户处获得以下报价:
“我最喜欢的反模式不是测试你的查询。在以下情况下适用:查询涉及多个表。你认为自己有一个针对查询的最佳设计, 但不必费力去检验你的假设。你接受第一个有效的查询, 不知道它是否接近优化。
如果你想开始使用SQL, 请考虑参加srcmini的SQL for Data Science入门课程!
评论前必须登录!
注册