 srcmini
srcmini本文概述
机器学习的前景已在许多领域显示出许多惊人的结果。自然语言处理也不例外, 它是机器学习能够显示通用人工智能(不完全但至少部分地)实现真正复杂任务的出色结果的领域之一。
现在, NLP(自然语言处理)已经不是一个新领域, 机器学习也不是一个新领域。但是, 这两个领域的融合是非常现代的, 并且只誓要取得进展。这是每个人(带有智能手机)每天都会遇到的那些混合应用程序之一。例如, 将”键盘单词建议”纳入帐户, 或智能自动填充;这些都是NLP和机器学习合并的副产品, 很自然地, 这些已成为我们生活中不可分割的部分。
情感分析是自然语言处理领域的重要课题。由于它的相关性以及它正在解决并且能够回答的业务问题的数量, 它很容易成为该领域最热门的主题之一。在本教程中, 你将以简单的方式介绍这个不太简单的主题。你将分解所有背后的小数学, 然后学习。你还将在本教程的结尾构建一个简单的情感分类器。具体来说, 你将学习:
- 从从业者的角度了解情绪分析
- 制定情感分析的问题陈述
- 朴素贝叶斯分类用于情感分析
- Python案例研究
- 情绪分析如何影响多个业务领域
- 关于该主题的进一步阅读
让我们开始吧。
资料来源:medium
什么是情绪分析-从业者的观点
本质上, 情感分析或情感分类属于文本分类任务的广义类别, 其中为你提供了短语或短语列表, 并且你的分类器应告诉你背后的情感是正面的, 负面的还是中立的。有时, 不采用第三个属性来将其保留为二进制分类问题。在最近的任务中, 也考虑了”有点积极”和”有点消极”等情绪。现在让我们看一个例子。
请考虑以下短语:
- “泰坦尼克号是一部很棒的电影。”
- “泰坦尼克号不是一部好电影。”
- “泰坦尼克号是电影。”
这些短语对应于简短的电影评论, 并且每个短语传达不同的情感。例如, 第一个短语表示对电影《泰坦尼克号》的正面情绪, 而第二个短语则认为电影不那么好(负面情绪)。仔细看看第三个。该短语中没有这样的词可以告诉你有关它传达的情感的任何信息。因此, 这是中立情绪的一个例子。
现在, 从严格的机器学习的角度来看, 此任务不过是监督学习任务。你将为机器学习模型提供一堆短语(带有各自情感的标签), 并在未标记的短语上测试模型。
仅介绍情绪分析应该很好, 但是要能够建立情绪分类模型, 你还需要更多。让我们继续。
资料来源:SlideShare
制定情感分析的问题陈述
在理解情感分类任务的问题陈述之前, 你需要对常规文本分类问题有一个清晰的认识。让我们正式定义一般文本分类任务的问题。
- 输入:文档d一组固定的类C = {c1, c2, .., cn}
- 输出:预测类c $ \ in $ C
这里的文档术语是主观的, 因为在文本分类世界中。对于文档, 它是指推文, 短语, 新闻文章的一部分, 整个新闻文章, 全文, 产品手册, 故事等。该术语背后的原因是单词, 它是一个原子实体, 在这种情况下很小。因此, 为了表示较大的单词序列, 通常使用此术语文档。推文表示文档较短, 而文章则表示文档较大。
因此, 具有n个标记文档的训练集看起来像:(d1, c1), (d2, c2), …, (dn, cn), 最终输出是一个学习的分类器。
你做得好!但是, 此时你必须要解决的一个问题是文档的功能在哪里?正品问题!稍后你将了解。
现在, 让我们继续进行问题表述, 并慢慢建立情感分类背后的直觉。
在进行情感分析时, 你需要牢记的一个关键点是, 短语中的所有单词都不能传达该短语的情感。诸如” I”, ” Are”, ” Am”之类的词不会有助于传达任何类型的情感, 因此, 它们在情感分类上下文中不是相对的。在这里考虑特征选择的问题。在功能选择中, 你尝试找出与类别标签最相关的最相关功能。同样的想法在这里也适用。因此, 短语中只有少数单词会参与其中, 识别它们并将其从短语中提取出来是一项艰巨的任务。但请放心, 你会做到的。
考虑以下电影评论以更好地理解这一点:
“我喜欢这部电影!很甜蜜, 但充满讽刺的幽默。对话很棒, 冒险场景很有趣。在嘲笑童话流派的惯例时, 它变得浪漫而异想天开。任何人。我已经看过好几次了, 我总是很高兴再次看到它……。”
是的, 毫无疑问, 这是对特定电影的正面评价。但是, 哪些具体词定义了这种积极性?
重新看一下评论。
“我喜欢这部电影!很甜蜜, 但充满讽刺的幽默。对话很棒, 冒险场景很有趣。在嘲笑童话流派的惯例时, 它变得浪漫而异想天开。任何人。我已经看过好几次了, 我很高兴再次看到它……。”
你现在必须已经清楚了。上面的文本中的粗体词是最重要的词, 它们构成了文本传达的情感的积极性质。
这些话怎么办?似乎很自然的下一步是创建类似于以下内容的表示形式:
那么上述表示在做什么呢?你已经猜对了。每行都包含一个单词及其在文档中出现的频率(从现在起, 我们称其为文档)。你还想知道爱情只出现过一次, 但为什么频率是2?好吧, 这是整个审查的一部分。考虑一下, 代表是整个审查。
在制定情感分类任务的问题陈述时, 你理解了”单词袋”表示, 而以上表示仅是单词袋表示。这可能是NLP中最基本的概念, 并且是进行任何文本分类问题的第一步。因此, 请确保你了解它。
文档的单词袋表示不仅包含特定单词, 而且包含文档中所有唯一的单词及其出现频率。袋子在这里是数学集合, 因此根据集合的定义, 袋子不包含任何重复的单词。
但是对于此应用程序, 你只对前面提到的粗体字感兴趣, 因此本文档的词袋将仅包含这些词。
文档不是以混乱的方式编写的。是吗文档中的单词顺序至关重要。但是在情感分类的背景下, 这个顺序不是很重要。这些词的存在是这里最重要或最重要的部分。
你在单词袋中找到的单词现在将构成文档的功能集。因此, 请考虑将你作为许多电影评论(文档)的集合, 并为每个电影评论(文档)创建了词袋表示并保留了它们的标签(在这种情况下, 即-ve或-ve)。你的训练集应如下所示:
这种表示形式也称为语料库。
此培训集应该易于理解-
所有行都是独立的特征向量, 其中包含有关特定文档(电影评论), 特定单词及其情感的信息。注意, 标签情感通常表示为(+, -)或(+ ve, -ve)。同样, 特征w1, w2, w3、34, …, wn是由一袋单词生成的, 并且没有必要所有文档都包含这些特征/单词中的每一个。
你会将这些特征向量传递给分类器。因此, 让我们接下来进行研究-用于情感分类的朴素贝叶斯分类模型。
朴素贝叶斯分类用于情感分析
朴素贝叶斯分类只不过是应用贝叶斯规则来形成分类概率。在本节中, 你将从情感分类的上下文研究朴素贝叶斯分类器。强烈建议获得有关朴素贝叶斯分类和贝叶斯规则的一些介绍。该资源如下:
- Beginning Bayes in R (practice)
- 学习朴素贝叶斯算法的6个简单步骤
但是, 为什么世界上的朴素贝叶斯k-NN, 决策树和许多其他树呢?稍后你将了解。
首先, 让我们在朴素贝叶斯分类器中建立情感分类的通用术语概念。你将首先看一下贝叶斯规则:
- 对于文档d和类c:
资料来源:情绪分析
在这种情况下, 该类别包括两个观点。正面及负面。
在这种情况下, 让我们详细研究上图中的每个术语。
- 在给定文档d的情况下, 将RHS项P(c | d)视为c类的概率。此术语也称为后验。
- P(d | c)应该相似。
现在, 这些先验和可能性是什么?同样, 术语P(d)(文档的概率);听起来荒唐吗?宝石的问题!让我们现在找到答案!
- 显示为”优先”的术语是你的原始信念, 即, 文档的原始标签是正面的还是负面的(在情感方面)。
- 术语可能性是给定类别c的文件d的概率。
- 现在, 将”后验”一词视为你通过乘以”先验”和”可能性”而获得的更新规则或更新信念。
- 但是什么是归一化常数P(d)?该项除以乘积产生的结果, 以确保结果可以概率分布表示。
到目前为止还不是最好的细节!但是要坚持下去。你将发现更多信息。但是请记住, 你仍在建立与情感分类相关的贝叶斯规则的直觉。
让我们深入了解更多细节, 以找出贝叶斯规则在此试图做的事情。下图显示了贝叶斯规则的更详细步骤:

资料来源:情绪分析
这里有很多未知术语。让我们慢慢来。
让我们从RHS术语cMAP开始。它在这里表示贝叶斯规则的主要目标, 即找出属于特定类别的特定文档的最大后验概率/估计。 MAP是希腊语术语Max A Posteriori的缩写。
什么是argmax?你可能只使用了max!
- 好吧, argmax表示索引。假设P(+ | d)> P(-| d), 其中+和-分别表示正面和负面情绪。这些项P(+ | d), P(-| d)返回为数字量的概率。但是, 你对概率不感兴趣, 对找出P(+ | d)更大的类感兴趣, 而argmax返回该类。对于P(+ | d)> P(-| d), argmax将返回+。
是的, 你可以删除分母项P(d)。这完全取决于实现。
但是如何找出$ P(d | c)$和$ P(c)$?这正是一堆方便的用词。但是如何?
继续阅读!
你已经知道如何将给定的文档转换为单词表示袋。更重要的是, 你可以以此将文档表示为一组功能。因此, 现在, 术语cMAP基本上可以写成(忽略分母项P(d)):
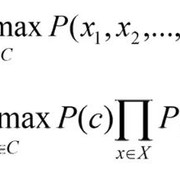
资料来源:情绪分析
但是, 你如何真正计算概率呢?让我们先从$ P(c)$开始。
P(c)基本上与以下问题有关:”此类发生的频率是多少?”假设你的文档数据集包含60%的积极情绪和40%的消极情绪。因此, $ P(+)= 0.6 $和$ P(-)= 0.4 $。
现在, 你如何解释这个术语:P(x1, x2, …, xn | c)?
这样想-给定类c, 出现这些单词(特征)的概率是多少?例如, 假设你有1000个文档, 并且语料库中只有两个单词-“好”和”很棒”。现在, 在这1000个文档中, 有500个文档被标记为正, 其余的500个文档被标记为负。此外, 你还发现在500个带有正面标签的文档中, 有200个文档同时包含”好”和”很棒”(请注意P(x1, x2)表示P(x1和x2))。因此, 概率P(good, awesome | +)= 200/1000 = 1/5。
你想在此处提出的一个重要观点是, 如果你的词汇量是$ X $, 则只要你的文档包含n个单词, 你就可以公式化Xn可能性(例如P(good, awesome | +))。
请记住, 你必须在这里计算两个类的似然概率。因此, 如果你有2000个总单词并且每个文档平均包含20个单词的情况下, 组合的总数将为(2000)20。这个数字非常大!而且如果语料库大小为数百万(在实际情况下确实会发生这种情况)怎么办?
这称为贝叶斯分类器。但是它只是不起作用, 因为计算量太多了。现在, 你将研究使Bayes分类器成为Naive Bayes分类器的一些假设。
你将要研究的假设称为朴素贝叶斯独立假设。它们如下:
P(x1, x2, …, xn | c)
-言语假设:假设位置无关紧要。假设一个特定的单词出现在第10位和第20位, 但是使用此假设, 这意味着你只关心该单词出现的频率为2。10和12这两个数字在这里无关紧要。
-条件独立性假设:这是使贝叶斯分类器为朴素贝叶斯的关键假设。它指出”假设特征概率P(xi | cj)”。仔细看看该声明。这意味着P(x1 | cj), P(x2 | cj)等彼此独立。 (这并不意味着P(x1), P(x2)等彼此独立)现在, 术语P(x1, x2, …, xn | c)可以表示如下:
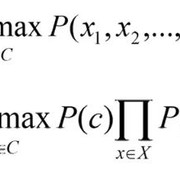
资料来源:情绪分析
因此, 自然地, Xn组合将减少为Xn, 而Xn则成倍减小(如果你的词汇量是$ X $并且你的文档包含n个单词)。从数学上定义, 贝叶斯分类器简化为朴素贝叶斯分类器时看起来像:
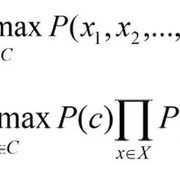
资料来源:情绪分析
朴素贝叶斯有两个优点:
- 减少参数数量。
- 线性时间复杂度与指数时间复杂度相反。
朴素贝叶斯分类机制应用于文本分类问题时, 被称为”多项朴素贝叶斯”分类。
现在, 你非常容易理解Naive Bayes分类器的机制, 尤其是对于情感分类问题。现在, 是时候实现情绪分类器了。
你将使用Python做到这一点!让我们开始案例研究。
Python中的简单情感分类器
对于此案例研究, 你将使用NLTK本书中涵盖的离线电影评论语料库, 并可从此处下载。 nltk提供了数据集的版本。数据集将每个评论分类为肯定或否定。你需要先下载该文件, 如下所示:
python -m nltk.downloader all
不建议从Jupyter Notebook运行它。尝试从命令提示符下运行它(如果使用Windows)。需要一些时间。因此, 请耐心等待。
有关NLTK数据集的更多信息, 请确保你访问此链接。
你将实现朴素贝叶斯(Naive Bayes)或使用NLTK(代表自然语言工具包)的Multinomial Naive Bayes分类器。它是一个专门用于NLP和NLU相关任务的库, 文档非常好。它涵盖了许多技术, 并为实验提供了免费的数据集。
这是NLTK的官方网站。确保你检查出它, 因为它有一些关于NLP的精心编写的教程, 涵盖了不同的NLP概念。
下载所有数据后, 你将从nltk.corpus import movie_reviews导入电影评论数据集开始。然后, 你将构建一个文档列表, 并用适当的类别标记。
# Load and prepare the dataset
import nltk
from nltk.corpus import movie_reviews
import random
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
接下来, 你将定义文档的特征提取器, 以便分类器也将知道应该注意数据的哪些方面。 “在这种情况下, 你可以为每个单词定义一个特征, 以指示文档是否包含该单词。要限制分类器需要处理的特征数量, 请从构建总共2000个最常用单词的列表开始语料库”。然后, 你可以定义一个特征提取器, 该特征提取器仅检查给定文档中是否存在这些单词。
# Define the feature extractor
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
word_features = list(all_words)[:2000]
def document_features(document):
document_words = set(document)
features = {}
for word in word_features:
features['contains({})'.format(word)] = (word in document_words)
return features
“你计算文档中所有单词的集合的原因document_words = set(document), 而不仅仅是检查文档中的单词, 是检查一个单词是否出现在集合中比检查它是否出现要快得多在列表中”-来源。
你已经定义了特征提取器。现在, 你可以使用它来训练朴素贝叶斯分类器, 以预测新电影评论的情绪。要检查分类器的性能, 你将在测试集上计算其准确性。 NLTK提供了show_most_informative_features()来查看分类器提供最多信息的功能。
# Train Naive Bayes classifier
featuresets = [(document_features(d), c) for (d, c) in documents]
train_set, test_set = featuresets[100:], featuresets[:100]
classifier = nltk.NaiveBayesClassifier.train(train_set)
# Test the classifier
print(nltk.classify.accuracy(classifier, test_set))
0.71
哇!分类器甚至无需调整任何参数或进行微调就可以达到71%的精度。这是第一次尝试的好方法!
# Show the most important features as interpreted by Naive Bayes
classifier.show_most_informative_features(5)
Most Informative Features
contains(winslet) = True pos : neg = 8.4 : 1.0
contains(illogical) = True neg : pos = 7.6 : 1.0
contains(captures) = True pos : neg = 7.0 : 1.0
contains(turkey) = True neg : pos = 6.5 : 1.0
contains(doubts) = True pos : neg = 5.8 : 1.0
“在数据集中, 提及”不合逻辑”的评论被否定的可能性比正面的可能性高近8倍, 而提及”捕获”的评论被正面评价的可能性大约是正则的6倍”-资料来源。
现在的问题-为什么是朴素贝叶斯?
- 你选择研究朴素贝叶斯是因为它的设计和开发方式。文本数据具有一些实用和复杂的功能, 如果你不考虑神经网络, 则最好将其映射到朴素贝叶斯。此外, 它易于解释, 并且不会创建黑盒模型的概念。
朴素贝叶斯也有某些缺点:
朴素贝叶斯的主要限制是独立预测变量的假设。在现实生活中, 几乎不可能获得一组完全独立的预测变量。
为什么情感分析如此重要?
情绪分析解决了许多真正的业务问题:
- 它有助于预测特定产品的客户行为。
- 它可以帮助测试产品的适应性。
- 自动执行客户偏好报告任务。
- 通过分析来自多个平台的电影评论背后的情绪, 它可以轻松地自动确定电影的效果。
- 还有很多!
恭喜你!你已经做到了最后。 NLP是一个非常广泛且有趣的主题, 它解决了一些具有挑战性的问题。具体来说, NLP和深度学习的交集催生了一些出色的产品。它彻底改变了聊天机器人交互的方式。清单永无止境。
希望本教程可以让你在NLP的主要子领域之一(即情感分析)中抢先一步。你涵盖了NLP的最基本主题之一-单词袋, 然后详细研究了朴素贝叶斯分类器。你还检查了它的缺点。你使用了nltk, 这是用于NLP和NLU任务的最受欢迎的Python库之一。你使用nltk提供的电影语料库实现了一个简单的Naive Bayes分类器。鼓掌。你应得的!
如果你想从这个卑微的起点开始走远, 那么下面是一些神奇资源的链接:
- 研究有关NLP及其不同工具/技术的更多信息
- 一般研究文本数据
- 研究递归神经网络
- 通过深度学习了解NLP的一些惊人应用
为了创建本教程, 使用了以下参考资料:
- 文本分类和朴素贝叶斯
- 使用深度学习从电影评论中预测情感
- NLTK书
- NLP基础
如果你有兴趣学习NLP的基础知识并将其应用于实际数据集, 则可以参加srcmini的” Python自然语言处理基础知识”课程。
评论前必须登录!
注册