 srcmini
srcmini本文概述
如果你熟悉机器学习, 则可能会在许多数据集中遇到分类特征。这些通常包括与观测值相关的不同类别或级别, 这些类别或级别是非数字的, 因此需要进行转换, 以便计算机可以对其进行处理。
在本教程中, 你将学习处理此类数据并对其进行预处理以使用它们构建机器学习模型的常见技巧。更具体地说, 你将学习:
- 数据集中的分类数据和连续数据与标识数据类型之间的区别。
- 对此类数据进行基本研究以从中提取信息。
- 你将在机器学习中学习更多有关Python中分类数据的各种编码技术。
- 最后, 你将研究如何使用Spark处理大数据中的分类功能:你将了解如何在PySpark中应用编码技术。
本教程介绍了可用于ML算法之前对分类数据执行的操作。但是还有更多。你还必须清理数据。如果你想了解有关此过程的更多信息, 请务必阅读srcmini的Python清洗数据课程。
识别分类数据:名义, 有序和连续
分类特征只能采用有限数量的(通常是固定的)可能的值。例如, 如果数据集是关于与用户有关的信息的, 那么通常你会发现诸如国家, 性别, 年龄段等的特征。或者, 如果你正在使用的数据与产品有关, 则将发现诸如产品的特征。类型, 制造商, 卖方等。
这些都是数据集中的分类特征。这些特征通常存储为代表观察结果各种特征的文本值。例如, 性别描述为男性(M)或女性(F), 产品类型可以描述为电子产品, 服装, 食品等。
请注意, 仅对类别进行标记而没有任何优先顺序的这些类型的要素称为名义要素。
与它们有一定顺序相关联的特征称为序数特征。例如, 具有经济状况之类的功能具有三个类别:低, 中和高, 它们具有与之相关的顺序。
也有连续的功能。这些是数字变量, 在任何两个值之间具有无限数量的值。连续变量可以是数字或日期/时间。
无论使用什么值, 由于以下限制, 挑战在于确定如何在分析中使用此数据:
- 分类要素可能具有非常多的级别(称为高基数)(例如, 城市或URL), 其中大多数级别出现在相对较少的实例中。
- 许多机器学习模型(例如回归或SVM)都是代数的。这意味着它们的输入必须为数字。要使用这些模型, 必须先将类别转换为数字, 然后才能对它们应用学习算法。
- 虽然某些ML软件包或库可能会基于某些默认嵌入方法自动将分类数据转换为数字, 但许多其他ML软件包不支持此类输入。
- 对于机器, 分类数据不包含人类可以轻松关联和理解的相同上下文或信息。例如, 当查看具有三个城市纽约, 新泽西和新德里的城市时, 人们可以推断出纽约与新泽西州密切相关, 因为它们来自同一国家, 而纽约和新德里则有很大不同。但是对于模型而言, 纽约, 新泽西和新德里只是同一要素城市的三个不同级别(可能的值)。如果你未指定其他上下文信息, 则该模型将无法区分高度不同的级别。
因此, 你面临的挑战是弄清楚如何将这些文本值转换为数值以进行进一步处理, 并隐藏这些功能可能隐藏的许多有趣信息。通常, 要素工程中的任何标准工作流程都涉及将这些分类值转换为数字标签的某种形式, 然后对这些值应用某种编码方案。
分类数据的一般研究步骤
在本节中, 你将重点处理pnwflights14数据集中的分类特征, 但是你可以对所有类型的数据集应用相同的过程。 pnwflights14是Hadley Wickham的nycflights13数据集的修改版本, 其中包含2014年从太平洋西北(PNW), 西雅图的SEA和波特兰的PDX的两个主要机场出发的所有航班的信息:总计162, 049班次。
为了帮助理解造成延迟的原因, 它还包括许多其他有用的数据集:
- 天气:每个机场的每小时气象数据
- planes:有关每个平面的构造函数信息
- 机场:机场名称和位置
- 航空公司:两个字母航空公司代码和名称之间的转换
数据集可以在这里找到。
由于在开始进行操作之前始终先了解它是一个好主意, 因此你将简要地研究数据!为此, 你将首先导入将在整个教程中使用的基本库, 即pandas, numpy和copy。
还要确保将Matplotlib设置为内联绘图, 这意味着输出的绘图将立即显示在每个代码单元下方。
import pandas as pd
import numpy as np
import copy
%matplotlib inline
接下来, 你将使用read_csv()在pandas DataFrame中读取航班数据集, 并使用.head()方法检查内容。
df_flights = pd.read_csv('https://raw.githubusercontent.com/ismayc/pnwflights14/master/data/flights.csv')
df_flights.head()

你可能会注意到, 上面的DataFrame包含有关航班的各种信息, 例如年份, 出发延迟, 到达时间, 承运人, 目的地等。
请注意, 如果你正在读取RDS文件格式, 则可以通过安装rpy2库来实现。签出此链接以在系统上安装该库。安装库的最简单方法是在命令行终端上使用pip install rpy2命令。
运行以下代码将读取flights.RDS文件并将其加载到pandas DataFrame中。请记住, 你之前已经导入了熊猫。
import rpy2.robjects as robjects
from rpy2.robjects import pandas2ri
pandas2ri.activate()
readRDS = robjects.r['readRDS']
RDSlocation = 'Downloads/datasets/nyc_flights/flights.RDS' #location of the file
df_rds = readRDS(RDSlocation)
df_rds = pandas2ri.ri2py(df_rds)
df_rds.head(2)

相同的rpy2库也可以用于读取rda文件格式。下面的代码读取flights.rda并将其加载到pandas DataFrame中:
from rpy2.robjects import r
import rpy2.robjects.pandas2ri as pandas2ri
file="~/Downloads/datasets/nyc_flights/flights.rda" #location of the file
rf=r['load'](file)
df_rda=pandas2ri.ri2py_dataframe(r[rf[0]])
df_rda.head(2)

下一步是收集有关DataFrame中不同列的一些信息。你可以通过使用.info()来实现, 它基本上为你提供有关行数, 列数, 列数据类型, 内存使用率等的信息。
print(df_flights.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 162049 entries, 0 to 162048
Data columns (total 16 columns):
year 162049 non-null int64
month 162049 non-null int64
day 162049 non-null int64
dep_time 161192 non-null float64
dep_delay 161192 non-null float64
arr_time 161061 non-null float64
arr_delay 160748 non-null float64
carrier 162049 non-null object
tailnum 161801 non-null object
flight 162049 non-null int64
origin 162049 non-null object
dest 162049 non-null object
air_time 160748 non-null float64
distance 162049 non-null int64
hour 161192 non-null float64
minute 161192 non-null float64
dtypes: float64(7), int64(5), object(4)
memory usage: 19.8+ MB
None
如你所见, 诸如年, 月和日之类的列被读取为整数, 而dep_time, dep_delay等被读取为浮点数。
具有对象dtype的列是数据集中可能的分类特征。
之所以说这些分类特征是”可能的”, 是因为你不应该完全依赖.info()来获取特征值的真实数据类型, 因为某些缺失值用字符串表示在连续功能中, 可以强制将其读取为对象dtype。
这就是为什么彻底调查原始数据集然后考虑对其进行清理始终是一个好主意的原因。
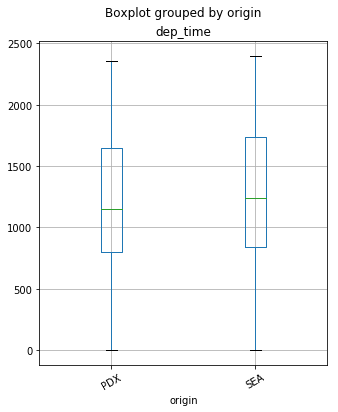
分析分类特征和连续特征之间关系的最常见方法之一是绘制箱线图。箱线图是表示图表上统计数据的一种简单方法, 其中绘制了一个矩形来表示第二个和第三个四分位数, 通常内部带有一条垂直线来表示中位数。下部和上部四分位数显示为矩形任一侧的水平线。
你可以通过在DataFrame上调用.boxplot()来绘制箱形图。在这里, 你将针对来自PDX和SEA的航班的两个起点绘制dep_time列的箱线图。
df_flights.boxplot('dep_time', 'origin', rot = 30, figsize=(5, 6))
<matplotlib.axes._subplots.AxesSubplot at 0x7f32ee10f550>
由于在本教程中你将只处理分类功能, 因此最好将它们过滤掉。你可以通过运行以下命令来创建仅包含这些功能的单独的DataFrame。在此使用方法.copy(), 以便对新DataFrame所做的任何更改都不会反映在原始DataFrame中。
cat_df_flights = df_flights.select_dtypes(include=['object']).copy()
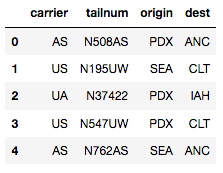
再次, 使用.head()方法检查是否已过滤所需的列。
cat_df_flights.head()
最常见的数据预处理步骤之一是检查数据集中的空值。你可以通过以下一个内胆代码获取DataFrame中缺少值的总数:
print(cat_df_flights.isnull().values.sum())
248
我们还检查一下空值的按列分布:
print(cat_df_flights.isnull().sum())
carrier 0
tailnum 248
origin 0
dest 0
dtype: int64
似乎只有tailnum列具有空值。你可以为这些空值进行模式插补。函数fillna()对于此类操作非常方便。
请注意以下代码中方法.value_counts()的链接。这将返回功能中每个类别的频率分布, 然后选择具有.index属性的顶部类别(即模式)。
cat_df_flights = cat_df_flights.fillna(cat_df_flights['tailnum'].value_counts().index[0])
提示:在这里阅读更多有关与方法链的联系。
让我们检查插补后的零值数量是否为零。
print(cat_df_flights.isnull().values.sum())
0
你可能要对分类要素执行的另一项研究性数据分析(EDA)步骤是要素内类别的频率分布, 这可以使用.value_counts()方法完成, 如前所述。
print(cat_df_flights['carrier'].value_counts())
AS 62460
WN 23355
OO 18710
DL 16716
UA 16671
AA 7586
US 5946
B6 3540
VX 3272
F9 2698
HA 1095
Name: carrier, dtype: int64
要了解功能中不同类别的数量, 你可以使用.count()方法将先前的代码链接起来:
print(cat_df_flights['carrier'].value_counts().count())
11
视觉研究是提取变量之间信息的最有效方法。
以下是一个基本模板, 用于使用seaborn软件包绘制分类特征的频率分布的条形图, 其中显示了载波列的频率分布。你可以使用不同的参数来更改绘图的外观。如果你想了解有关seaborn的更多信息, 可以看一下本教程。
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
carrier_count = cat_df_flights['carrier'].value_counts()
sns.set(style="darkgrid")
sns.barplot(carrier_count.index, carrier_count.values, alpha=0.9)
plt.title('Frequency Distribution of Carriers')
plt.ylabel('Number of Occurrences', fontsize=12)
plt.xlabel('Carrier', fontsize=12)
plt.show()

同样, 你可以使用matplotlib库绘制饼图以获取相同的信息。下面的标签列表包含载体列中的类别名称:
labels = cat_df_flights['carrier'].astype('category').cat.categories.tolist()
counts = cat_df_flights['carrier'].value_counts()
sizes = [counts[var_cat] for var_cat in labels]
fig1, ax1 = plt.subplots()
ax1.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True) #autopct is show the % on plot
ax1.axis('equal')
plt.show()

编码分类数据
现在, 你将学习不同的技术, 以将分类特征编码为数值。为简单起见, 你将仅在载体列上应用这些编码方法。但是, 可以将相同的方法扩展到所有列。
你将介绍的技术如下:
- 替换值
- 编码标签
- 一键编码
- 二进制编码
- 后向差异编码
- 杂项功能
替换值
让我们从最基本的方法开始, 该方法只是将类别替换为所需的数字。可以借助pandas中的replace()函数来实现。想法是, 你可以根据业务用例自由选择要分配给类别的任何数字。
现在, 你将创建一个词典, 其中包含运营商列中每个类别的映射号:
replace_map = {'carrier': {'AA': 1, 'AS': 2, 'B6': 3, 'DL': 4, 'F9': 5, 'HA': 6, 'OO': 7 , 'UA': 8 , 'US': 9, 'VX': 10, 'WN': 11}}
请注意, 当类别数较少时(例如在这种情况下为11), 通过硬编码字典定义映射很容易。你可以借助字典理解来实现相同的映射, 如下所示。当类别计数很高并且你不想键入每个映射时, 这将很有用。你将类别名称存储在名为标签的列表中, 然后将其压缩为一个数字序列并对其进行迭代。
labels = cat_df_flights['carrier'].astype('category').cat.categories.tolist()
replace_map_comp = {'carrier' : {k: v for k, v in zip(labels, list(range(1, len(labels)+1)))}}
print(replace_map_comp)
{'carrier': {'AA': 1, 'OO': 7, 'DL': 4, 'F9': 5, 'B6': 3, 'US': 9, 'AS': 2, 'WN': 11, 'VX': 10, 'HA': 6, 'UA': 8}}
在整个教程中, 你将通过.copy()方法制作数据集的副本, 以练习每种编码技术, 以确保原始DataFrame保持完整, 并且你所做的任何更改仅在复制的副本中发生。
cat_df_flights_replace = cat_df_flights.copy()
通过将映射字典作为参数, 在DataFrame上使用replace()函数:
cat_df_flights_replace.replace(replace_map_comp, inplace=True)
print(cat_df_flights_replace.head())
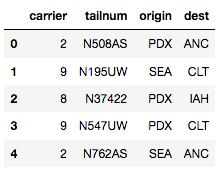
如你所见, 你已经在DataFrame中使用映射的数字对类别进行了编码。
你还可以检查新编码的列的dtype, 该列现在已转换为整数。
print(cat_df_flights_replace['carrier'].dtypes)
int64
提示:在Python中, 将分类特征类型转换为类别dtype是一个好习惯, 因为它们使此类列上的操作比对象dtype快得多。你可以通过在列上使用.astype()方法进行类型转换, 如下所示:
cat_df_flights_lc = cat_df_flights.copy()
cat_df_flights_lc['carrier'] = cat_df_flights_lc['carrier'].astype('category')
cat_df_flights_lc['origin'] = cat_df_flights_lc['origin'].astype('category')
print(cat_df_flights_lc.dtypes)
carrier category
tailnum object
origin category
dest object
dtype: object
你可以通过使用时间库对列为类别dtype和对象dtype的列上的DataFrame进行相同操作的执行时间, 来验证类别dtype的更快操作。
假设你要计算每个始发地的每个承运人的飞行次数, 可以在DataFrame上使用.groupby()和.count()方法来执行此操作。
import time
%timeit cat_df_flights.groupby(['origin', 'carrier']).count() #DataFrame with object dtype columns
10 loops, best of 3: 28.6 ms per loop
%timeit cat_df_flights_lc.groupby(['origin', 'carrier']).count() #DataFrame with category dtype columns
10 loops, best of 3: 20.1 ms per loop
请注意, 类别为dtype的DataFrame快得多。
标签编码
另一种方法是使用称为”标签编码”的技术对分类值进行编码, 该技术允许你将列中的每个值转换为数字。数字标签始终在0到n_categories-1之间。
你可以通过DataFrame列上的属性.cat.codes进行标签编码。
cat_df_flights_lc['carrier'] = cat_df_flights_lc['carrier'].cat.codes
cat_df_flights_lc.head() #alphabetically labeled from 0 to 10
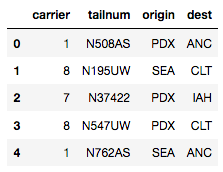
有时, 你可能只想将要素中的一堆类别编码为某个数值, 而将所有其他类别编码为某个其他数值。
你可以通过使用numpy的where()函数来实现此目的, 如下所示。你将把所有美国航空公司的航班编码为值1, 将其他航空公司的航班编码为值0。这将在DataFrame中使用编码创建一个新列。以后, 如果要删除原始列, 可以通过使用pandas中的drop()函数来删除。
cat_df_flights_specific = cat_df_flights.copy()
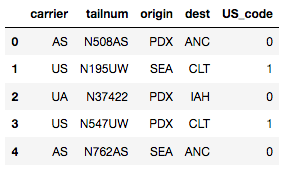
cat_df_flights_specific['US_code'] = np.where(cat_df_flights_specific['carrier'].str.contains('US'), 1, 0)
cat_df_flights_specific.head()
你可以使用scikit-learn的LabelEncoder实现相同的标签编码:
cat_df_flights_sklearn = cat_df_flights.copy()
from sklearn.preprocessing import LabelEncoder
lb_make = LabelEncoder()
cat_df_flights_sklearn['carrier_code'] = lb_make.fit_transform(cat_df_flights['carrier'])
cat_df_flights_sklearn.head() #Results in appending a new column to df
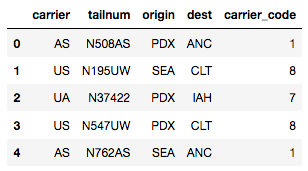
标签编码非常直观, 简单, 可以使你的学习算法获得良好的性能, 但缺点是算法可能会误解数值。载体US(编码为8)的权重应该比载体AS(编码为1)的权重高8倍吗?
为了解决这个问题, 有另一种流行的方法可以通过一种称为单热编码的方式对类别进行编码。
一键编码
基本策略是将每个类别值转换为新列, 并为该列分配1或0(真/假)值。这样做的好处是不会对值进行不正确的加权。
有很多库支持一键编码, 但最简单的库是使用pandas的.get_dummies()方法。
该函数以这种方式命名, 因为它会创建虚拟/指示变量(1或0)。这里主要有三个重要的参数, 第一个是要在其上编码的DataFrame, 第二个是columns参数, 它允许你指定要在其上编码的列, 第三个是prefix参数, 该参数可以让你指定前缀编码后将创建的新列。
cat_df_flights_onehot = cat_df_flights.copy()
cat_df_flights_onehot = pd.get_dummies(cat_df_flights_onehot, columns=['carrier'], prefix = ['carrier'])
print(cat_df_flights_onehot.head())

如你所见, column_AS列在第0和第4个观察点获得值1, 因为这些点在原始DataFrame中标有AS类别。同样对于其他列也是如此。
scikit-learn还通过其预处理模块中的LabelBinarizer和OneHotEncoder支持一种热编码(在此处查看详细信息)。只是为了练习, 你将通过LabelBinarizer进行相同的编码:
cat_df_flights_onehot_sklearn = cat_df_flights.copy()
from sklearn.preprocessing import LabelBinarizer
lb = LabelBinarizer()
lb_results = lb.fit_transform(cat_df_flights_onehot_sklearn['carrier'])
lb_results_df = pd.DataFrame(lb_results, columns=lb.classes_)
print(lb_results_df.head())
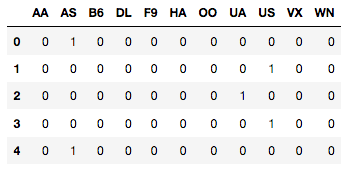
请注意, 此lb_results_df生成了一个新的DataFrame, 该数据帧仅具有特征载体的一种热编码。这需要与原始DataFrame连接起来, 可以通过pandas的.concat()方法来完成。要合并到列上时, axis参数设置为1。
result_df = pd.concat([cat_df_flights_onehot_sklearn, lb_results_df], axis=1)
print(result_df.head())
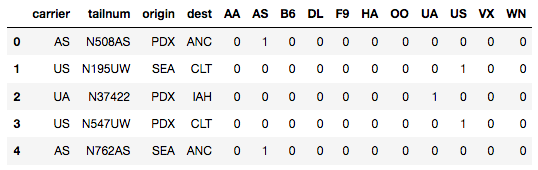
虽然一键编码解决了对要素中的类别赋予不相等权重的问题, 但是在存在多个类别时并不是很有用, 因为这将导致形成许多新列, 这可能导致维数的诅咒。 “维数的诅咒”的概念讨论了在高维空间中某些事情只是无法正常工作。
二进制编码
这种技术不像以前那样直观。在这种技术中, 首先将类别编码为序数, 然后将这些整数转换为二进制代码, 然后将该二进制字符串中的数字拆分为单独的列。与一键编码相比, 这可以以更少的维度编码数据。
你可以通过多种方法进行二进制编码, 但最简单的方法是使用category_encoders库。你可以通过cmd上的pip install category_encoders安装category_encoders, 也可以从站点下载并解压缩.tar.gz文件。
安装后必须首先导入category_encoders库。通过指定要编码的列来调用BinaryEncoder函数, 然后使用DataFrame作为参数对其调用.fit_transform()方法。
cat_df_flights_ce = cat_df_flights.copy()
import category_encoders as ce
encoder = ce.BinaryEncoder(cols=['carrier'])
df_binary = encoder.fit_transform(cat_df_flights_ce)
df_binary.head()
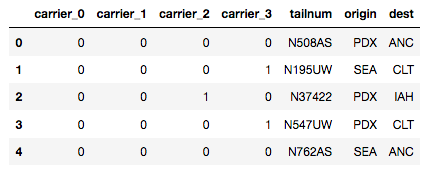
请注意, 将为特征中的每个类别创建带有二进制编码的四个新列来代替载体列。
请注意, category_encoders是用于编码分类列的非常有用的库。它不仅支持一键编码, 二进制编码和标签编码, 还支持其他高级编码方法, 例如Helmert对比度, 多项式对比度, 后向差分等。
5.后向差异编码
该技术属于用于分类特征的对比度编码系统。 K个类别或级别的特征通常以K-1个虚拟变量序列的形式进入回归。在后向差分编码中, 将一个级别的因变量的平均值与先前级别的因变量的平均值进行比较。这种类型的编码对于标称或有序变量可能很有用。
如果你想学习其他对比编码方法, 可以查看此资源。
代码结构与category_encoders库中的任何方法几乎相同, 只是这次你将从中调用BackwardDifferenceEncoder:
encoder = ce.BackwardDifferenceEncoder(cols=['carrier'])
df_bd = encoder.fit_transform(cat_df_flights_ce)
df_bd.head()

有趣的是, 你可以看到结果不是虚拟编码示例中看到的标准1和0, 而是回归的连续值。
杂项功能
有时你可能会遇到分类特征列, 这些列指定观察点的值范围, 例如, 年龄列可能以0-20、20-40等类别的形式描述。
尽管有很多方法可以处理此类功能, 但是最常见的功能是将这些范围分为两个单独的列, 或者用某种度量(例如该范围的平均值)替换它们。
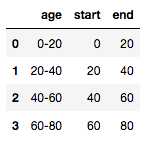
首先, 你将创建一个虚拟DataFrame, 它只有一个特征年龄, 并且使用pandas DataFrame函数指定了范围。然后, 你将分隔符上的列拆分为两部分, 使用带有lambda()函数的split()将其开始和结束。如果你想了解有关lambda函数的更多信息, 请查看本教程。
dummy_df_age = pd.DataFrame({'age': ['0-20', '20-40', '40-60', '60-80']})
dummy_df_age['start'], dummy_df_age['end'] = zip(*dummy_df_age['age'].map(lambda x: x.split('-')))
dummy_df_age.head()
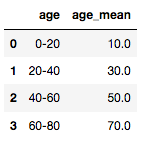
为了用平均值代替范围, 你将编写一个split_mean()函数, 该函数基本上一次获取一个范围, 将其拆分, 然后计算平均值并返回。要将特定功能应用于列的所有实体, 你将使用.apply()方法:
dummy_df_age = pd.DataFrame({'age': ['0-20', '20-40', '40-60', '60-80']})
def split_mean(x):
split_list = x.split('-')
mean = (float(split_list[0])+float(split_list[1]))/2
return mean
dummy_df_age['age_mean'] = dummy_df_age['age'].apply(lambda x: split_mean(x))
dummy_df_age.head()
使用Spark处理大数据中的分类功能
现在, 你将学习如何在Spark中读取数据集, 以及如何在Apache Spark的Python API Pyspark中对分类变量进行编码。但是在此之前, 最好先学习一些有关Spark的基本知识。
Spark是用于集群计算的平台。它使你可以在具有多个节点的群集上分布数据和计算。拆分数据可以更轻松地处理非常大的数据集, 因为每个节点只能处理少量数据。
当每个节点处理自己的总数据子集时, 它还会执行所需的全部计算的一部分, 以便在集群中的节点上并行执行数据处理和计算。
确定Spark是否是解决问题的最佳解决方案需要一些经验, 但是你可以考虑以下问题:
- 我的数据太大而无法在一台计算机上使用吗?
- 我的计算可以轻松并行化吗?
使用Spark的第一步是连接到集群。实际上, 群集将托管在连接到所有其他节点的远程计算机上。将有一台称为主计算机的计算机, 用于管理拆分数据和计算。主服务器连接到群集中其余的计算机, 称为从服务器。主机发送从机数据和计算以运行, 然后它们将结果发送回主机。
当你刚开始使用Spark时, 仅在本地运行集群会更简单。如果你希望在群集上运行Spark并使用Jupyter Notebook, 则可以查看此博客。
如果你想了解有关Spark的更多信息, 请查看这篇涵盖了几乎所有内容的出色教程, 或者查阅srcmini的PySpark入门课程。
Spark编程的第一步是创建一个SparkContext。当你要在集群中执行操作时, 需要SparkContext。 SparkContext告诉Spark如何以及在何处访问集群。你将从导入SparkContext开始。
from pyspark import SparkContext
sc = SparkContext()
请注意, 如果你正在使用Spark的交互式外壳, 则不必导入SparkContext, 因为它已作为sc在你的环境中。
要开始使用Spark DataFrames, 首先必须从SparkContext创建一个SparkSession对象。你可以将SparkContext视为与群集的连接, 将SparkSession视为与该连接的接口。
请注意, 如果你在Spark的交互式外壳中工作, 则在工作空间中将有一个名为spark的SparkSession!
from pyspark.sql import SparkSession as spark
创建SparkSession之后, 就可以开始四处查看集群中的数据。
你的SparkSession具有一个名为catalog的属性, 该属性列出了集群中的所有数据。此属性有几种提取不同信息的方法。
最有用的方法之一是.listTables()方法, 该方法以列表形式返回群集中所有表的名称。
print(spark.catalog.listTables())
[]
你的目录当前为空!
现在, 你将在Spark DataFrame中加载排期数据集。
要读取.csv文件并创建Spark DataFrame, 可以使用SparkSession对象的.read属性。在这里, 除了读取csv文件外, 还必须将headers选项指定为True, 因为数据集中有列名。同样, 将inferSchema参数设置为True, 这基本上是从数据的第一行开始窥视以确定字段的名称和类型。
spark_flights = spark.read.format("csv").option('header', True).load('Downloads/datasets/nyc_flights/flights.csv', inferSchema=True)
要检查DataFrame的内容, 可以在DataFrame上运行.show()方法。
spark_flights.show(3)
+----+-----+---+--------+---------+--------+---------+-------+-------+------+------+----+--------+--------+----+------+
|year|month|day|dep_time|dep_delay|arr_time|arr_delay|carrier|tailnum|flight|origin|dest|air_time|distance|hour|minute|
+----+-----+---+--------+---------+--------+---------+-------+-------+------+------+----+--------+--------+----+------+
|2014| 1| 1| 1| 96| 235| 70| AS| N508AS| 145| PDX| ANC| 194| 1542| 0| 1|
|2014| 1| 1| 4| -6| 738| -23| US| N195UW| 1830| SEA| CLT| 252| 2279| 0| 4|
|2014| 1| 1| 8| 13| 548| -4| UA| N37422| 1609| PDX| IAH| 201| 1825| 0| 8|
+----+-----+---+--------+---------+--------+---------+-------+-------+------+------+----+--------+--------+----+------+
only showing top 3 rows
如果要将熊猫DataFrame转换为Spark DataFrame, 请在SparkSession对象上使用.createDataFrame()方法, 并以DataFrame的名称作为参数。
要查看DataFrame的架构, 可以按以下方式调用.printSchema():
spark_flights.printSchema()
root
|-- year: integer (nullable = true)
|-- month: integer (nullable = true)
|-- day: integer (nullable = true)
|-- dep_time: string (nullable = true)
|-- dep_delay: string (nullable = true)
|-- arr_time: string (nullable = true)
|-- arr_delay: string (nullable = true)
|-- carrier: string (nullable = true)
|-- tailnum: string (nullable = true)
|-- flight: integer (nullable = true)
|-- origin: string (nullable = true)
|-- dest: string (nullable = true)
|-- air_time: string (nullable = true)
|-- distance: integer (nullable = true)
|-- hour: string (nullable = true)
|-- minute: string (nullable = true)
请注意, Spark并不总是会正确猜出列的数据类型, 并且由于某些原因, 你会发现某些似乎具有数值的列(arr_delay, air_time等)被读取为字符串, 而不是整数或浮点数。缺失值的存在。
此时, 如果像以前一样使用.catalog属性和.listTables()方法检查群集中的数据, 你会发现它仍然为空。这是因为你的DataFrame当前存储在本地, 而不是SparkSession目录中。
要以这种方式访问数据, 必须将其另存为临时表。你可以使用.createOrReplaceTempView()方法来实现。此方法将DataFrame注册为目录中的表, 但是由于此表是临时表, 因此只能从用于创建Spark DataFrame的特定SparkSession进行访问。
spark_flights.createOrReplaceTempView("flights_temp")
再次打印目录中的表:
print(spark.catalog.listTables())
[Table(name=u'flights_temp', database=None, description=None, tableType=u'TEMPORARY', isTemporary=True)]
现在, 你已将flight_temp表注册为目录中的临时表。
现在你已经掌握了一些PySpark代码, 现在该看看如何对分类特征进行编码了。为了使内容整洁, 你可以使用.select()方法创建一个仅由载体列组成的新DataFrame。
carrier_df = spark_flights.select("carrier")
carrier_df.show(5)
+-------+
|carrier|
+-------+
| AS|
| US|
| UA|
| US|
| AS|
+-------+
only showing top 5 rows
在Spark中编码分类特征的两种最常见方法是使用StringIndexer和OneHotEncoder。
- StringIndexer将标签的字符串列编码为标签索引的列。索引按标签频率排序在[0, numLabels]中, 因此最常使用的标签的索引为0。这类似于熊猫中的标签编码。
你将从pyspark.ml.feature模块中导入StringIndexer类开始。 StringIndexer内部的主要参数是inputCol和outputCol, 这是不言自明的。创建StringIndex对象后, 以DataFrame作为参数传递调用.fit()和.transform()方法, 如下所示:
from pyspark.ml.feature import StringIndexer
carr_indexer = StringIndexer(inputCol="carrier", outputCol="carrier_index")
carr_indexed = carr_indexer.fit(carrier_df).transform(carrier_df)
carr_indexed.show(7)
+-------+-------------+
|carrier|carrier_index|
+-------+-------------+
| AS| 0.0|
| US| 6.0|
| UA| 4.0|
| US| 6.0|
| AS| 0.0|
| DL| 3.0|
| UA| 4.0|
+-------+-------------+
only showing top 7 rows
由于AS是运营商列中最常见的类别, 因此索引为0.0。
- OneHotEncoder:如前所述, 一键编码将分类特征(表示为标签索引)映射到二进制向量, 该向量最多包含一个单一的单值, 表示存在所有特征集中的特定特征值价值观。
例如, 对于5个类别, 输入值2.0将映射到输出向量[0.0、0.0、1.0、0.0]。默认情况下不包括最后一个类别(可通过OneHotEncoder .dropLast进行配置, 因为它使矢量项的总和为1, 因此线性相关。这意味着输入值4.0会映射为[0.0, 0.0, 0.0, 0.0] 。
请注意, 这与scikit-learn的OneHotEncoder不同, 后者保留所有类别。输出向量是稀疏的。
对于这种情况下的字符串类型, 通常首先使用StringIndexer(此处为carrier_index)对要素进行编码。然后将该列传递给OneHotEncoder类。
代码如下所示。
carrier_df_onehot = spark_flights.select("carrier")
from pyspark.ml.feature import OneHotEncoder, StringIndexer
stringIndexer = StringIndexer(inputCol="carrier", outputCol="carrier_index")
model = stringIndexer.fit(carrier_df_onehot)
indexed = model.transform(carrier_df_onehot)
encoder = OneHotEncoder(dropLast=False, inputCol="carrier_index", outputCol="carrier_vec")
encoded = encoder.transform(indexed)
encoded.show(7)
+-------+-------------+--------------+
|carrier|carrier_index| carrier_vec|
+-------+-------------+--------------+
| AS| 0.0|(11, [0], [1.0])|
| US| 6.0|(11, [6], [1.0])|
| UA| 4.0|(11, [4], [1.0])|
| US| 6.0|(11, [6], [1.0])|
| AS| 0.0|(11, [0], [1.0])|
| DL| 3.0|(11, [3], [1.0])|
| UA| 4.0|(11, [4], [1.0])|
+-------+-------------+--------------+
only showing top 7 rows
请注意, OneHotEncoder为每个类别创建了一个向量, 然后你的机器学习管道可以对其进行进一步处理。
Spark中还有其他一些可用的方法, 例如VectorIndexer, 但是你已经掌握了最受欢迎的方法。如果你想研究更多, 请查看Spark的精彩文档。
结论
呼!!你已经走了很长一段路!你已经研究了有关在机器学习领域中处理分类特征的大部分零碎内容。你从熊猫中的基本EDA开始, 然后练习了可用的不同编码方法。你还了解了一些Spark的体系结构, 并开始在PySpark中编码分类数据。数量很多, 但总有很多东西要学习。你还必须确保已正确清理数据。要了解如何执行此操作, 请查看我们的Python清洗数据课程。研究愉快!
评论前必须登录!
注册