 srcmini
srcmini本文概述
想象一下, 你可以了解Internet上人们的心情。也许你对整体不感兴趣, 但前提是今天人们在你喜欢的社交媒体平台上感到高兴。学习完本教程后, 你将可以执行此操作。在此过程中, 你将掌握(深度)神经网络的最新进展以及如何将其应用于文本。
通过机器学习从文本中读取情绪被称为情感分析, 它是文本分类中最重要的用例之一。这属于自然语言处理(NLP)的非常活跃的研究领域。文本分类的其他常见用例包括检测垃圾邮件, 自动标记客户查询以及将文本分类为已定义的主题。那你怎么做呢?
免费奖金:关于Python精通的5个想法, 这是针对Python开发人员的免费课程, 向你展示了将Python技能提升到新水平所需的路线图和思路。
移除广告
选择数据集
在开始之前, 让我们看一下我们拥有的数据。继续并从UCI机器学习存储库中的“情感标记句子数据集”下载数据集。
顺便说一句, 当你想尝试一些算法时, 该存储库是机器学习数据集的绝佳来源。该数据集包括来自IMDb, Amazon和Yelp的带有标签的评论。每个评论的负面情绪评分为0, 正面情绪评分为1。
将文件夹提取到数据文件夹中, 然后继续使用Pandas加载数据:
import pandas as pd
filepath_dict = {'yelp': 'data/sentiment_analysis/yelp_labelled.txt', 'amazon': 'data/sentiment_analysis/amazon_cells_labelled.txt', 'imdb': 'data/sentiment_analysis/imdb_labelled.txt'}
df_list = []
for source, filepath in filepath_dict.items():
df = pd.read_csv(filepath, names=['sentence', 'label'], sep='\t')
df['source'] = source # Add another column filled with the source name
df_list.append(df)
df = pd.concat(df_list)
print(df.iloc[0])
结果如下:
sentence Wow... Loved this place.
label 1
source yelp
Name: 0, dtype: object
这看起来不错。使用此数据集, 你可以训练模型以预测句子的情感。花点时间思考一下如何预测数据。
一种执行此操作的方法是计算每个句子中每个单词的出现频率, 然后将此计数重新绑定到数据集中的整个单词集。你将首先获取数据并根据所有句子中的所有单词创建词汇表。文本集合在NLP中也称为语料库。
在这种情况下, 词汇表是在我们的文本中出现的单词的列表, 其中每个单词都有自己的索引。这使你可以为句子创建向量。然后, 你将采用想要向量化的句子, 并计算词汇表中的每次出现次数。所得的矢量将具有词汇表的长度以及词汇表中每个单词的计数。
所得向量也称为特征向量。在特征向量中, 每个维度可以是数字或分类特征, 例如建筑物的高度, 股票的价格, 或者在我们的情况下是词汇表中单词的计数。这些特征向量是数据科学和机器学习中的关键部分, 因为要训练的模型取决于它们。
让我们快速说明一下。假设你有以下两个句子:
>>>
>>> sentences = ['John likes ice cream', 'John hates chocolate.']
接下来, 你可以使用scikit-learn库提供的CountVectorizer对句子进行矢量化处理。它接受每个句子的单词, 并创建句子中所有唯一单词的词汇表。然后可以使用此词汇表来创建单词计数的特征向量:
>>>
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> vectorizer = CountVectorizer(min_df=0, lowercase=False)
>>> vectorizer.fit(sentences)
>>> vectorizer.vocabulary_
{'John': 0, 'chocolate': 1, 'cream': 2, 'hates': 3, 'ice': 4, 'likes': 5}
该词汇表还充当每个单词的索引。现在, 你可以采用每个句子并根据以前的词汇表获取单词的单词出现。词汇表由我们句子中的所有五个单词组成, 每个单词代表词汇表中的一个单词。当你使用前两个句子并使用CountVectorizer对其进行转换时, 你将得到一个表示该句子每个单词的计数的向量:
>>>
>>> vectorizer.transform(sentences).toarray()
array([[1, 0, 1, 0, 1, 1], [1, 1, 0, 1, 0, 0]])
现在, 你可以基于先前的词汇表查看每个句子的最终特征向量。例如, 如果你看一下第一项, 则可以看到两个向量在其中都有1。这意味着两个句子都出现一次John, 这在词汇表中排在首位。
这被认为是词袋(BOW)模型, 这是NLP中从文本创建矢量的一种常用方法。每个文档都表示为矢量。你现在可以将这些向量用作机器学习模型的特征向量。这将引导我们进入下一部分, 定义基线模型。
定义基准模型
使用机器学习时, 重要的一步是定义基准模型。这通常涉及一个简单的模型, 然后将该模型与你要测试的更高级的模型进行比较。在这种情况下, 你将使用基准模型将其与涉及(深度)神经网络, 本教程内容的所有高级方法进行比较。
首先, 你将数据分成训练和测试集, 这将使你可以评估准确性, 并查看模型是否能很好地泛化。这意味着该模型是否能够对以前从未见过的数据执行良好的操作。这是查看模型是否过度拟合的一种方法。
过度拟合是指模型在训练数据上训练得太好。你要避免过度拟合, 因为这将意味着该模型主要只是存储了训练数据。这将导致训练数据的准确性较高, 而测试数据的准确性较低。
我们首先获取从连接数据集中提取的Yelp数据集。在这里, 我们接受句子和标签。 .values返回一个NumPy数组, 而不是Pandas Series对象, 在这种情况下, 它更易于使用:
>>>
>>> from sklearn.model_selection import train_test_split
>>> df_yelp = df[df['source'] == 'yelp']
>>> sentences = df_yelp['sentence'].values
>>> y = df_yelp['label'].values
>>> sentences_train, sentences_test, y_train, y_test = train_test_split(
... sentences, y, test_size=0.25, random_state=1000)
在这里, 我们将再次使用先前的BOW模型对句子进行矢量化处理。你可以再次使用CountVectorizer来完成此任务。由于培训期间可能没有可用的测试数据, 因此可以仅使用培训数据来创建词汇表。使用此词汇表, 你可以为训练和测试集的每个句子创建特征向量:
>>>
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> vectorizer = CountVectorizer()
>>> vectorizer.fit(sentences_train)
>>> X_train = vectorizer.transform(sentences_train)
>>> X_test = vectorizer.transform(sentences_test)
>>> X_train
<750x1714 sparse matrix of type '<class 'numpy.int64'>'
with 7368 stored elements in Compressed Sparse Row format>
你可以看到生成的特征向量有750个样本, 这是训练测试拆分后我们拥有的训练样本的数量。每个样本都有1714个维度, 即词汇量。另外, 你可以看到我们得到了一个稀疏矩阵。这是一种针对仅包含几个非零元素的矩阵进行优化的数据类型, 该数据类型仅跟踪非零元素, 从而减少了内存负载。
CountVectorizer执行标记化, 将句子分为一组标记, 如你先前在词汇表中所见。此外, 它还删除了标点符号和特殊字符, 并且可以对每个单词进行其他预处理。如果需要, 可以将NLTK库中的自定义标记器与CountVectorizer一起使用, 或者使用可以探索以提高模型性能的任意数量的自定义项。
注意:CountVectorizer()有很多其他参数, 我们不打算在此处使用, 例如添加ngram, 因为最初的目标是建立一个简单的基线模型。令牌模式本身默认为token_pattern ='(?u)\ b \ w \ w + \ b’, 这是一种正则表达式模式, 表示“一个单词是2个或更多被单词边界包围的Unicode单词字符。”。
我们将要使用的分类模型是逻辑回归, 它是一个简单而强大的线性模型, 从数学上讲, 实际上是基于输入特征向量的0到1之间的回归形式。通过指定截止值(默认为0.5), 将回归模型用于分类。你可以再次使用提供LogisticRegression分类器的scikit-learn库:
>>>
>>> from sklearn.linear_model import LogisticRegression
>>> classifier = LogisticRegression()
>>> classifier.fit(X_train, y_train)
>>> score = classifier.score(X_test, y_test)
>>> print("Accuracy:", score)
Accuracy: 0.796
你可以看到逻辑回归达到了令人印象深刻的79.6%, 但让我们看一下该模型如何在我们拥有的其他数据集上执行。在此脚本中, 我们为拥有的每个数据集执行并评估整个过程:
for source in df['source'].unique():
df_source = df[df['source'] == source]
sentences = df_source['sentence'].values
y = df_source['label'].values
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
vectorizer = CountVectorizer()
vectorizer.fit(sentences_train)
X_train = vectorizer.transform(sentences_train)
X_test = vectorizer.transform(sentences_test)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print('Accuracy for {} data: {:.4f}'.format(source, score))
结果如下:
Accuracy for yelp data: 0.7960
Accuracy for amazon data: 0.7960
Accuracy for imdb data: 0.7487
大!你可以看到, 这个相当简单的模型实现了相当好的准确性。看看我们是否能够胜过该模型将是很有趣的。在下一部分中, 我们将熟悉(深度)神经网络以及如何将其应用于文本分类。
移除广告
(深度)神经网络入门
你可能已经经历了一些与人工智能和深度学习相关的兴奋和恐惧。你可能偶然发现了一些令人困惑的文章, 或者是有关即将到来的奇点的TED演讲, 或者你看到了后空翻机器人, 并且想知道在树林中的生活毕竟是否还算合理。
轻松一点, 人工智能研究人员都同意, 当人工智能将超过人类水平的表现时, 他们不会彼此同意。根据本文, 我们应该还有一些时间。
因此, 你可能已经好奇神经网络如何工作。如果你已经熟悉神经网络, 请随时跳到涉及Keras的部分。此外, 还有Ian Goodfellow撰写的精彩的《深度学习》一书, 如果你想更深入地研究数学, 我强烈建议你这样做。你可以免费在线阅读整本书。在本节中, 你将概述神经网络及其内部工作原理, 并且稍后将了解如何将神经网络与出色的Keras库一起使用。
在本文中, 你不必担心奇异性, 但是(深度)神经网络在AI的最新发展中起着至关重要的作用。这一切始于Geoffrey Hinton和他的团队在2012年发表的著名论文, 其表现优于著名的ImageNet Challenge中所有以前的模型。
可以将挑战视为计算机视觉世界杯, 其中涉及根据给定的标签对大量图像进行分类。杰弗里·欣顿(Geoffrey Hinton)和他的团队通过使用卷积神经网络(CNN)击败了先前的模型, 我们还将在本教程中进行介绍。
从那时起, 神经网络已进入涉及分类, 回归甚至生成模型的多个领域。最普遍的领域包括计算机视觉, 语音识别和自然语言处理(NLP)。
神经网络, 有时也称为人工神经网络(ANN)或前馈神经网络, 是受人脑神经网络模糊启发的计算网络。它们由神经元(也称为节点)组成, 它们的连接方式如下图所示。
首先要有一层输入神经元, 然后在其中输入特征向量, 然后将值前馈到隐藏层。在每个连接处, 你都在将值前馈, 同时将值乘以权重并向该值添加偏差。这发生在每个连接上, 最后到达具有一个或多个输出节点的输出层。
如果要进行二进制分类, 可以使用一个节点, 但是如果有多个类别, 则应为每个类别使用多个节点:
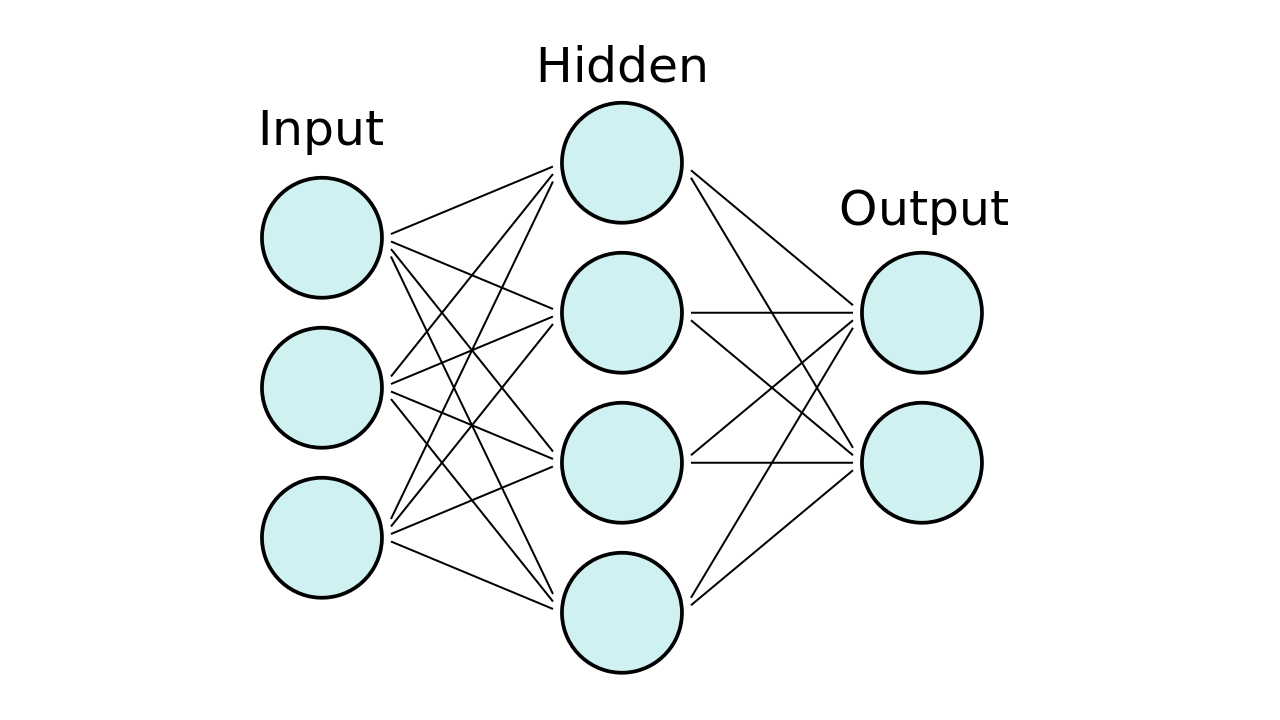
神经网络模型
你可以根据需要拥有任意数量的隐藏层。实际上, 具有多个隐藏层的神经网络被视为深度神经网络。别担心:我不会在这里深入探讨有关神经网络的数学知识。但是, 如果你想直观地了解所涉及的数学, 可以查看Grant Sanderson的YouTube播放列表。简短的公式是从一层到另一层的公式:

神经网络公式
让我们慢慢解压缩这里发生的事情。你看, 我们在这里仅处理两层。具有节点a的层用作具有节点o的层的输入。为了计算每个输出节点的值, 我们必须将每个输入节点乘以权重w, 然后加上一个偏差b。
然后必须将所有这些求和并传递给函数f。该功能被认为是激活功能, 根据层或问题, 可以使用各种不同的功能。通常在隐藏层中使用整流线性单元(ReLU), 在二进制分类问题中将Sigmoid函数用于输出层, 或者在多层分类问题中将softmax函数用于输出层。
你可能已经想知道权重是如何计算的, 这显然是神经网络最重要的部分, 也是最困难的部分。该算法首先使用随机值初始化权重, 然后使用称为反向传播的方法对其进行训练。
这是通过使用诸如梯度下降之类的优化方法(也称为优化器)来完成的, 以减少计算出的输出与所需输出(也称为目标输出)之间的误差。误差由损失函数确定, 我们希望使用优化器将其损失降至最低。整个过程过于繁琐, 无法在此处进行介绍, 但是我将再次参考之前提到的Grant Sanderson播放列表和Ian Goodfellow撰写的《深度学习》。
你必须知道可以使用多种优化方法, 但是当前使用的最常见的优化器称为Adam, 它在各种问题上都有很好的性能。
你也可以使用不同的损失函数, 但是在本教程中, 你将只需要交叉熵损失函数或更具体地说是用于二进制分类问题的二进制交叉熵。确保尝试各种可用的方法和工具。一些研究人员甚至在最近的一篇文章中声称, 选择性能最佳的方法与炼金术有关。原因是许多方法没有得到很好的解释, 并且包含大量的调整和测试。
辛苦介绍
Keras是FrançoisChollet开发的深度学习和神经网络API, 能够在Tensorflow(Google), Theano或CNTK(Microsoft)之上运行。引用FrançoisChollet的精彩著作《 Python深度学习》:
Keras是一个模型级库, 为开发深度学习模型提供了高级构建块。它不处理诸如张量操纵和微分之类的底层操作。取而代之的是, 它依赖于专门的, 经过优化的张量库来充当Keras的后端引擎(来源)
这是开始尝试神经网络的好方法, 而不必自己实现每一层和每一层。例如, Tensorflow是一个很棒的机器学习库, 但是你必须实现很多样板代码才能运行模型。
移除广告
硬安装
在安装Keras之前, 你需要Tensorflow, Theano或CNTK。在本教程中, 我们将使用Tensorflow, 因此请在此处查看其安装指南, 但可以随时使用最适合你的任何框架。可以使用PyPI通过以下命令安装Keras:
$ pip install keras
你可以通过打开Keras配置文件来选择想要的后端, 该文件可在以下位置找到:
$HOME/.keras/keras.json
如果你是Windows用户, 则必须将$ HOME替换为%USERPROFILE%。配置文件应如下所示:
{
"image_data_format": "channels_last", "epsilon": 1e-07, "floatx": "float32", "backend": "tensorflow"
}
假设你已在计算机上安装了后端, 则可以在此处将后端字段更改为“ theano”, “ tensorflow”或“ cntk”。有关更多详细信息, 请查看Keras后端文档。
你可能会注意到, 我们在配置文件中使用float32数据。原因是神经网络经常在GPU中使用, 而计算瓶颈是内存。通过使用32位, 我们可以减少内存负载, 并且在此过程中不会丢失太多信息。
你的第一个Keras模型
现在, 你终于可以尝试使用Keras了。 Keras支持两种主要类型的模型。你将拥有在本教程中使用的顺序模型API和功能性API, 该功能API可以完成所有顺序模型的所有工作, 但也可以用于具有复杂网络体系结构的高级模型。
顺序模型是线性的图层堆栈, 你可以在Keras中使用各种各样的可用图层。最常见的层是密集层, 它是你常规的紧密连接的神经网络层, 具有你已经熟悉的所有权重和偏差。
让我们看看是否可以对我们以前的逻辑回归模型进行一些改进。你可以使用在我们先前的示例中构建的X_train和X_test数组。
在建立模型之前, 我们需要知道特征向量的输入维。这仅在第一层中发生, 因为随后的层可以进行自动形状推断。为了构建顺序模型, 你可以按如下顺序逐个添加图层:
>>>
>>> from keras.models import Sequential
>>> from keras import layers
>>> input_dim = X_train.shape[1] # Number of features
>>> model = Sequential()
>>> model.add(layers.Dense(10, input_dim=input_dim, activation='relu'))
>>> model.add(layers.Dense(1, activation='sigmoid'))
Using TensorFlow backend.
在开始训练模型之前, 你需要配置学习过程。这是通过.compile()方法完成的。此方法指定优化器和损失函数。
此外, 你可以添加一个度量标准列表, 以后可以用于评估, 但是它们不会影响培训。在这种情况下, 我们希望使用你在前面提到的入门中看到的二进制交叉熵和Adam优化器。 Keras还包括一个方便的.summary()函数, 以概述模型和可用于训练的参数数量:
>>>
>>> model.compile(loss='binary_crossentropy', ... optimizer='adam', ... metrics=['accuracy'])
>>> model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 10) 17150
_________________________________________________________________
dense_2 (Dense) (None, 1) 11
=================================================================
Total params: 17, 161
Trainable params: 17, 161
Non-trainable params: 0
_________________________________________________________________
你可能会注意到, 第一层有8575个参数, 下一层有6个。这些是从哪里来的?
看到, 每个特征向量有1714个维, 然后有5个节点。我们需要为每个特征维和每个节点分配权重, 这些权重需要1714 * 5 = 8570个参数, 然后每个节点还要再加上5倍的附加偏差, 即获得8575个参数。在最后一个节点中, 我们还有另外5个权重和一个偏差, 这使我们获得6个参数。
整齐!你快到了。现在该开始使用.fit()函数进行训练了。
由于神经网络的训练是一个反复的过程, 因此训练不会在完成后立即停止。你必须指定要训练模型的迭代次数。这些完成的迭代通常称为时期。我们希望将其运行100个纪元, 以便能够看到每个纪元后训练损失和准确性如何变化。
你必须选择的另一个参数是批量大小。批大小决定了我们在一个纪元中要使用多少个样本, 这意味着一次向前/向后遍历中要使用多少个样本。由于它需要更少的时间来运行, 因此提高了计算速度, 但同时也需要更多的内存, 并且随着批处理量的增加, 模型可能会退化。由于我们的培训集很小, 因此可以将其设置为较小的批量:
>>>
>>> history = model.fit(X_train, y_train, ... epochs=100, ... verbose=False, ... validation_data=(X_test, y_test)
... batch_size=10)
现在, 你可以使用.evaluate()方法来测量模型的准确性。你可以对训练数据和测试数据都执行此操作。我们期望训练数据比测试数据具有更高的准确性。发球时间越长, 你训练神经网络的可能性就越大, 它开始过度拟合。
请注意, 如果你重新运行.fit()方法, 则将从先前训练中计算出的权重开始。在再次开始训练模型之前, 请确保再次编译模型。现在, 我们来评估精度模型:
>>>
>>> loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
>>> print("Training Accuracy: {:.4f}".format(accuracy))
>>> loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
>>> print("Testing Accuracy: {:.4f}".format(accuracy))
Training Accuracy: 1.0000
Testing Accuracy: 0.7960
你已经可以看到模型拟合过度, 因为它对于训练集达到了100%的准确性。但这是预料之中的, 因为此模型的纪元数相当大。但是, 测试集的准确性已经超过了我们先前使用BOW模型进行的Logistic回归, 这在我们的进步方面又向前迈了一大步。
为了使你的生活更轻松, 你可以使用此小帮手功能根据“历史记录”回调来可视化训练和测试数据的损失和准确性。此回调自动应用于每个Keras模型, 记录了损耗和可以在.fit()方法中添加的其他指标。在这种情况下, 我们只对准确性感兴趣。此辅助函数使用matplotlib绘图库:
import matplotlib.pyplot as plt
plt.style.use('ggplot')
def plot_history(history):
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
x = range(1, len(acc) + 1)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(x, acc, 'b', label='Training acc')
plt.plot(x, val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(x, loss, 'b', label='Training loss')
plt.plot(x, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
要使用此功能, 只需在历史字典中调用具有所收集的准确性和损失的plot_history():
>>>
>>> plot_history(history)

基线模型的准确性和损失
你可以看到, 自训练集达到100%的准确性以来, 我们对模型的训练时间过长。查看模型何时开始过度拟合的一个好方法是, 验证数据的损失何时开始再次上升。这往往是停止模型的好方法。你可以在本次培训中看到20-40个纪元。
注意:训练神经网络时, 应使用单独的测试和验证集。通常, 你将采用具有最高验证精度的模型, 然后使用测试集对模型进行测试。
这样可以确保你不会过度拟合模型。使用验证集选择最佳模型是数据泄漏(或“作弊”)的一种形式, 可以从数百种数据中挑选出产生最佳测试分数的结果。当模型中使用训练数据集之外的信息时, 就会发生数据泄漏。
在这种情况下, 我们的测试和验证集相同, 因为我们的样本量较小。如前所述, 当你有大量样本时, (深度)神经网络的效果最佳。在下一部分中, 你将看到另一种将单词表示为矢量的方式。这是一种非常令人兴奋且功能强大的方式来处理单词, 你将看到如何将单词表示为密集向量。
移除广告
什么是词嵌入?
文本被认为是序列数据的一种形式, 类似于天气数据或财务数据中的时间序列数据。在以前的BOW模型中, 你已经看到了如何将整个单词序列表示为单个特征向量。现在, 你将看到如何将每个单词表示为向量。有多种矢量化文本的方法, 例如:
- 每个单词表示的单词作为矢量
- 每个字符表示为矢量的字符
- N-gram表示为向量的单词/字符(N-gram是文本中多个后续单词/字符的重叠组)
在本教程中, 你将看到如何将单词表示为向量, 这是在神经网络中使用文本的常用方法。将单词表示为矢量的两种可能方法是单热编码和单词嵌入。
一站式编码
将单词表示为矢量的第一种方法是创建所谓的“单热”编码, 只需将词汇长度的矢量与语料库中每个单词的条目一起输入即可。
这样, 对于每个单词, 给定它在词汇表中有一个点, 那么每个位置都有一个零的矢量, 但该单词的对应点设置为1。就像你想象的那样, 对于每个单词, 这可能会成为一个很大的向量, 并且不会像单词之间的关系那样提供任何其他信息。
假设你有一个城市列表, 如以下示例所示:
>>>
>>> cities = ['London', 'Berlin', 'Berlin', 'New York', 'London']
>>> cities
['London', 'Berlin', 'Berlin', 'New York', 'London']
你可以使用scikit-learn和LabelEncoder将城市列表编码为如下所示的分类整数值:
>>>
>>> from sklearn.preprocessing import LabelEncoder
>>> encoder = LabelEncoder()
>>> city_labels = encoder.fit_transform(cities)
>>> city_labels
array([1, 0, 0, 2, 1])
使用此表示形式, 你可以使用scikit-learn提供的OneHotEncoder将我们之前获得的分类值编码为一个单编码的数字数组。 OneHotEncoder希望每个分类值都位于单独的行中, 因此你需要调整数组的形状, 然后可以应用编码器:
>>>
>>> from sklearn.preprocessing import OneHotEncoder
>>> encoder = OneHotEncoder(sparse=False)
>>> city_labels = city_labels.reshape((5, 1))
>>> encoder.fit_transform(city_labels)
array([[0., 1., 0.], [1., 0., 0.], [1., 0., 0.], [0., 0., 1.], [0., 1., 0.]])
你会看到分类整数值表示数组的位置, 该数组的位置为1, 其余为0。当你具有无法表示为数字值但仍希望能够使用它的分类功能时, 通常使用此值在机器学习中。这种编码的一个用例当然是文本中的单词, 但是最显着地用于类别。这样的类别可以是例如城市, 部门或其他类别。
词嵌入
此方法将单词表示为密集单词向量(也称为单词嵌入), 这些单词向量与硬编码的一键编码不同。这意味着单词嵌入将更多信息收集到更少的维度。
请注意, 嵌入词一词并不像人类那样理解文本, 而是映射了语料库中使用的语言的统计结构。他们的目的是将语义含义映射到几何空间中。然后将该几何空间称为嵌入空间。
这将在语义上将相似的单词映射到嵌入空间上, 例如数字或颜色。如果嵌入能够很好地捕捉单词之间的关系, 那么矢量算术之类的事情就应该成为可能。该研究领域的一个著名例子是绘制国王-男人+女人=女王的能力。
你如何获得这样的词嵌入?你有两个选择。一种方法是在训练神经网络时训练单词嵌入。另一种方法是使用可以直接在模型中使用的预训练词嵌入。在那里, 你可以选择在训练过程中使这些词嵌入保持不变, 也可以对其进行训练。
现在, 你需要将数据标记化为嵌入单词可以使用的格式。 Keras为文本预处理和序列预处理提供了两种便捷的方法, 你可以使用它们来准备文本。
你可以从使用Tokenizer实用程序类开始, 该类可以将文本语料库向量化为整数列表。每个整数都映射到字典中的一个值, 该值对整个主体进行编码, 字典中的键本身就是词汇术语。你可以添加参数num_words, 它负责设置词汇表的大小。然后将保留最常见的num_words个单词。我已经从上一个示例准备了测试和培训数据:
>>>
>>> from keras.preprocessing.text import Tokenizer
>>> tokenizer = Tokenizer(num_words=5000)
>>> tokenizer.fit_on_texts(sentences_train)
>>> X_train = tokenizer.texts_to_sequences(sentences_train)
>>> X_test = tokenizer.texts_to_sequences(sentences_test)
>>> vocab_size = len(tokenizer.word_index) + 1 # Adding 1 because of reserved 0 index
>>> print(sentences_train[2])
>>> print(X_train[2])
Of all the dishes, the salmon was the best, but all were great.
[11, 43, 1, 171, 1, 283, 3, 1, 47, 26, 43, 24, 22]
索引是在文本中最常见的单词之后排序的, 你可以通过单词看到带有索引1的单词。重要的是要注意, 索引0是保留的, 并且未分配给任何单词。这个零索引用于填充, 我将在稍后介绍。
未知单词(不在词汇表中的单词)在Keras中用word_count +1表示, 因为它们也可以保存一些信息。通过查看Tokenizer对象的word_index字典, 可以看到每个单词的索引:
>>>
>>> for word in ['the', 'all', 'happy', 'sad']:
... print('{}: {}'.format(word, tokenizer.word_index[word]))
the: 1
all: 43
happy: 320
sad: 450
注意:请密切注意此技术与scikit-learn的CountVectorizer产生的X_train之间的区别。
使用CountVectorizer, 我们可以堆叠单词计数的向量, 并且每个向量的长度都相同(总语料库词汇量)。使用Tokenizer, 结果向量等于每个文本的长度, 数字不表示计数, 而是与字典tokenizer.word_index中的单词值相对应。
我们遇到的一个问题是, 在大多数情况下, 每个文本序列的单词长度都不同。为了解决这个问题, 你可以使用pad_sequence(), 它简单地用零填充单词序列。默认情况下, 它前面加零, 但我们要附加它们。通常, 是否在零前面或后面都没关系。
另外, 你可能希望添加maxlen参数以指定序列应多长时间。这将剪切超出该数目的序列。在以下代码中, 你可以看到如何用Keras填充序列:
>>>
>>> from keras.preprocessing.sequence import pad_sequences
>>> maxlen = 100
>>> X_train = pad_sequences(X_train, padding='post', maxlen=maxlen)
>>> X_test = pad_sequences(X_test, padding='post', maxlen=maxlen)
>>> print(X_train[0, :])
[ 1 10 3 282 739 25 8 208 30 64 459 230 13 1 124 5 231 8
58 5 67 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
从前面的示例中学到的, 第一个值表示词汇表中的索引。你还会看到生成的特征向量主要包含零, 因为你的句子很短。在下一部分中, 你将看到如何在Keras中使用单词嵌入。
移除广告
硬包埋层
请注意, 此时, 我们的数据仍是硬编码的。我们没有告诉Keras通过连续的任务来学习新的嵌入空间。现在, 你可以使用Keras的“嵌入层”, 该层将使用先前计算的整数并将其映射到嵌入的密集向量。你将需要以下参数:
- input_dim:词汇量
- output_dim:密集向量的大小
- input_length:序列的长度
有了嵌入层, 我们现在有了两个选择。一种方法是获取嵌入层的输出并将其插入密集层。为此, 你必须在两者之间添加一个Flatten层, 以为Dense层准备顺序输入:
from keras.models import Sequential
from keras import layers
embedding_dim = 50
model = Sequential()
model.add(layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=maxlen))
model.add(layers.Flatten())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_8 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
flatten_3 (Flatten) (None, 5000) 0
_________________________________________________________________
dense_13 (Dense) (None, 10) 50010
_________________________________________________________________
dense_14 (Dense) (None, 1) 11
=================================================================
Total params: 137, 371
Trainable params: 137, 371
Non-trainable params: 0
_________________________________________________________________
现在你可以看到我们有87350个新参数要训练。该数字来自vocab_size乘以embedding_dim。使用随机权重初始化嵌入层的这些权重, 然后在训练过程中通过反向传播进行调整。该模型将按句子顺序出现的单词作为输入向量。你可以使用以下方法进行训练:
history = model.fit(X_train, y_train, epochs=20, verbose=False, validation_data=(X_test, y_test), batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
结果如下:
Training Accuracy: 0.5100
Testing Accuracy: 0.4600

第一个模型的准确性和损失
从性能中可以看出, 这通常不是一种非常可靠的方式来处理顺序数据。在处理顺序数据时, 你希望专注于查看局部和顺序信息而不是绝对位置信息的方法。
嵌入的另一种方法是在嵌入后使用MaxPooling1D / AveragePooling1D或GlobalMaxPooling1D / GlobalAveragePooling1D层。你可以将池化层视为对传入特征向量进行降采样(减小其大小的一种方法)的一种方法。
在最大池化的情况下, 你要为每个要素维取池中所有要素的最大值。如果使用平均池, 则取平均值, 但最大池似乎更常用, 因为它会突出显示较大的值。
全局最大/平均池采用所有功能的最大/平均值, 而在其他情况下, 则必须定义池大小。 Keras再次拥有自己的图层, 你可以在顺序模型中添加该图层:
from keras.models import Sequential
from keras import layers
embedding_dim = 50
model = Sequential()
model.add(layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=maxlen))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_9 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_5 (Glob (None, 50) 0
_________________________________________________________________
dense_15 (Dense) (None, 10) 510
_________________________________________________________________
dense_16 (Dense) (None, 1) 11
=================================================================
Total params: 87, 871
Trainable params: 87, 871
Non-trainable params: 0
_________________________________________________________________
培训程序不变:
history = model.fit(X_train, y_train, epochs=50, verbose=False, validation_data=(X_test, y_test), batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
结果如下:
Training Accuracy: 1.0000
Testing Accuracy: 0.8050

最大合并模型的准确性和损失
你已经可以在我们的模型中看到一些改进。接下来, 你将看到我们如何使用预训练的词嵌入, 以及它们如何帮助我们建立模型。
移除广告
使用预训练的词嵌入
我们刚刚看到了一个示例, 该示例将联合学习单词嵌入合并到我们要解决的较大模型中。
另一种选择是使用预先计算的嵌入空间, 该空间利用更大的语料库。通过简单地在大型文本语料库上训练单词嵌入, 可以预先计算单词嵌入。最流行的方法是Google开发的Word2Vec和斯坦福大学NLP集团开发的GloVe(全球单词表示向量)。
请注意, 这些是具有相同目标的不同方法。 Word2Vec通过使用神经网络实现了这一目标, 而GloVe通过共现矩阵并通过了矩阵分解实现了这一目标。在这两种情况下, 你都在处理降维问题, 但是Word2Vec更准确, 而GloVe的计算速度更快。
在本教程中, 你将了解如何使用斯坦福大学NLP集团的GloVe单词嵌入, 因为它们的大小比Google提供的Word2Vec单词嵌入更易于管理。继续并从此处下载6B(训练有60亿个单词)的单词嵌入(822 MB)。
你也可以在GloVe主页上找到其他单词嵌入。你可以在这里找到Google预先训练好的Word2Vec嵌入。如果你想训练自己的单词嵌入, 可以使用gensim Python软件包(使用Word2Vec进行计算)来高效地进行。有关如何执行此操作的更多详细信息, 请点击此处。
现在我们已经为你提供了覆盖, 你可以开始在模型中使用单词嵌入。你可以在下一个示例中看到如何加载嵌入矩阵。文件中的每一行均以单词开头, 后跟特定单词的嵌入向量。
这是一个大文件, 有400000行, 每行代表一个单词, 后跟作为浮点数流的向量。例如, 以下是第一行的前50个字符:
$ head -n 1 data/glove_word_embeddings/glove.6B.50d.txt | cut -c-50
the 0.418 0.24968 -0.41242 0.1217 0.34527 -0.04445
由于你不需要所有单词, 因此你可以只关注词汇表中的单词。由于词汇中的单词数量有限, 因此可以跳过预训练单词嵌入中的40000个单词中的大多数:
import numpy as np
def create_embedding_matrix(filepath, word_index, embedding_dim):
vocab_size = len(word_index) + 1 # Adding again 1 because of reserved 0 index
embedding_matrix = np.zeros((vocab_size, embedding_dim))
with open(filepath) as f:
for line in f:
word, *vector = line.split()
if word in word_index:
idx = word_index[word]
embedding_matrix[idx] = np.array(
vector, dtype=np.float32)[:embedding_dim]
return embedding_matrix
你现在可以使用此函数来检索嵌入矩阵:
>>>
>>> embedding_dim = 50
>>> embedding_matrix = create_embedding_matrix(
... 'data/glove_word_embeddings/glove.6B.50d.txt', ... tokenizer.word_index, embedding_dim)
精彩!现在, 你可以在训练中使用嵌入矩阵了。让我们继续使用先前的网络进行全局最大池化, 看看是否可以改进此模型。当你使用预训练词嵌入时, 你可以选择在训练期间更新嵌入, 还是仅使用结果嵌入向量。
首先, 让我们快速看一下有多少个嵌入向量非零:
>>>
>>> nonzero_elements = np.count_nonzero(np.count_nonzero(embedding_matrix, axis=1))
>>> nonzero_elements / vocab_size
0.9507727532913566
这意味着预训练模型覆盖了95.1%的词汇, 这很好地覆盖了我们的词汇。让我们看一下使用GlobalMaxPool1D层时的性能:
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim, weights=[embedding_matrix], input_length=maxlen, trainable=False))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_10 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_6 (Glob (None, 50) 0
_________________________________________________________________
dense_17 (Dense) (None, 10) 510
_________________________________________________________________
dense_18 (Dense) (None, 1) 11
=================================================================
Total params: 87, 871
Trainable params: 521
Non-trainable params: 87, 350
_________________________________________________________________
history = model.fit(X_train, y_train, epochs=50, verbose=False, validation_data=(X_test, y_test), batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
结果如下:
Training Accuracy: 0.7500
Testing Accuracy: 0.6950

未经训练的词嵌入的准确性和损失
由于不对单词嵌入进行额外的培训, 因此期望它会更低。现在让我们看看如果我们允许通过使用trainable = True对嵌入进行训练, 则效果如何:
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim, weights=[embedding_matrix], input_length=maxlen, trainable=True))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_11 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_7 (Glob (None, 50) 0
_________________________________________________________________
dense_19 (Dense) (None, 10) 510
_________________________________________________________________
dense_20 (Dense) (None, 1) 11
=================================================================
Total params: 87, 871
Trainable params: 87, 871
Non-trainable params: 0
_________________________________________________________________
history = model.fit(X_train, y_train, epochs=50, verbose=False, validation_data=(X_test, y_test), batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
结果如下:
Training Accuracy: 1.0000
Testing Accuracy: 0.8250

预训练词嵌入的准确性和损失
你会看到, 允许对嵌入进行训练是最有效的。处理大型训练集时, 它可以比没有训练集时更快地提高训练过程。就我们而言, 这似乎有帮助, 但作用不大。这不一定是因为预训练的单词嵌入。
现在是时候集中精力研究更高级的神经网络模型, 以查看是否有可能对模型进行增强并使其具有优于先前模型的优势。
移除广告
卷积神经网络(CNN)
卷积神经网络(也称为卷积网络)是近年来机器学习中最令人兴奋的发展之一。
通过能够从图像中提取特征并将其用于神经网络, 他们彻底改变了图像分类和计算机视觉。使它们在图像处理中有用的属性使它们也便于进行序列处理。你可以将CNN想象成能够检测特定模式的专用神经网络。
如果这只是另一个神经网络, 它与你先前学到的有什么区别?
CNN具有称为卷积层的隐藏层。当你想到图像时, 计算机必须处理二维数字矩阵, 因此你需要某种方法来检测该矩阵中的特征。这些卷积层能够检测边缘, 拐角和其他种类的纹理, 这使其成为一种特殊的工具。卷积层由多个滤镜组成, 这些滤镜在图像上滑动并能够检测特定特征。
这是技术的核心, 即卷积的数学过程。对于每个卷积层, 网络都能够检测到更复杂的模式。在Chris Olah的功能可视化中, 你可以直观地了解这些功能的外观。
当处理诸如文本之类的顺序数据时, 可以使用一维卷积, 但是其思想和应用程序保持不变。你仍然希望选择序列中的模式, 这些模式随着每个添加的卷积层变得越来越复杂。
在下图中, 你可以看到这种卷积如何工作。首先从获取具有过滤器内核大小的输入要素的补丁开始。使用此补丁, 你可以得到过滤器权重乘以的点积。一维卷积不变于翻译, 这意味着可以在不同位置识别某些序列。这对于文本中的某些模式可能会有所帮助:

1D卷积(
图片来源
)
现在, 让我们看看如何在Keras中使用此网络。 Keras再次提供了各种卷积层, 你可以将其用于此任务。你需要的图层是Conv1D图层。该层再次具有各种参数可供选择。现在, 你感兴趣的是过滤器的数量, 内核大小和激活功能。你可以在Embedding层和GlobalMaxPool1D层之间添加此层:
embedding_dim = 100
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen))
model.add(layers.Conv1D(128, 5, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_13 (Embedding) (None, 100, 100) 174700
_________________________________________________________________
conv1d_2 (Conv1D) (None, 96, 128) 64128
_________________________________________________________________
global_max_pooling1d_9 (Glob (None, 128) 0
_________________________________________________________________
dense_23 (Dense) (None, 10) 1290
_________________________________________________________________
dense_24 (Dense) (None, 1) 11
=================================================================
Total params: 240, 129
Trainable params: 240, 129
Non-trainable params: 0
_________________________________________________________________
history = model.fit(X_train, y_train, epochs=10, verbose=False, validation_data=(X_test, y_test), batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
结果如下:
Training Accuracy: 1.0000
Testing Accuracy: 0.7700

卷积神经网络的精度和损失
你会发现, 使用此数据集要克服80%的准确性似乎是一个艰巨的障碍, 而且CNN可能配置不完善。出现这种停滞的原因可能是:
- 培训样本不足
- 你的数据不能很好地概括
- 缺少对调整超参数的关注
CNN可以在大型训练集上发挥最好的作用, 在这种训练集下, 他们可以找到无法进行逻辑回归等简单模型的概括。
移除广告
超参数优化
深度学习和使用神经网络的关键步骤之一是超参数优化。
正如你在到目前为止使用的模型中所看到的那样, 即使使用简单的模型, 你也需要大量参数来进行调整和选择。这些参数称为超参数。这是机器学习中最耗时的部分, 可惜的是还没有一个万能的解决方案。
当你看一下Kaggle上的比赛时, Kaggle是与其他数据科学家同行竞争的最大场所之一, 你会发现许多获胜的团队和模型都经过了大量的调整和试验, 直到达到最佳状态。因此, 当遇到困难并达到平稳状态时不要气get, 而要考虑可以优化模型或数据的方式。
超参数优化的一种流行方法是网格搜索。该方法的作用是获取参数列表, 并使用可以找到的每个参数组合运行模型。这是最彻底的方法, 也是最繁琐的计算方法。另一种常见的方式是随机搜索, 你将在此处看到它的作用, 它只是采用参数的随机组合。
为了对Keras应用随机搜索, 你将需要使用KerasClassifier, 它用作scikit-learn API的包装。有了这个包装器, 你就可以使用scikit-learn提供的各种工具, 例如交叉验证。你需要的类是RandomizedSearchCV, 该类通过交叉验证实现随机搜索。交叉验证是一种验证模型并获取整个数据集并将其分为多个测试和培训数据集的方法。
有多种类型的交叉验证。一种类型是k-fold交叉验证, 你将在本示例中看到该交叉验证。在这种类型中, 数据集被划分为k个相等大小的集, 其中一组用于测试, 其余部分用于训练。这使你可以运行k次不同的运行, 其中每个分区曾经用作测试集。因此, k越高, 模型评估越准确, 但每个测试集越小。
KerasClassifier的第一步是拥有一个创建Keras模型的函数。我们将使用先前的模型, 但是我们将允许为超参数优化设置各种参数:
def create_model(num_filters, kernel_size, vocab_size, embedding_dim, maxlen):
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen))
model.add(layers.Conv1D(num_filters, kernel_size, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
接下来, 你要定义要在训练中使用的参数网格。它由一个字典组成, 每个参数的名称与上一个函数中的名称相同。网格上的空格数为3 * 3 * 1 * 1 * 1, 其中每个数字都是给定参数的不同选择的数目。
你可以看到它如何很快地增加计算量, 但是幸运的是, 网格搜索和随机搜索都令人尴尬地是并行的, 并且这些类带有n_jobs参数, 可让你并行测试网格空间。使用以下字典初始化参数网格:
param_grid = dict(num_filters=[32, 64, 128], kernel_size=[3, 5, 7], vocab_size=[5000], embedding_dim=[50], maxlen=[100])
现在你已经准备好开始运行随机搜索。在此示例中, 我们遍历每个数据集, 然后你要以与以前相同的方式预处理数据。之后, 你将使用上一个函数并将其添加到KerasClassifier包装器类中, 其中包括时期数。
然后, 将所得的实例和参数网格用作RandomSearchCV类中的估计量。另外, 你可以在k折交叉验证中选择折的数量, 在本例中为4。除了RandomSearchCV和KerasClassifier之外, 我还添加了一些处理评估的代码:
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import RandomizedSearchCV
# Main settings
epochs = 20
embedding_dim = 50
maxlen = 100
output_file = 'data/output.txt'
# Run grid search for each source (yelp, amazon, imdb)
for source, frame in df.groupby('source'):
print('Running grid search for data set :', source)
sentences = df['sentence'].values
y = df['label'].values
# Train-test split
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
# Tokenize words
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(sentences_train)
X_train = tokenizer.texts_to_sequences(sentences_train)
X_test = tokenizer.texts_to_sequences(sentences_test)
# Adding 1 because of reserved 0 index
vocab_size = len(tokenizer.word_index) + 1
# Pad sequences with zeros
X_train = pad_sequences(X_train, padding='post', maxlen=maxlen)
X_test = pad_sequences(X_test, padding='post', maxlen=maxlen)
# Parameter grid for grid search
param_grid = dict(num_filters=[32, 64, 128], kernel_size=[3, 5, 7], vocab_size=[vocab_size], embedding_dim=[embedding_dim], maxlen=[maxlen])
model = KerasClassifier(build_fn=create_model, epochs=epochs, batch_size=10, verbose=False)
grid = RandomizedSearchCV(estimator=model, param_distributions=param_grid, cv=4, verbose=1, n_iter=5)
grid_result = grid.fit(X_train, y_train)
# Evaluate testing set
test_accuracy = grid.score(X_test, y_test)
# Save and evaluate results
prompt = input(f'finished {source}; write to file and proceed? [y/n]')
if prompt.lower() not in {'y', 'true', 'yes'}:
break
with open(output_file, 'a') as f:
s = ('Running {} data set\nBest Accuracy : '
'{:.4f}\n{}\nTest Accuracy : {:.4f}\n\n')
output_string = s.format(
source, grid_result.best_score_, grid_result.best_params_, test_accuracy)
print(output_string)
f.write(output_string)
这需要一段时间, 这是一个绝佳的机会, 可以出门呼吸新鲜空气, 甚至是远足, 这取决于你要运行多少个模型。让我们看看我们有什么:
Running amazon data set
Best Accuracy : 0.8122
{'vocab_size': 4603, 'num_filters': 64, 'maxlen': 100, 'kernel_size': 5, 'embedding_dim': 50}
Test Accuracy : 0.8457
Running imdb data set
Best Accuracy : 0.8161
{'vocab_size': 4603, 'num_filters': 128, 'maxlen': 100, 'kernel_size': 5, 'embedding_dim': 50}
Test Accuracy : 0.8210
Running yelp data set
Best Accuracy : 0.8127
{'vocab_size': 4603, 'num_filters': 64, 'maxlen': 100, 'kernel_size': 7, 'embedding_dim': 50}
Test Accuracy : 0.8384
有趣!由于某种原因, 测试准确性高于训练准确性, 这可能是因为在交叉验证期间分数存在较大差异。我们可以看到, 我们仍然无法突破可怕的80%, 对于给定大小的数据, 这似乎是自然的限制。请记住, 我们的数据集很小, 而卷积神经网络往往在大数据集上表现最佳。
CV的另一种方法是嵌套的交叉验证(此处显示), 当还需要优化超参数时使用该方法。之所以使用它, 是因为生成的非嵌套CV模型对数据集有偏见, 这可能会导致过于乐观的得分。你会看到, 当像在上一个示例中一样进行超参数优化时, 我们正在为该特定训练集选择最佳的超参数, 但这并不意味着这些超参数可以得到最佳的概括。
结论
到此为止:你已经了解了如何使用Keras进行文本分类, 并且我们已经从具有逻辑回归的词袋模型转变为导致卷积神经网络的越来越先进的方法。
你现在应该熟悉词嵌入, 它们为何有用, 以及如何在训练中使用预先训练的词嵌入。你还学习了如何使用神经网络, 以及如何使用超参数优化从模型中挤出更多性能。
递归神经网络, 更具体地说是LSTM和GRU, 是我们在这里还没有涉及的一个大话题。这些是其他强大且流行的工具, 可用于处理文本或时间序列等顺序数据。目前, 神经网络中还有其他有趣的发展, 它们正在引起人们的关注, 这些都在积极研究中, 并且由于LSTM往往会占用大量计算资源, 因此似乎是一个有希望的下一步。
你现在已经了解了自然语言处理中的关键基石, 可以将其用于各种文本分类。情感分析是最突出的例子, 但这包括许多其他应用程序, 例如:
- 电子邮件中的垃圾邮件检测
- 自动标记文字
- 具有预定义主题的新闻文章的分类
你可以像本教程一样使用此知识以及在高级项目中训练的模型, 使用Kibana和Elasticsearch对连续的Twitter数据流进行情感分析。你还可以将情感分析或文本分类与语音识别相结合, 就像在本手册中使用Python中的SpeechRecognition库一样。
移除广告
进一步阅读
如果你想深入研究本文中的各个主题, 可以查看以下链接:
- AI研究人员声称机器学习是炼金术
- 人工智能何时会超越人类的表现?来自AI专家的证据
- 硬代码示例
- 深度学习, NLP和表示
- Word2Vec纸
- 手套纸
评论前必须登录!
注册