 srcmini
srcmini在Spark单词计数示例中, 我们发现每个单词在特定文件中存在的频率。在这里, 我们使用Scala语言执行Spark操作。
执行Spark单词计数示例的步骤
在此示例中, 我们找到并显示每个单词的出现次数。
- 在本地计算机上创建一个文本文件, 然后在其中写入一些文本。
$ nano sparkdata.txt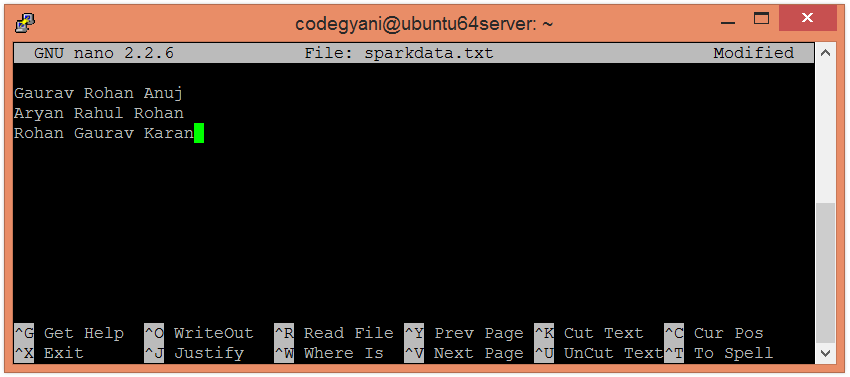
- 检查在sparkdata.txt文件中编写的文本。
$ cat sparkdata.txt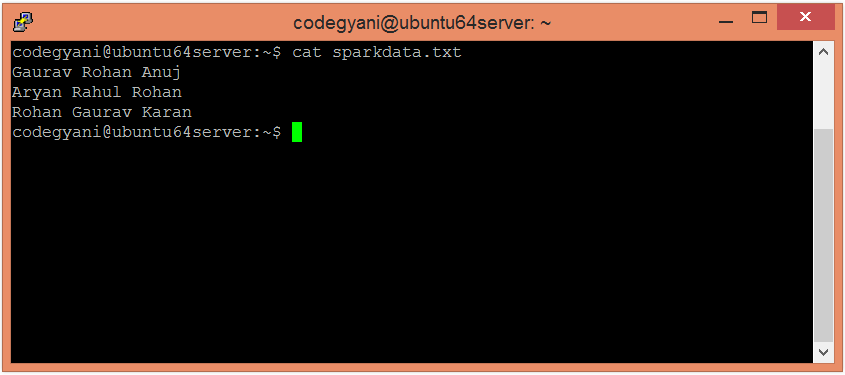
- 在HDFS中创建一个目录, 用于保存文本文件。
$ hdfs dfs -mkdir /spark- 在指定目录的HDFS上上传sparkdata.txt文件。
$ hdfs dfs -put /home/codegyani/sparkdata.txt /spark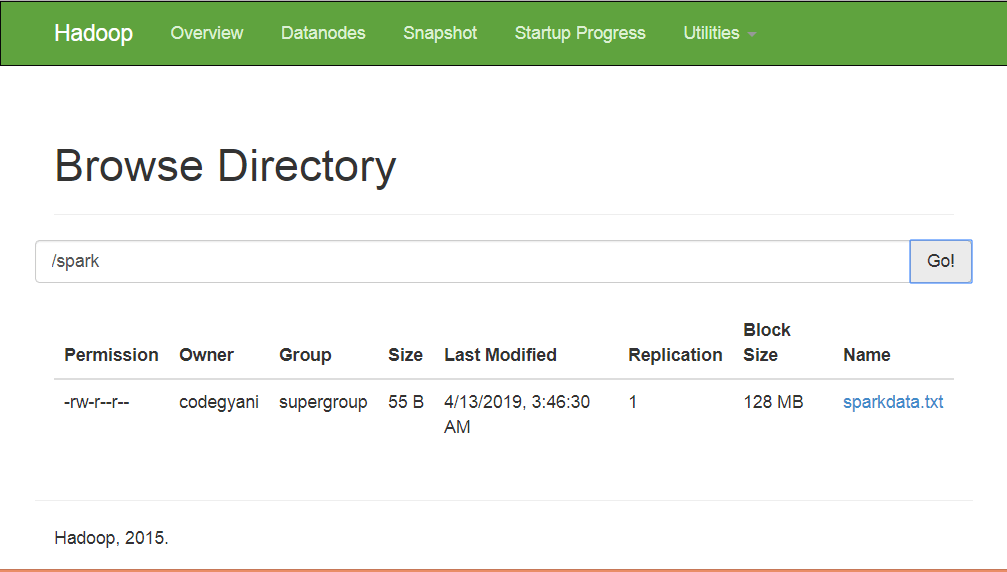
- 现在, 按照以下命令在Scala模式下打开火花。
$ spark-shell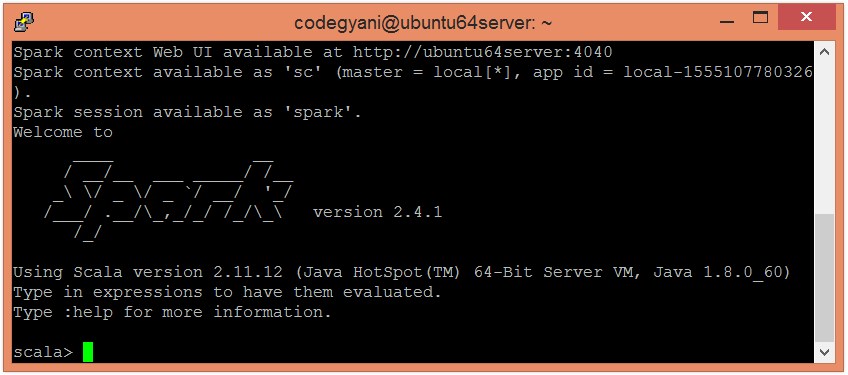
- 让我们使用以下命令创建一个RDD。
scala> val data=sc.textFile("sparkdata.txt")在这里, 传递包含数据的任何文件名。
- 现在, 我们可以使用以下命令读取生成的结果。
scala> data.collect;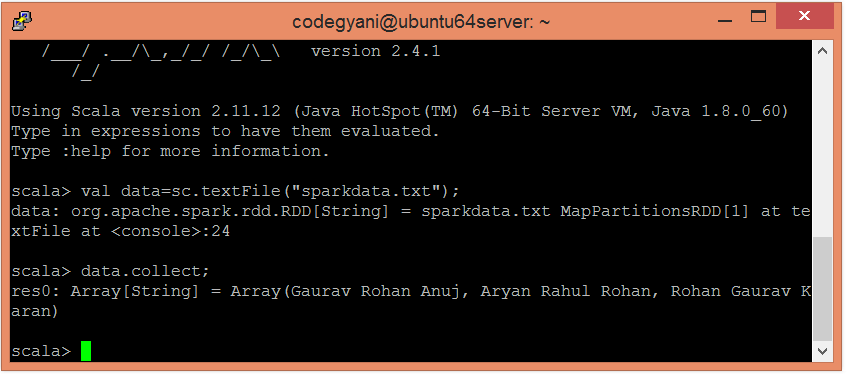
- 在这里, 我们使用以下命令以单个单词的形式拆分现有数据。
scala> val splitdata = data.flatMap(line => line.split(" "));- 现在, 我们可以使用以下命令读取生成的结果。
scala> splitdata.collect;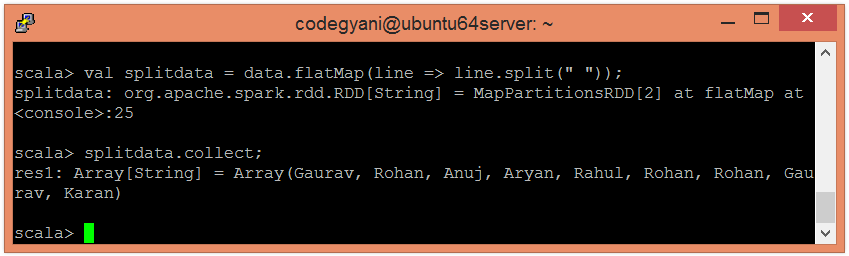
- 现在, 执行地图操作。
scala> val mapdata = splitdata.map(word => (word, 1));在这里, 我们为每个单词分配一个值1。
- 现在, 我们可以使用以下命令读取生成的结果。
scala> mapdata.collect;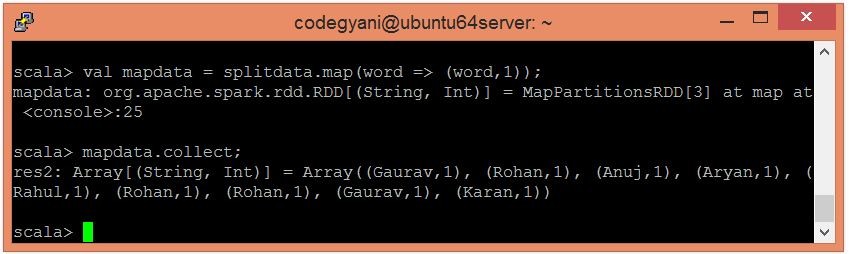
- 现在, 执行reduce操作
scala> val reducedata = mapdata.reduceByKey(_+_);在这里, 我们总结了生成的数据。
- 现在, 我们可以使用以下命令读取生成的结果。
scala> reducedata.collect;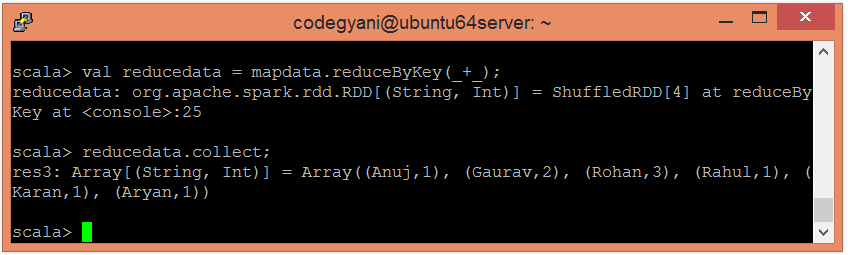
在这里, 我们得到了期望的输出。
评论前必须登录!
注册