 srcmini
srcmini本文概述
聚类分析将数据分为几组, 通常称为聚类。如果有意义的组是目标, 那么集群将捕获数据的一般信息。某些时间集群分析只是用于其他目的的有用初始阶段, 例如数据汇总。就理解或效用而言, 聚类分析在诸如生物学, 心理学, 统计学, 模式识别机器学习和挖掘等广泛领域中一直发挥着重要作用。
什么是聚类分析?
聚类分析是组的数据对象, 主要取决于数据中找到的信息。它定义了对象及其关系。一个组内的对象的目标与其他组的对象相似或不同。
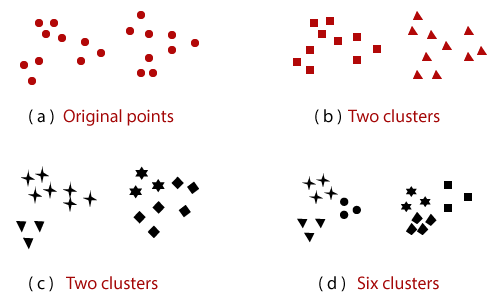
给定的图1说明了在同一点集合上进行聚类的不同方式。
在各种应用中, 没有简要定义集群的概念。为了更好地理解选择组的挑战, 图1展示了二十个点以及将它们分为几类的三种不同方式。标记的设计显示了群集成员。这些图分别将数据分为两个部分和六个部分。将两个更重要的群集中的每个群集划分为三个子群集可能是人类视觉系统的产物。声明来自四个聚类的点可能不合逻辑。该图表示群集的含义不正确。集群的最佳定义取决于数据的性质和结果。
聚类分析类似于用于将数据对象划分为组的其他方法。例如, 聚类可以视为分类的一种形式。它使用分类构造对象的标签, 即, 使用从具有已知类标签的对象开发的模型, 可以为新的未标签对象提供类标签。因此, 聚类分析有时被定义为无监督分类。如果在没有数据挖掘能力的情况下使用分类一词, 那么它通常是指监督分类。
术语分割和分区通常用作聚类的同义词。这些术语通常用于超出聚类分析传统界限的技术。例如, 术语“分区”通常用于与将图分成子图并且未连接到“聚类”的技术相关联。分段通常使用简单的方法将数据分为几组。例如, 可以根据像素频率和颜色将图像分为多个部分, 也可以根据人们的年收入将人们分为不同的组。但是, 图划分和市场细分中的一些工作与聚类分析有关。
不同类型的聚类
整个集群通常称为集群。在这里, 我们区分了不同种类的聚类, 例如, 分层(嵌套)与分区(未嵌套), 互斥与重叠与模糊以及完全与部分聚类。
- 分层与分区
在各种类型的聚类中最经常讨论的不同特征是聚类集是嵌套的还是未嵌套的, 或者是使用更传统的术语, 分区还是分层的。分区群集通常是将一组数据对象分配到不重叠的子集(群集)中, 以便每个数据对象恰好在一个子集中。
如果我们允许集群具有子集群, 那么我们将获得分层集群, 这是一组嵌套的集群, 它们被组织为一棵树。树中的每个节点(集群)(非叶节点)是其子集群的关联, 树的根是集群, 包括所有对象。通常, 树的叶子是各个数据对象的各个群集。如果我们允许集群嵌套, 则图1(a)的一个澄清之处在于它具有两个子集群, 图1(b)对此进行了说明, 每个子集群都有三个子集群, 如图1(d)所示。当按特定顺序获取群集时, 它们也出现在图1(a-d)中, 也来自分层(嵌套)群集, 每个级别分别有1、2、4和6个群集。最后, 分层聚类可以看作是分区聚类的一种安排, 并且可以通过采用该序列的任何成员来获取分区聚类, 这意味着通过在特定级别切割层次树。
- 排他, 重叠, 模糊
图中出现的“群集”是唯一的, 因为它们将每个对象的责任分配给单个群集。在许多情况下, 可以在多个群集中合理地设置一个点, 而通过非排他群集可以更好地解决这些情况。一般而言, 重叠或非排他的聚类用于反映一个对象可以一起属于多个组(类)的事实。例如, 公司里的人既可以是实习生, 也可以是公司的雇员。如果对象位于两个或多个然后两个群集之间, 并且可以合理地分配给这些群集中的任何一个, 通常也可以使用非排他性群集。考虑两个聚类之间的某个点, 而不是将对象完全随机地分配给单个聚类。它被放置在所有群集中, 成为“同等良好”的群集。
在模糊聚类中, 每个对象都属于具有权属权重介于0和1之间的每个聚类。换句话说, 聚类被视为模糊集。数学上, 模糊集定义为其中一个对象与权重在0到1之间的任何集相关联的模糊集。在模糊聚类中, 我们通常设置附加约束, 并且每个对象的权重之和必须相等到1。类似, 概率聚类系统计算每个点属于一个聚类的概率, 并且这些概率之和必须为1。由于任何对象的隶属权重或概率之和为1, 因此模糊或概率聚类无法解决实际的多类情况。
完全与部分
完整的群集将每个对象分配给群集, 而部分群集则不会。部分聚类的灵感在于数据集中的一些对象可能不属于不同的组。在大多数情况下, 数据集中的对象可能会产生异常值, 噪声或“无用的背景”。例如, 某些新闻头条新闻可能具有一个共同的主题, 例如“全球工业生产下降1.1%”, 而不同的新闻则更为频繁或独一无二。因此, 要找到上个月故事中的重要主题, 我们可能只需要搜索与一个共同主题紧密相关的文档簇。在其他情况下, 则需要完整的对象群集。例如, 利用群集来整理文档进行浏览的应用程序需要确保可以浏览所有文档。
不同类型的集群
将地址聚类以发现有用的对象组(集群), 其中数据分析的目标表征实用程序。当然, 在实践中, 有很多关于集群的概念可以证明其实用性。为了直观地显示这些类型的聚类之间的差异, 我们利用二维点, 如图所示, 此处描述的聚类类型对于不同种类的数据同样有效。
- 分离良好的群集
群集是一组对象, 其中每个对象与群集中的每个其他对象更接近或更相似。有时会使用一个限制来表示群集中的所有对象必须足够接近或彼此相似。仅当数据包含彼此相距很远的自然簇时, 才满足簇的定义。该图说明了一个良好分离的群集的示例, 该群集包含二维空间中的两个点。分隔良好的簇不需要为球形, 但可以具有任何形状。

- 基于原型的集群
群集是一组对象, 其中每个对象与表征该群集的原型与其他任何群集的原型更接近或更相似。对于具有连续特征的数据, 聚类的原型通常是质心。它表示质心不重要时群集中所有点的平均值(均值)。例如, 当数据具有确定的特征时, 原型通常是类聚体, 它是聚类中最具代表性的点。对于某些类型的数据, 可以将模型视为最中心点, 在此类示例中, 我们通常将基于原型的集群称为基于中心的集群。就像任何人所期望的那样, 此类簇往往是球形的。该图说明了基于中心的群集的示例。

- 基于图的集群
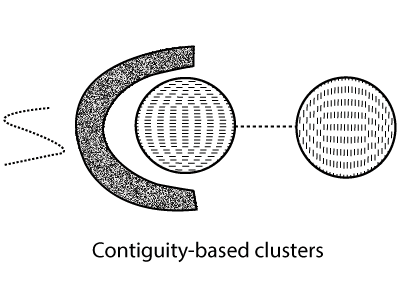
如果将数据描述为图形, 其中节点是对象, 则可以将集群描述为连接的组件。它是一组相互关联的对象, 但与该组之外的对象没有关联。基于图的聚类的一个重要示例是基于连续性的聚类, 其中当两个对象之间的距离指定为指定的距离时, 两个对象将被关联。这表明基于连续性的群集中的每个对象都与群集中的其他对象相同。图显示了此类二维点群集的示例。当群集无法预测或相互缠绕时, 群集的含义很有用, 但是当出现噪音时可能会遇到困难。如图中的两个圆形簇所示。点的一点扩展可以连接两个不同的集群。
其他种类的基于图的群集也是可能的。一种这样的方式将集群描述为集团。 “集团”是图中彼此完全关联的一组节点。特别是, 我们根据对象之间的距离添加对象之间的连接。当一组对象形成一个集团时, 就会生成一个簇。就像基于原型的群集一样, 此类群集通常是球形的。
- 基于密度的集群
群集是被低密度区域包围的对象的压缩域。如图所示, 这两个球状星团没有合并, 因为它们之间的桥梁逐渐淡化为噪音。类似地, 图中出现的曲线消失在噪声中, 并且在图中未形成簇。它还消失在噪音中, 没有形成图中所示的簇。当群集不规则且相互缠绕, 并且存在噪音和异常值时, 通常会使用基于密度的群集定义。另一方面, 群集的基于连续性的定义对于Figure的数据将无法正常工作。由于噪声倾向于在群集之间形成网络。

- 共享财产或概念集群

我们可以将集群描述为一组提供某些属性的对象。基于中心的群集中的对象共享以下属性:它们都最接近相似的质心或质心。但是, 共享财产方法还包含了新类型的群集。考虑图中给出的集群。三角形区域(群集)紧挨着矩形区域, 并且有两个相互缠绕的圆(群集)。在这两种情况下, 聚类算法都需要特定的聚类概念才能有效地识别这些聚类。发现此类群集的方法称为概念性群集。
评论前必须登录!
注册