 srcmini
srcmini本文概述
聚类是一种无监督的基于机器学习的算法, 该算法将一组数据点包含在聚类中, 从而使对象属于同一组。
群集有助于将数据分为几个子集。这些子集中的每个子集都包含彼此相似的数据, 这些子集称为簇。现在, 来自客户群的数据已被分为几类, 我们可以就谁认为最适合此产品做出明智的决定。
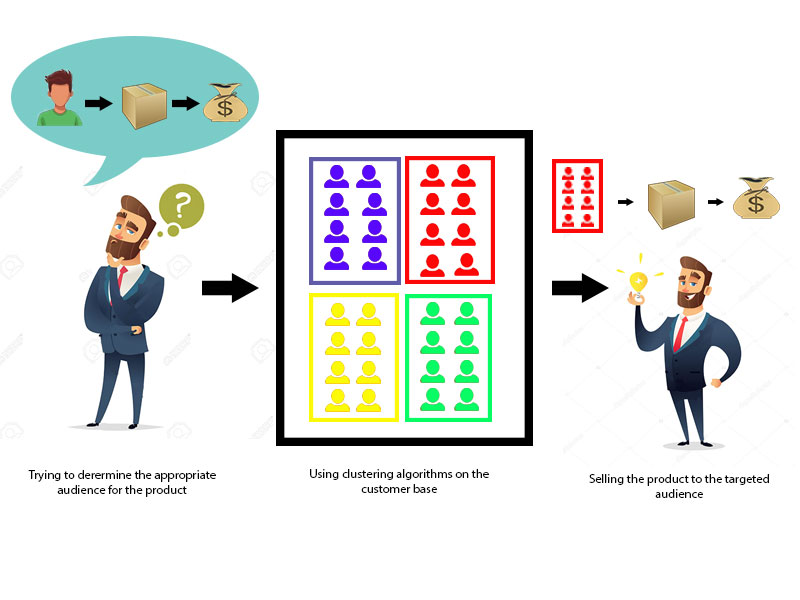
让我们通过一个例子来理解这一点, 假设我们是一名市场经理, 并且有一种诱人的新产品要出售。只要将产品卖给合适的人, 我们相信该产品将带来巨大的利润。那么, 如何从我们公司庞大的客户群中找出最适合该产品的人呢?
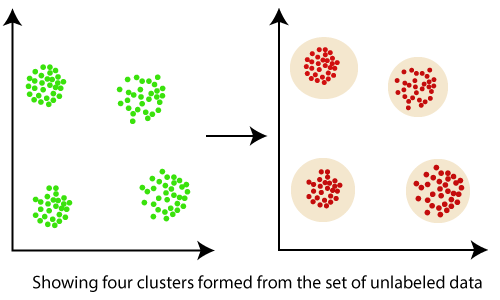
聚类属于无监督机器学习范畴, 是机器学习算法要解决的问题之一。
聚类仅利用输入数据来确定其输入数据中的模式, 异常或相似性。
一个好的聚类算法旨在获得以下集群:
- 群集内的相似度很高, 这意味着群集中存在的数据彼此相似。
- 集群间的相似性很低, 这意味着每个集群都拥有与其他数据不相似的数据。
什么是集群?
- 集群是相似对象的子集
- 对象的子集, 以使群集中两个对象中的任何一个之间的距离小于群集中任何对象与不在其内部的任何对象之间的距离。
- 具有较高密度的对象的多维空间的连接区域。
数据挖掘中的集群是什么?
- 聚类是将一组抽象对象转换为相似对象类的方法。
- 群集是一种将一组数据或对象划分为一组重要的子类(称为群集)的方法。
- 它可以帮助用户了解数据集中的结构或自然分组, 并可以用作独立工具来更好地了解数据分布, 也可以用作其他算法的预处理步骤
重要事项
- 群集的数据对象可以视为一组。
- 在进行聚类分析时, 我们首先将信息集分组。它基于数据相似性, 然后将级别分配给组。
- 过度分类的主要优点是它可以适应修改, 并且可以帮助区分出不同组的重要特征。
聚类分析在数据挖掘中的应用
- 在许多应用程序中, 聚类分析被广泛使用, 例如数据分析, 市场研究, 模式识别和图像处理。
- 它可以帮助营销人员根据购买模式在客户群中找到不同的群体。他们可以表征其客户群。
- 它有助于在Internet上分配文档以进行数据发现。
- 群集还用于跟踪应用程序, 例如检测信用卡欺诈。
- 作为数据挖掘功能, 聚类分析用作一种工具, 可深入了解数据分布, 以分析每个聚类的特征。
- 在生物学方面, 它可以用于确定植物和动物的分类学, 对具有相同功能的基因进行分类, 并深入了解种群固有的结构。
- 它有助于识别在地球观测数据库中使用的相似土地的区域, 并根据房屋类型, 价值和地理位置来识别城市中的房屋组。
为什么在数据挖掘中使用集群?
聚类分析由于其用途广泛而已成为数据挖掘中不断发展的问题。近年来, 各种数据聚类工具的出现以及它们在包括图像处理, 计算生物学, 移动通信, 医学和经济学在内的广泛应用中的广泛使用, 必须为这些算法的普及做出贡献。数据聚类算法的主要问题是它无法标准化。先进的算法可能会对一种类型的数据集产生最佳结果, 但对于其他类型的数据集却可能会失败或表现不佳。尽管已经做出了很多努力来标准化可以在所有情况下均能良好运行的算法, 但是到目前为止, 尚未取得明显的成就。到目前为止, 已经提出了许多聚类工具。但是, 每种算法都有其优点或缺点, 不能在所有实际情况下工作。
1.可扩展性:
聚类的可伸缩性意味着随着我们增加数据对象的数量, 执行聚类的时间应大致按算法的复杂性顺序扩展。例如, 如果执行K-均值聚类, 我们知道它是O(n), 其中n是数据中对象的数量。如果我们将数据对象的数量增加10倍, 则将它们聚类所需的时间也应大约增加10倍。这意味着应该存在线性关系。如果不是这种情况, 则说明我们的实施过程存在错误。
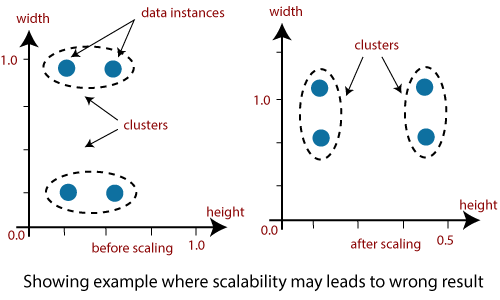
如果数据不可扩展, 则应可扩展, 否则我们将无法获得适当的结果。该图说明了可能导致错误结果的图形示例。
2.可解释性:
聚类的结果应该是可解释的, 可理解的和可用的。
3.发现具有属性形状的集群:
聚类算法应该能够找到任意形状的聚类。它们不应仅限于趋向于发现小尺寸球形簇的距离测量。
4.能够处理不同类型的属性:
算法应该能够应用于任何数据, 例如基于间隔(数字)的数据, 二进制数据和分类数据。
5.处理噪声数据的能力:
数据库包含嘈杂, 丢失或不正确的数据。很少有算法对此类数据敏感, 并且可能导致质量较差的簇。
6.高尺寸:
群集工具不仅应该能够处理高维数据空间, 而且还应该能够处理低维空间。
评论前必须登录!
注册