 srcmini
srcmini本文概述
二进制堆
Binary Heap是一个数组对象, 可以视为Complete Binary Tree。二叉树的每个节点对应于数组中的一个元素。
- 长度[A], 数组中的元素数
- Heap-Size [A], 数组A中存储的堆中的元素数。
树A [1]的根, 给出节点的索引“ i”, 该节点可以计算其父节点, 左子节点和右子节点的索引。
PARENT (i)
Return floor (i/2)
LEFT (i)
Return 2i
RIGHT (i)
Return 2i+1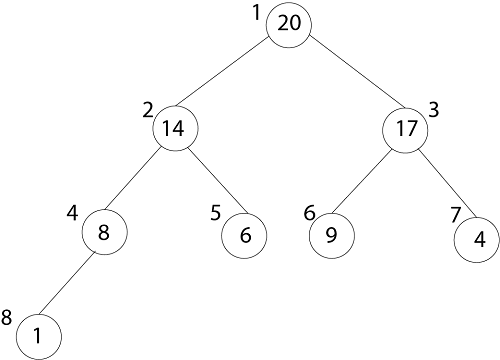
上图的数组表示如下:
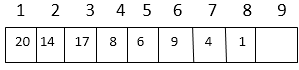
索引20为1
为了找到左孩子的索引, 我们计算1 * 2 = 2
这使我们(正确地)到达了14。
现在, 我们往右走, 所以我们计算2 * 2 + 1 = 5
这将我们(正确地)带到了6。
现在, 4的索引是7, 我们想转到父级, 所以我们计算7/2 = 3, 这使我们到了17。
堆属性
二进制堆可以分为最大堆或最小堆
1.最大堆:在二进制堆中, 对于除根以外的每个节点I, 该节点的值都大于或等于其最高子节点的值
A [PARENT (i) ≥A[i]因此, 堆中的最高元素存储在根目录中。以下是MAX-HEAP的示例
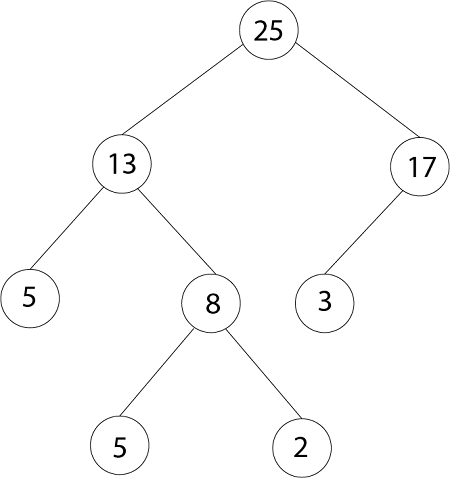
2. MIN-HEAP:在MIN-HEAP中, 节点的值小于或等于其最低子节点的值。
A [PARENT (i) ≤A[i]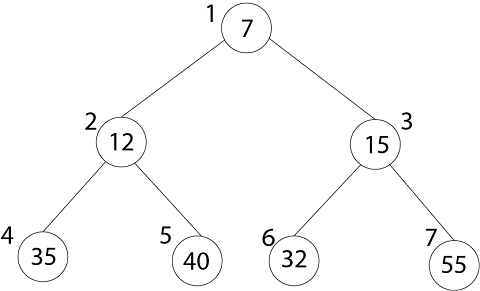
堆砌方法
1.维护堆属性:堆化是用于操纵堆数据结构的过程。给它一个数组A, 并给数组下标I。以A [i]的子节点为根的子树是堆, 但是节点A [i]本身可能会违反堆属性, 即A [i] <A [2i]或A [2i + 1]。 “堆化”过程操作以A [i]为根的树, 使其成为堆。
MAX-HEAPIFY (A, i)
1. l ← left [i]
2. r ← right [i]
3. if l≤ heap-size [A] and A[l] > A [i]
4. then largest ← l
5. Else largest ← i
6. If r≤ heap-size [A] and A [r] > A[largest]
7. Then largest ← r
8. If largest ≠ i
9. Then exchange A [i] A [largest]
10. MAX-HEAPIFY (A, largest)分析:
元素可以向上移动的最大电平为Θ(log n)电平。在每个级别上, 我们都对O(1)进行简单比较。因此, heapify的总时间为O(log n)。
建立一个堆
BUILDHEAP (array A, int n)
1 for i ← n/2 down to 1
2 do
3 HEAPIFY (A, i, n)堆排序算法
HEAP-SORT (A)
1. BUILD-MAX-HEAP (A)
2. For I ← length[A] down to Z
3. Do exchange A [1] ←→ A [i]
4. Heap-size [A] ← heap-size [A]-1
5. MAX-HEAPIFY (A, 1)分析:构建最大堆需要O(n)运行时间。堆排序算法调用“ Build Max-Heap”(构建最大堆), 这需要O(n)个时间, 而每个(n-1)个调用都将调用Max-heap来修复新堆。我们知道“ Max-Heapify”需要时间O(log n)
堆排序的总运行时间为O(n log n)。
示例:说明阵列上BUILD-MAX-HEAP的操作。
A = (5, 3, 17, 10, 84, 19, 6, 22, 9)解决方案:最初:
Heap-Size (A) =9, so first we call MAX-HEAPIFY (A, 4)
And I = 4.5= 4 to 1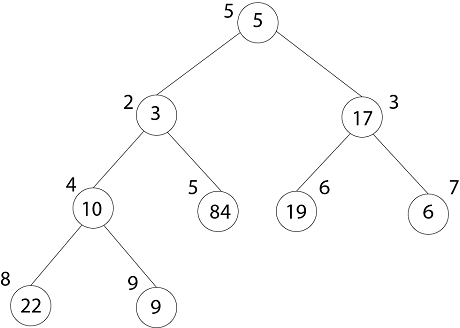
After MAX-HEAPIFY (A, 4) and i=4
L ← 8, r ← 9
l≤ heap-size[A] and A [l] >A [i]
8 ≤9 and 22>10
Then Largest ← 8
If r≤ heap-size [A] and A [r] > A [largest]
9≤9 and 9>22
If largest (8) ≠4
Then exchange A [4] ←→ A [8]
MAX-HEAPIFY (A, 8)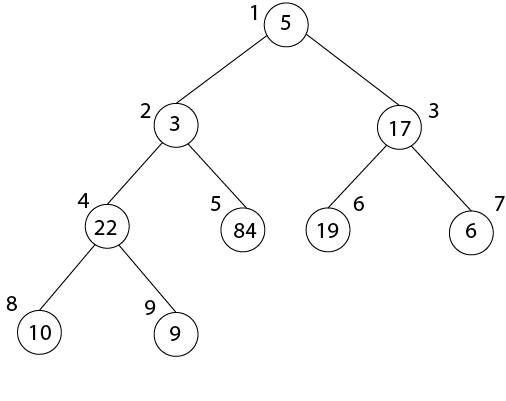
After MAX-HEAPIFY (A, 3) and i=3
l← 6, r ← 7
l≤ heap-size[A] and A [l] >A [i]
6≤ 9 and 19>17
Largest ← 6
If r≤ heap-size [A] and A [r] > A [largest]
7≤9 and 6>19
If largest (6) ≠3
Then Exchange A [3] ←→ A [6]
MAX-HEAPIFY (A, 6)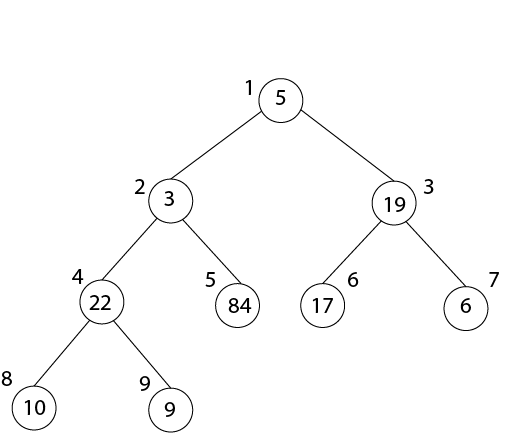
After MAX-HEAPIFY (A, 2) and i=2
l ← 4, r ← 5
l≤ heap-size[A] and A [l] >A [i]
4≤9 and 22>3
Largest ← 4
If r≤ heap-size [A] and A [r] > A [largest]
5≤9 and 84>22
Largest ← 5
If largest (4) ≠2
Then Exchange A [2] ←→ A [5]
MAX-HEAPIFY (A, 5)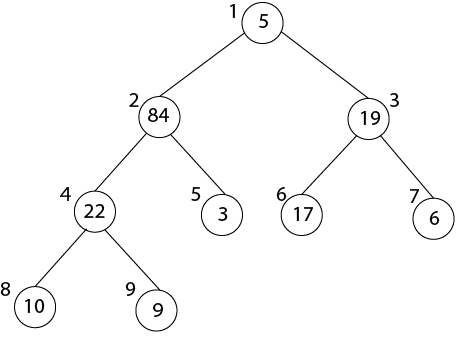
After MAX-HEAPIFY (A, 1) and i=1
l ← 2, r ← 3
l≤ heap-size[A] and A [l] >A [i]
2≤9 and 84>5
Largest ← 2
If r≤ heap-size [A] and A [r] > A [largest]
3≤9 and 19<84
If largest (2) ≠1
Then Exchange A [1] ←→ A [2]
MAX-HEAPIFY (A, 2)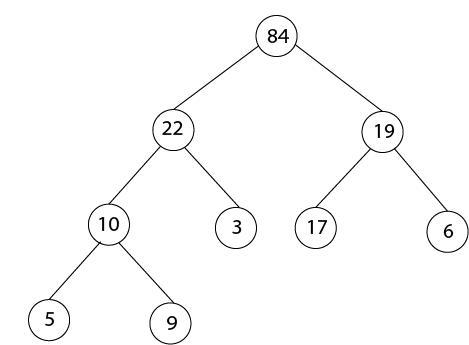
优先队列
与堆一样, 优先级队列以两种形式出现:最大优先级队列和最小优先级队列。
优先级队列是一种数据结构, 用于维护元素S的集合, 每个元素具有称为键的组合值。最大优先级队列指导以下操作:
INSERT(S, x):将元素x插入到集合S中, 与操作S =S∪[x]成比例。
MAXIMUM(S)返回具有最高键的S元素。
EXTRACT-MAX(S)删除并返回具有最高键的S元素。
INCREASE-KEY(S, x, k)将元素x的键值增加到新值k, 该值至少与x的当前键值一样大。
让我们讨论如何实现最大优先级队列的操作。过程HEAP-MAXIMUM考虑θ(1)时间的MAXIMUM操作。
最大堆(A)
1.返回A [1]
过程HEAP-EXTRACT-MAX实现EXTRACT-MAX操作。它类似于Heap-Sort过程的for循环。
HEAP-EXTRACT-MAX (A)
1 if A. heap-size < 1
2 error "heap underflow"
3 max ← A [1]
4 A [1] ← A [heap-size [A]]
5 heap-size [A] ← heap-size [A]-1
6 MAX-HEAPIFY (A, 1)
7 return max过程HEAP-INCREASE-KEY实现了INCREASE-KEY操作。数组中的索引i标识了我们希望增加其键的优先级队列元素。
HEAP-INCREASE-KEY.A, i, key)
1 if key < A[i]
2 errors "new key is smaller than current key"
3 A[i] = key
4 while i>1 and A [Parent (i)] < A[i]
5 exchange A [i] with A [Parent (i)]
6 i =Parent [i]HEAP-INCREASE-KEY在n元素堆上的运行时间为O(日志n), 因为从第3行中更新的节点到根的跟踪路径的长度为O(log n)。
MAX-HEAP-INSERT过程实现INSERT操作。它以要插入到最大堆A中的新项目的键作为输入。该过程首先通过将键为-∞的新叶计算到树上来扩展最大堆。然后, 它调用HEAP-INCREASE-KEY将此新节点的密钥设置为其正确的值并维护max-heap属性
MAX-HEAP-INSERT (A, key)
1 A. heap-size = A. heap-size + 1
2 A [A. heap-size] = - ∞
3 HEAP-INCREASE-KEY (A, A. heap-size, key)在n元素堆上MAX-HEAP-INSERT的运行时间为O(日志n)。
示例:说明堆上的HEAP-EXTRACT-MAX的操作
A= (15, 13, 9, 5, 12, 8, 7, 4, 0, 6, 2, 1)图:HEAP-INCREASE-KEY的操作

无花果(a)
在此图中, 带有索引为“ i”的节点的最大堆阴影很大

无花果(b)
在此图中, 此节点的密钥增加到15。
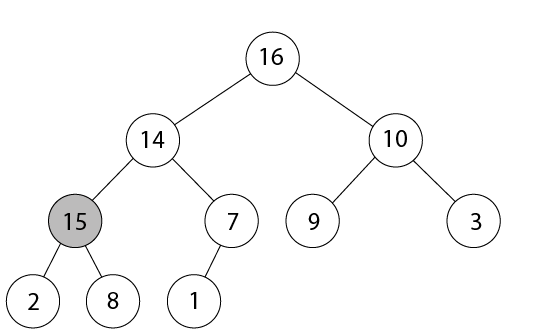
无花果(c)
在第4-6行的while循环的一次迭代之后, 该节点及其父节点交换了密钥, 索引i移至父节点。

无花果(d)
经过while循环再迭代一次后, 最大堆, 最大堆属性A [PARENT(i)≥A(i)]现在成立, 过程终止。
堆删除
堆删除(A, i)是从堆A中删除节点’i’中的项目的过程, 对于N元素最大堆, HEAP-DELETE运行时间为O(log n)。
HEAP-DELETE (A, i)
1. A [i] ← A [heap-size [A]]
2. Heap-size [A] ← heap-size [A]-1
3. MAX-HEAPIFY (A, i)
评论前必须登录!
注册